Makina Blog
Fabriquer un raster de densité à partir d'un nuage de points avec PostGIS
Cet article présente une procédure de manipulation de données SIG avec PostGIS afin de fabriquer une couche raster de densité.
Bonjour à toutes et à tous, et bienvenue dans cet article un peu particulier puisqu'il prend la forme d'un mini-atelier. Ensemble, nous partirons des données OpenStreeMap (OSM) de la Belgique afin de calculer une couche raster de densité de ces nœuds.
Une donnée raster est une donnée discrète, elle est notamment définie par un pas (ou résolution) qui indique sa précision. Nous trouvons aussi des données vectorielles, qui elles sont continues.
Voici le résultat :
De façon à suivre cet atelier, vous aurez besoin d'avoir des connaissances de base en SQL et en manipulation de données géographiques avec PostGIS. Nous allons écrire des requêtes assez complexes, et je pars du principe que vous êtes à l'aise avec les requêtes SQL contenant des jointures ainsi que les Common Table Expressions (CTE). Pour la partie PostGIS, à partir du moment où vous êtes à l'aise avec la notion de projection (srid, etc.), j'explique toutes les fonctions que j'utilise.
Vous aurez aussi besoin d'avoir accès à une base de données PostgreSQL (version 13 minimum) avec PostGIS d'installé (v3.3 minimum), ainsi que l'extension postgis_raster. Cet article est écrit et testé depuis une machine Linux, mais je pense que vous devriez pouvoir vous en sortir sous Windows avec quelques adaptations mineures.
Tous les scripts SQL ainsi qu'une stack docker-compose permettant de suivre l'atelier sont disponibles dans ce repo github.
Chargement des données OSM en base de données
Dans cette partie, nous allons importer les données d'OSM en base.
Nous allons partir des données OSM de la Belgique, téléchargeable ici. Le fichier fait environ 550 Mo. Une fois les données téléchargées, chargez-les avec osm2pgsql :
# cette commande prend environ 7 mn à charger les données dans une BDD Postgres en local
osm2pgsql --host localhost --port 9950 --username postgres --password --database density_raster_demo --input-reader pbf ./belgium-latest.osm.pbf
Vous devriez avoir les tables suivantes dans le schéma public :
planet_osm_lineplanet_osm_pointplanet_osm_polygon
SELECT COUNT(*) FROM planet_osm_line; -- 1 905 064 lignes
Fabrication du nuage de points
Dans cette partie, nous allons retravailler les données d'OSM pour fabriquer un nuage de points global à la Belgique.
Étant donné que nous voulons travailler sur un nuage de points, nous allons transformer les lignes et les polygones en points en utilisant la fonction ST_DumpPoints de PostGIS. Cette fonction extrait les points composant un polygone ou une ligne.
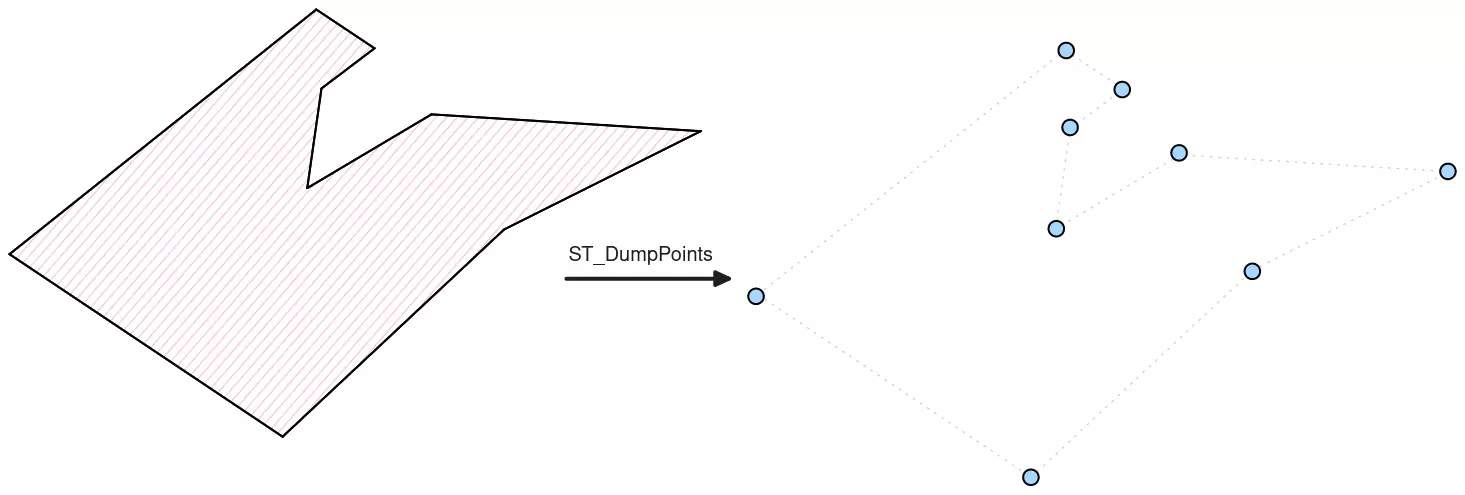
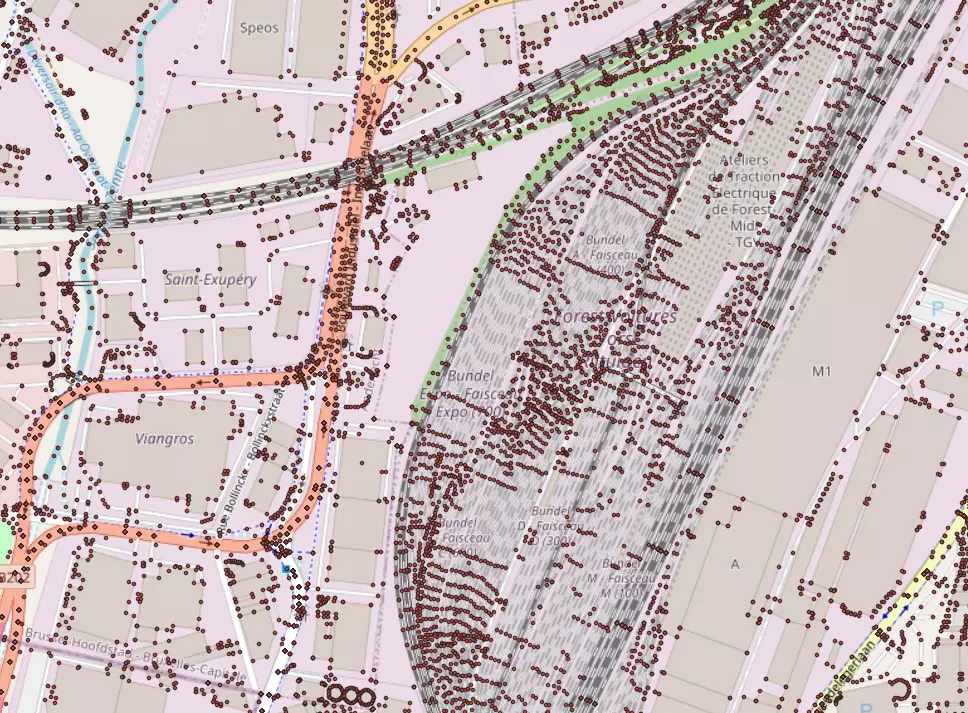
Dans la capture d'écran ci-dessous, les points violets sont la sortie de ST_DumpPoints pour les géométries issues d'OSM (polygones & lignes) :
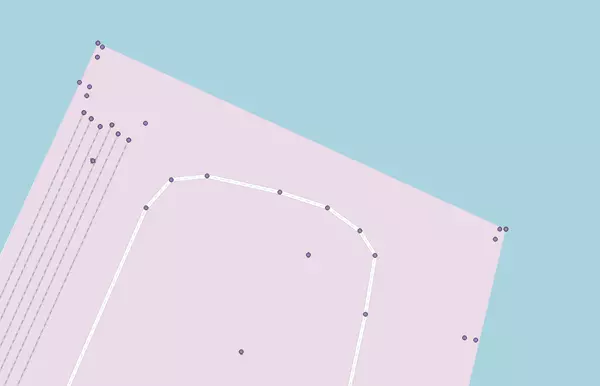
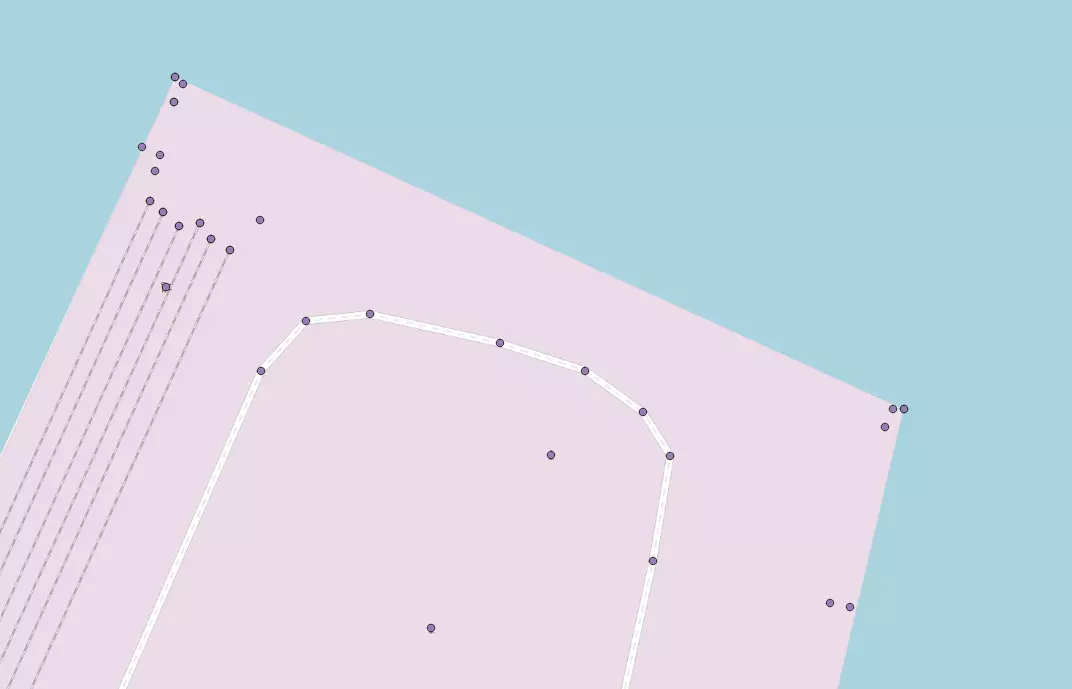
Le volume de données relativement massif va nous demander de mettre en place quelques optimisations afin de gagner du temps.
La première optimisation consiste à créer la table de notre nuage de points en mode UNLOGGED. C'est un type de table de PostgreSQL qui est beaucoup moins résilient aux pannes, mais qui offre des performances d'écriture plus importantes. Globalement, la seule bonne raison d'utiliser ce type de table est valable pour des données intermédiaires de calcul, ce qui est le cas de notre nuage de points !
La deuxième optimisation est d'utiliser une requête CREATE TABLE AS (...) qui permet de créer et de remplir une table en une seule requête. Étant donné que la table n'existe pas encore, Postgres peut réaliser toute une série d'optimisation car on est sûr que personne ne consulte cette table. On court-circuite alors les mécanismes d'insertions de Postgres, lesquels entrainent des opérations coûteuses lorsque la table existe déjà (lock, mise à jour des index, etc.) et nous gagnons en performance.
Commençons par la requête SQL qui fabrique les points des polygones. Je vais écrire les requêtes avec des clauses LIMIT pour pouvoir tester sur des petits volumes de données. Ces clauses seront retirées lorsque nous fabriquerons la table finale contenant le nuage de points.
-- cette requête est ré-utilisée par la suite pour créer la table du nuage de points
SELECT ST_TRANSFORM((ST_DumpPoints(way)).geom, 3812)::geometry(Point, 3812) AS geom
FROM planet_osm_polygon
LIMIT 1000
Notez l'utilisation du code EPSG 3812 (ETRS89 / Belgian Lambert 2008) dans la requête pour reprojeter les données dans un système de projection adapté à la Belgique.
Aussi, il est important de caster le résultat du ST_TRANSFORM en un type PostGIS précis - ici Point projeté en 3812 - car cette information est stockée dans les métadonnées de la colonne. Cela a un gros impact ensuite sur l'utilisabilité d'outils comme QGIS qui inspectent la base de données pour découvrir les tables avec de la géométrie.
En effet, si cette information n'est pas présente au niveau de la colonne, QGIS va jouer des requêtes visant à déterminer le type de géométrie, ce qui nécessite de lire toute la table. Sur des petits volumes c'est rapide, mais sur des volumes plus importants ces requêtes peuvent être très longues !
Nous pouvons ensuite écrire la même requête pour les lignes et les points :
-- ces requêtes sont ré-utilisées par la suite pour créer la table du nuage de points
SELECT ST_TRANSFORM((ST_DumpPoints(way)).geom, 3812)::geometry(Point, 3812) AS geom
FROM planet_osm_line
LIMIT 1000; -- lignes
SELECT ST_TRANSFORM(way, 3812)::geometry(Point, 3812) AS geom
FROM planet_osm_point
LIMIT 1000; -- points
Nous pouvons alors assembler le tout pour fabriquer le nuage de points dans une nouvelle table. Notez que j'ai retiré les clauses LIMIT :
-- cette requête prend environ 1mn20 sur une BDD Postgres en local
CREATE UNLOGGED TABLE all_osm_points AS
SELECT
ST_TRANSFORM((ST_DumpPoints(way)).geom, 3812)::geometry(Point, 3812) AS geom
FROM planet_osm_polygon
UNION ALL
SELECT
ST_TRANSFORM((ST_DumpPoints(way)).geom, 3812)::geometry(Point, 3812) AS geom
FROM planet_osm_line
UNION ALL
SELECT
ST_TRANSFORM(way, 3812)::geometry(Point, 3812) AS geom
FROM planet_osm_point;
La requête peut prendre quelques minutes à s'exécuter, c'est normal. Attention la table a été créée en unlogged, selon la manière dont vous éteignez votre Postgres cela peut entraîner la disparition des données.
Pour pouvoir exploiter cette table, il nous manque à présent deux choses :
- Une clé primaire
- Un index géographique
Ajoutons donc une clé primaire avec la requête suivante :
-- cette requête prend environ 2mn40 sur une BDD Postgres en local
ALTER TABLE all_osm_points ADD COLUMN id BIGSERIAL PRIMARY KEY;
Puis, ajoutons un index géographique :
-- cette requête prend environ 19mn sur une instance Postgres en local
CREATE INDEX ON all_osm_points USING gist(geom);
Si vous inspectez votre schéma de donnée (\d all_osm_points) dans une console psql, vous devriez obtenir la table suivante :
article_density=# \d all_osm_points
Unlogged table "public.all_osm_points"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+--------------------------------------------
geom | geometry(Point,3812) | | |
id | bigint | | not null | nextval('all_osm_points_id_seq'::regclass)
Indexes:
"all_osm_points_pkey" PRIMARY KEY, btree (id)
"all_osm_points_geom_idx" gist (geom)
On peut aussi compter le nombre de lignes dans notre table afin de mieux se rendre compte du volume :
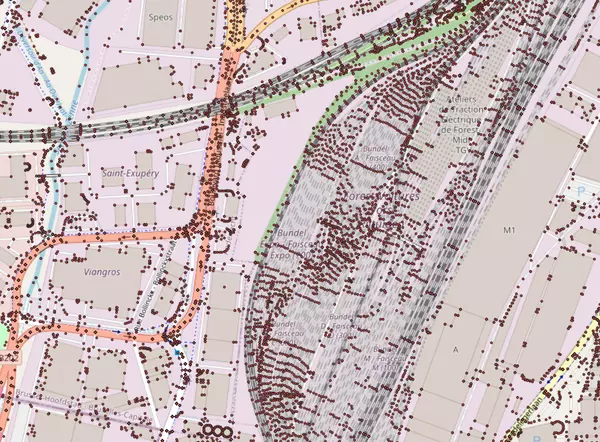
SELECT COUNT(*) FROM all_osm_points; -- 101 748 569 lignes chez moi
Voici le résultat autour de 50.815, 4.312 :
Couverture par un carroyage de raster du territoire belge
Maintenant que le nuage de points est terminé, nous allons fabriquer un carroyage du territoire Belge avec des rasters.
Nous pourrions créer un unique raster pour tout le territoire, mais cela a deux inconvénients majeurs :
- On ne peut pas paralléliser facilement le calcul sur ce raster
- On est limité à ~1Go par ligne dans une base Postgres, sur des grands territoires nous risquons de dépasser cette limite
De plus, PostGIS embarque la fonction ST_MakeEmptyCoverage qui permet de créer un tel carroyage. On a donc vraiment pas d'excuses pour ne pas diviser le travail !
Déterminer les paramètres de ST_MakeEmptyCoverage
La fonction ST_MakeEmptyCoverage reçoit de nombreux paramètres en arguments et certains sont mal documentés (scaley, je pense à toi).
Voici une illustration qui récapitule les principaux paramètres :
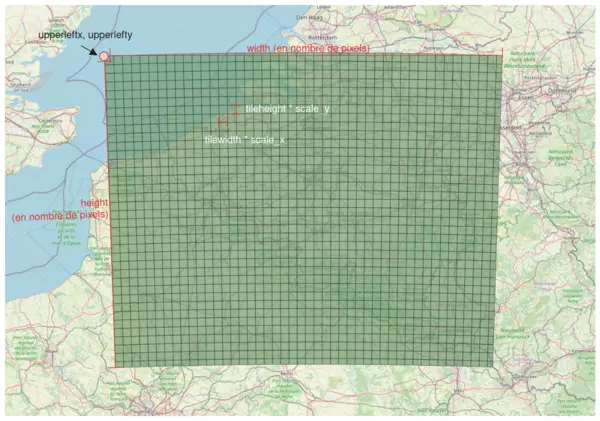
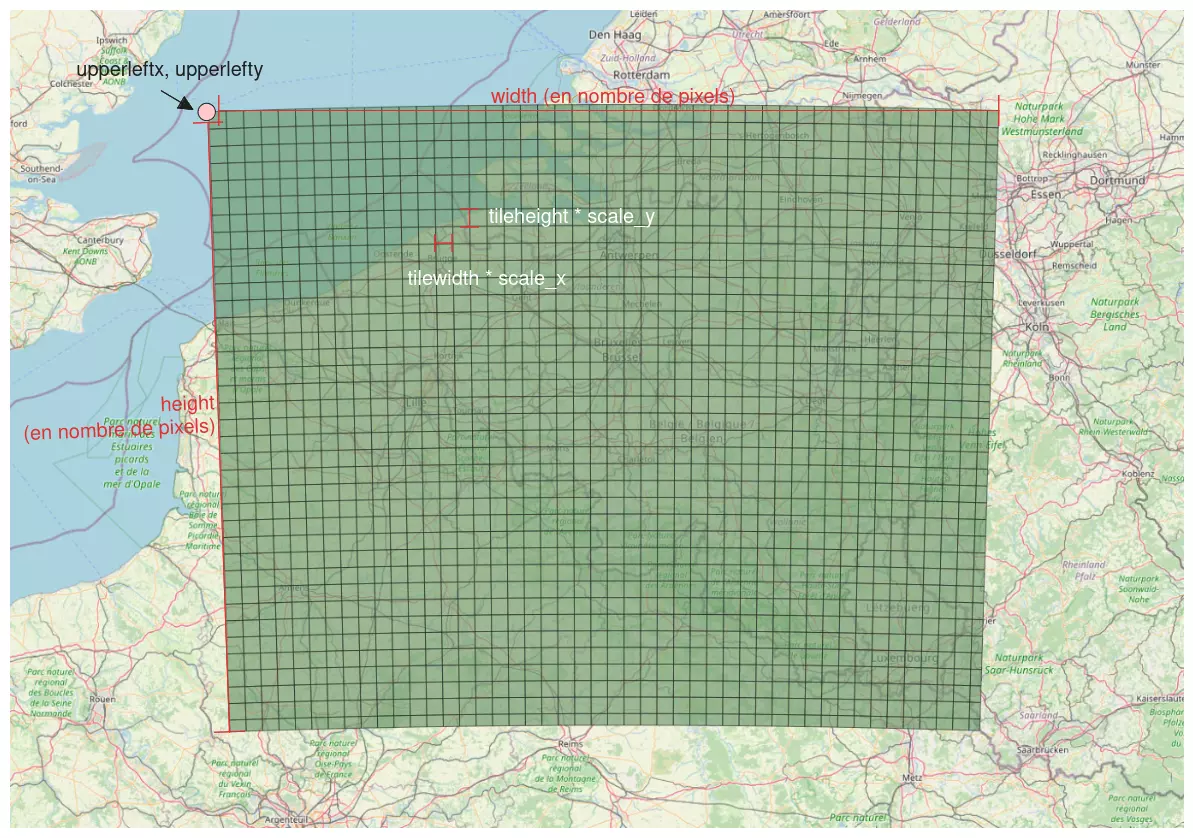
Commençons par définir la résolution des rasters que nous voulons générer. Je vais choisir 100m x 100m, ce qui se traduit par :
scalex= 100scaley= -100
En effet, étant donné que nous sommes dans une projection métrique, nous pouvons directement utiliser les mètres ! Notez bien la valeur négative pour scaley : c'est un standard dans le monde des rasters mais ce n'est documenté nulle part. Si vous utilisez une valeur positive, vous aurez de nombreux problèmes par la suite.
Maintenant, il nous faut définir la boîte dans laquelle nous allons générer les rasters. Comme nous étudions la Belgique, je vais utiliser la boîte englobante du territoire Belge.
Son coin supérieur gauche, en système 3812 est en x=470093.97, y=777595.06. Donc :
upperleftx= 470093.97upperlefty= 777595.06
Ses dimensions sont de 342 450m x 275 300m, mais pour ST_MakeEmptyCoverage nous devons les exprimer en nombre de pixels. Il faut donc les diviser par la taille d'un pixel (ici 100m). Cela donne :
width= 3425height= 2753
Il nous reste maintenant à paramétrer la taille des rasters générés, partons sur 500x500 pixels :
tilewidth= 500tileheight= 500
Enfin, le code EPSG sera 3812, et nous n'utiliserons pas de skew.
Nous pouvons donc générer notre carroyage avec la requête suivante :
-- cette requête nécessite d'avoir chargé l'extension `raster_topology`
CREATE TABLE belgium_raster_coverage AS
SELECT ST_MakeEmptyCoverage(
tilewidth=>500,
tileheight=>500, -- Tile sizes (in pixels)
width=>3425,
height=>gt2753, -- Raster layer size (ie the size of your region)
upperleftx=>470093.9757537913,
upperlefty=>777595.0619878168, -- Raster origin
scalex=>100,
scaley=>-100, -- Pixel size
skewx=> 0,
skewy=>0, -- No skewing
srid=>3812) as raster;
On peut visualiser le résultat en fabriquant une table représentant l'enveloppe de ces rasters et en l'affichant dans QGIS :
CREATE TABLE belgium_raster_coverage_enveloppe AS
SELECT ST_ENVELOPE(raster)
FROM belgium_raster_coverage;
Vous devriez avoir le résultat suivant :
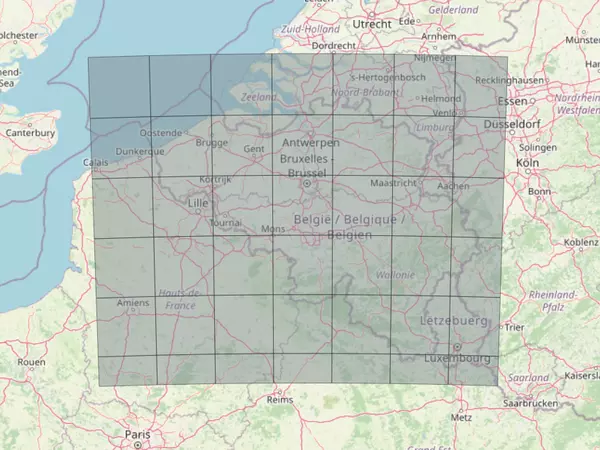
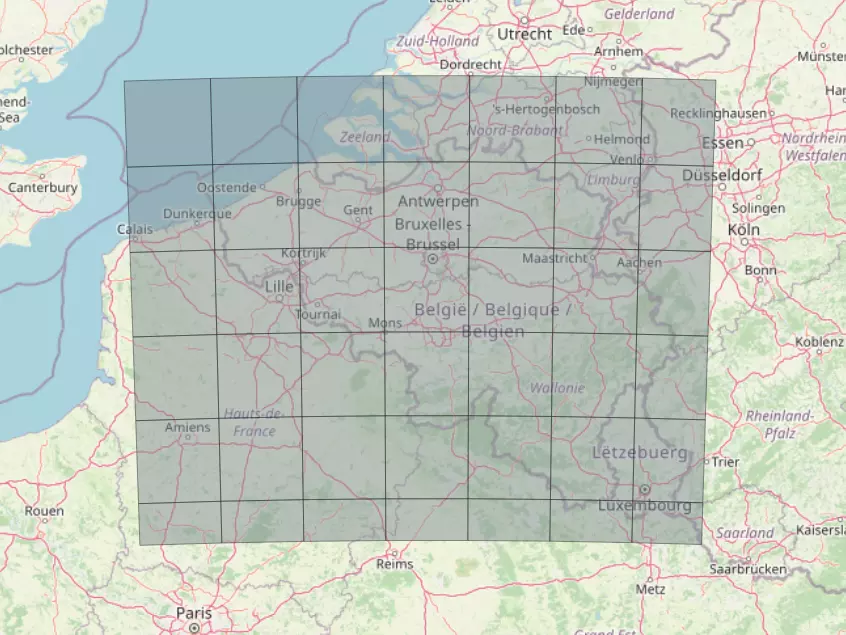
Cependant, nous n'avons pas fini d'initialiser notre couche raster, il faut encore lui ajouter une bande.
En effet, les données raster sont séparées en deux morceaux : d'un côté nous avons les métadonnées du raster (sa résolution, etc.) et de l'autre nous avons la donnée qui porte sur ce raster. La donnée du raster est souvent appelée band en anglais.
ST_MakeEmptyCoverage s'occupe de créer des rasters initialisés avec des métadonnées, mais il est nécessaire d'ajouter une "couche" de données sur le raster pour pouvoir s'en servir dans PostGIS.
Nous allons donc re-créer notre table en configurant cette fois-ci la couche de données.
La requêtes suivante s'occupe de supprimer notre table, et d'ajouter une couche de données d'entiers 32 bits non signés avec la fonction ST_AddBand.
-- cette requête prend environ 450ms sur une BDD Postgres en local
DROP TABLE IF EXISTS belgium_raster_coverage;
CREATE TABLE belgium_raster_coverage AS
SELECT
ST_AddBand(
ST_MakeEmptyCoverage(
tilewidth=>500,
tileheight=>500, -- Tile sizes (in pixels)
width=>3425,
height=>2753, -- Raster layer size (ie the size of your region)
upperleftx=>470093.9757537913,
upperlefty=>777595.0619878168, -- Raster origin
scalex=>100,
scaley=>-100, -- Pixel size
skewx=> 0,
skewy=>0, -- No skewing
srid=>3812),
'32BUI' :: TEXT, 0) as raster;
Avant de réaliser des opérations sur notre colonne raster, il nous faut aussi mettre à jour le catalogue PostGIS. Je n'entrerai pas dans les détails ici, mais cela se fait avec la fonction AddRasterConstraints. Dans notre cas, elle s'utilise ainsi :
SELECT AddRasterConstraints('belgium_raster_coverage'::name, 'raster'::name);
Ajoutons un index géographique sur l'enveloppe des rasters, une clé primaire et mettons à jour les statistiques de PostgreSQL sur cette table :
CREATE INDEX belgium__rast_envelope_idx ON belgium_raster_coverage USING gist( ST_Envelope(raster) );
ALTER TABLE belgium_raster_coverage ADD id bigserial primary key;
ANALYZE belgium_raster_coverage;
Et voilà, nous avons terminé de préparer notre table raster. Nous allons maintenant pouvoir exploiter notre nuage de points pour ajouter de la donnée dans ces rasters.
Calcul des rasters
Pour calculer les rasters, nous allons écrire une fonction SQL. Celle-ci reçoit en entrée l'ID du raster à calculer et stocke dans chaque pixel du raster le nombre de points de notre nuage qui s'y trouve.
Nous allons partir des dimensions du raster pour calculer la boîte de chaque pixel sous la forme d'une géométrie PostGIS. Ensuite, nous allons compter le nombre de points dans cette boîte et faire remonter le résultat dans le raster.
Le SQL est commenté, mais en anglais car c'est une habitude que j'ai prise.
Commençons donc par déclarer une fonction SQL :
CREATE FUNCTION compute_raster(raster_id bigint) RETURNS void LANGUAGE SQL VOLATILE AS $$
$$;
Plusieurs choses sont à noter :
- Il s'agit d'une fonction purement SQL, pas de
plpgsqlici ! - Nous allons directement mettre à jour la table
belgium_raster_coveragedans cette fonction, donc celle-ci ne renvoie rien (ouvoiden SQL) - La fonction est taggée VOLATILE pour indiquer qu'elle dépend des données stockées en base
Maintenant, nous ponvons écrire la requête SQL qui récupérera les métadonnées du raster passé en argument de la fonction :
SELECT (F1.md).*
FROM
(SELECT ST_MetaData(raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1; -- ici on pourra remplacer id par 'raster_id'
En exécutant la requête, j'obtiens le résultat suivant :
-[ RECORD 1 ]-----------------
upperleftx | 470093.9757537913
upperlefty | 777595.0619878168
width | 500
height | 500
scalex | 50
scaley | -50
skewx | 0
skewy | 0
srid | 3812
numbands | 0
Maintenant, stockons le résultat de cette requête dans une Common Table Expression (CTE par la suite) afin de pouvoir s'en servir par la suite.
WITH metadata AS
( SELECT (F1.md).*
FROM
(SELECT ST_MetaData(raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1)
SELECT *
FROM metadata;
Nous pouvons maintenant utiliser les colonnes width et height pour générer toutes les coordonnées des différents pixels de ce raster. Pour cela, nous allons utiliser une jointure de type CROSS JOIN afin de calculer le produit cartésien entre toutes les valeurs de X et de Y possibles pour un pixel.
WITH metadata AS
( -- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM
(SELECT ST_MetaData(raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1 -- ici on pourra remplacer id par 'raster_id'
)
SELECT x,
y
FROM metadata -- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
Vous devriez obtenir une table contenant 250 000 (500x500) lignes avec une colonne x et une colonne y.
Comme pour la requête sur les métadonnées, nous allons stocker les coordonnées dans une CTE afin de pouvoir exploiter cette table par la suite.
Désormais, nous avons toutes les informations qu'il nous faut pour calculer l'enveloppe des 250k pixels du raster. Pour cela, je vais utiliser la fonction ST_MakeEnvelope. Cette fonction reçoit en entrée le coin supérieur gauche et le coin inférieur droit d'une boîte englobante et renvoie la géométrie de la boîte englobante. Nous devons donc calculer ces deux points.
Pour déterminer leur coordonnées, nous allons nous baser sur l'origine du raster, la taille d'un pixel et ses coordonnées.
Illustration :
WITH metadata AS (
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
En lançant cette requête dans un CREATE TABLE debug_pixel AS ... vous pouvez fabriquer une table que nous pouvons ensuite visualiser dans QGIS, la requête peut prendre plusieurs minutes à s'exécuter. Vous devriez obtenir le résultat suivant pour le raster avec l'ID 18 chez moi :
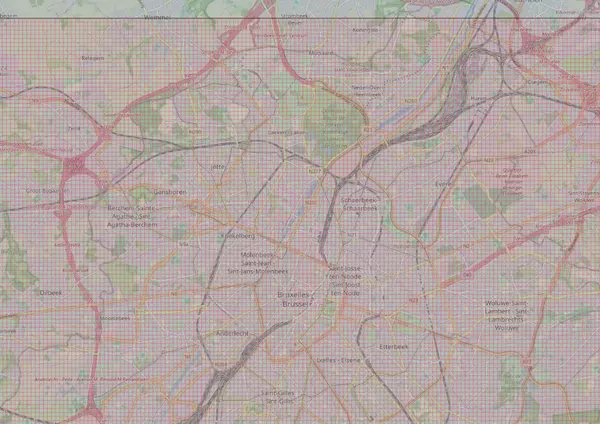
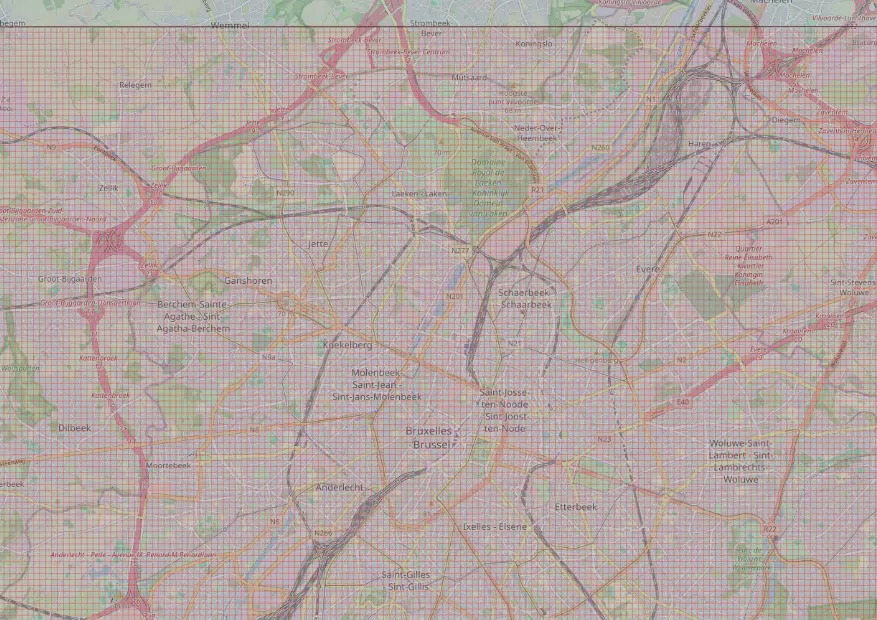
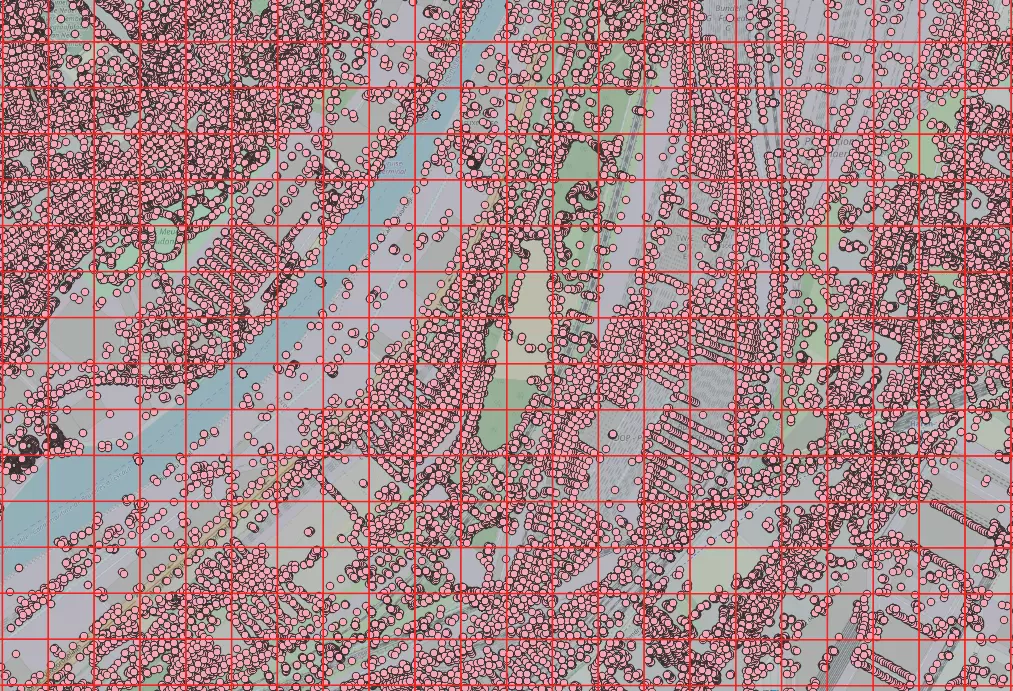
Nous pouvons enfin compter les points OSM dans notre petit pixel. Stockons le résultat de la requête précédente dans une CTE et réalisons une agrégation sur les points intersectant notre enveloppe.
J'utilise une fonction INNER JOIN afin d'éliminer les lignes n'ayant aucune donnée, je pense que cela allège le résultat intermédiaire que manipule Postgres.
WITH metadata AS (
-- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
),
pixels AS (
-- This CTE generates Postgis geometries representing each pixel boundary using the pixel coords (x,y)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley ,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
)
-- This query computes the value that should be inserted into each raster pixel
-- The result is sorted/grouped by coordinates
SELECT pixels.x AS x,
pixels.y AS y,
count(pc.id) as value
FROM pixels
INNER JOIN all_osm_points pc
ON ST_Intersects(pixels.enveloppe, pc.geom)
GROUP BY x, y
ORDER BY x, y
Voici, une illustration de l'intersection entre le nuage de points et les pixels d'un raster :
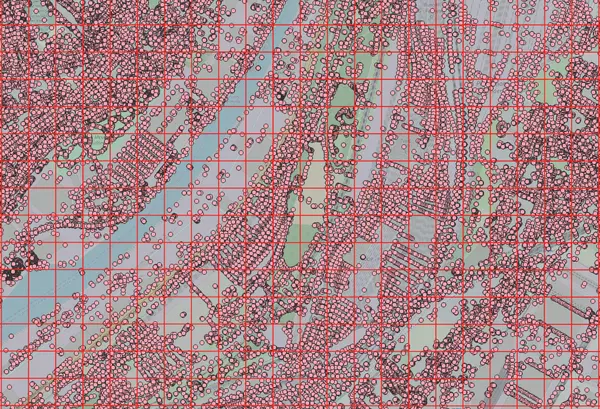
A présent que nous avons fabriqué la donnée que nous souhaitons embarquer dans notre raster, il faut la mettre en forme pour que PostGIS l'interprète correctement.
Nous allons donc manipuler beaucoup de tableaux Postgres jusqu'à obtenir un tableau de pixel 2D.
Dans un premier temps, nous allons fabriquer une table Postgres contenant 3 colonnes : x, y et value.
WITH metadata AS (
-- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
),
pixels AS (
-- This CTE generates Postgis geometries representing each pixel boundary using the pixel coords (x,y)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley ,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
),
values AS (
-- This query computes the value that should be inserted into each raster pixel
-- The result is sorted/grouped by coordinates
SELECT pixels.x AS x,
pixels.y AS y,
count(pc.id) as value
FROM pixels
INNER JOIN all_osm_points pc
ON ST_Intersects(pixels.enveloppe, pc.geom)
GROUP BY x, y
ORDER BY x, y
)
-- This query creates 0 value for pixels with no data
-- X and Y coordinates are mixed, because postgis doesn’t document very well if the argument "newvalueset" is in column or row first
-- I could have rewritten the query to take that into account, but I find it easier to mix X and Y here.
SELECT c.y as x, c.x as y, COALESCE(v.value::double precision, 0.0) as value
FROM coords c
LEFT JOIN values v ON c.x = v.x and c.y = v.y
ORDER by x, y
Maintenant, agrégeons cette table pour retirer la colonne des Y et avoir à la place un tableau Postgres.
WITH metadata AS (
-- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
),
pixels AS (
-- This CTE generates Postgis geometries representing each pixel boundary using the pixel coords (x,y)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley ,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
),
values AS (
-- This query computes the value that should be inserted into each raster pixel
-- The result is sorted/grouped by coordinates
SELECT pixels.x AS x,
pixels.y AS y,
count(pc.id) as value
FROM pixels
INNER JOIN all_osm_points pc
ON ST_Intersects(pixels.enveloppe, pc.geom)
GROUP BY x, y
ORDER BY x, y
),
flat_array AS (
-- This CTE creates 0 value for pixels with no data
-- X and Y coordinates are mixed, because postgis doesn’t document very well if the argument "newvalueset" is in column or row first
-- I could have rewritten the query to take that into account, but I find it easier to mix X and Y here.
SELECT c.y as x, c.x as y, COALESCE(v.value::double precision, 0.0) as value
FROM coords c
LEFT JOIN values v ON c.x = v.x and c.y = v.y
ORDER by x, y)
SELECT v.x, array_agg(v.value ORDER BY v.y) AS row FROM flat_array v GROUP BY v.x;
Nous pouvons ensuite réaliser la même opération pour agréger la deuxième dimension du tableau en une unique valeur.
WITH metadata AS (
-- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
),
pixels AS (
-- This CTE generates Postgis geometries representing each pixel boundary using the pixel coords (x,y)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley ,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
),
values AS (
-- This query computes the value that should be inserted into each raster pixel
-- The result is sorted/grouped by coordinates
SELECT pixels.x AS x,
pixels.y AS y,
count(pc.id) as value
FROM pixels
INNER JOIN all_osm_points pc
ON ST_Intersects(pixels.enveloppe, pc.geom)
GROUP BY x, y
ORDER BY x, y
),
flat_array AS (
-- This CTE creates 0 value for pixels with no data
-- X and Y coordinates are mixed, because postgis doesn’t document very well if the argument "newvalueset" is in column or row first
-- I could have rewritten the query to take that into account, but I find it easier to mix X and Y here.
SELECT c.y as x, c.x as y, COALESCE(v.value::double precision, 0.0) as value
FROM coords c
LEFT JOIN values v ON c.x = v.x and c.y = v.y
ORDER by x, y),
row_values AS (
SELECT v.x, array_agg(v.value ORDER BY v.y) AS row FROM flat_array v GROUP BY v.x
)
SELECT ARRAY_AGG(rv.row ORDER BY rv.x) AS v FROM row_values rv
Enfin, mettons à jour le raster avec cette donnée :
WITH metadata AS (
-- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = 1) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
),
pixels AS (
-- This CTE generates Postgis geometries representing each pixel boundary using the pixel coords (x,y)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley ,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
),
values AS (
-- This query computes the value that should be inserted into each raster pixel
-- The result is sorted/grouped by coordinates
SELECT pixels.x AS x,
pixels.y AS y,
count(pc.id) as value
FROM pixels
INNER JOIN all_osm_points pc
ON ST_Intersects(pixels.enveloppe, pc.geom)
GROUP BY x, y
ORDER BY x, y
),
flat_array AS (
-- This CTE creates 0 value for pixels with no data
-- X and Y coordinates are mixed, because postgis doesn’t document very well if the argument "newvalueset" is in column or row first
-- I could have rewritten the query to take that into account, but I find it easier to mix X and Y here.
SELECT c.y as x, c.x as y, COALESCE(v.value::double precision, 0.0) as value
FROM coords c
LEFT JOIN values v ON c.x = v.x and c.y = v.y
ORDER by x, y),
row_values AS (
-- This CTE returns a set of rows with a single array of value for each X value
SELECT v.x, array_agg(v.value ORDER BY v.y) AS row FROM flat_array v GROUP BY v.x
),
raster_value AS (
-- This CTE returns a single value which is a 2D array of pixel values
SELECT ARRAY_AGG(rv.row ORDER BY rv.x) AS v FROM row_values rv
)
UPDATE belgium_raster_coverage
SET raster = ST_SetValues(raster, 1, 1, 1, raster_value.v)
FROM raster_value WHERE id = 1;
Et remettons tout ça dans la fonction :
CREATE OR REPLACE FUNCTION compute_raster(raster_id bigint) RETURNS void LANGUAGE SQL VOLATILE AS
$$
WITH metadata AS (
-- this CTE fetches the metada FROM a raster row
SELECT (F1.md).*
FROM (SELECT ST_MetaData( raster) AS md
FROM belgium_raster_coverage
WHERE id = raster_id) AS F1
),
coords AS (
-- This CTE returns all the pairs (x,y) for x in [1, raster width] AND y in [1, height]
SELECT x, y FROM metadata
-- Generate pixel coordinates for this raster
CROSS JOIN generate_series(0, metadata.width - 1) x
CROSS JOIN generate_series(0, metadata.height - 1) y
),
pixels AS (
-- This CTE generates Postgis geometries representing each pixel boundary using the pixel coords (x,y)
SELECT
coords.x AS x,
coords.y AS y,
-- Build postgis geometry using raster metadata informations :
-- scale_x : pixel width
-- scale_y : pixel height (it is usually negative, don’t ask me why, it’s juste the way raster people do their stuff)
-- upperleft(x|y) : coordinates of the upper left point
ST_MakeEnvelope(metadata.upperleftx + coords.x * metadata.scalex,
metadata.upperlefty + coords.y * metadata.scaley ,
metadata.upperleftx + (coords.x + 1) * metadata.scalex,
metadata.upperlefty + (coords.y + 1) * metadata.scaley,
metadata.srid) AS enveloppe
FROM coords, metadata
),
values AS (
-- This query computes the value that should be inserted into each raster pixel
-- The result is sorted/grouped by coordinates
SELECT pixels.x AS x,
pixels.y AS y,
count(pc.id) as value
FROM pixels
INNER JOIN all_osm_points pc
ON ST_Intersects(pixels.enveloppe, pc.geom)
GROUP BY x, y
ORDER BY x, y
),
flat_array AS (
-- This CTE creates 0 value for pixels with no data
-- X and Y coordinates are mixed, because postgis doesn’t document very well if the argument "newvalueset" is in column or row first
-- I could have rewritten the query to take that into account, but I find it easier to mix X and Y here.
SELECT c.y as x, c.x as y, COALESCE(v.value::double precision, 0.0) as value
FROM coords c
LEFT JOIN values v ON c.x = v.x and c.y = v.y
ORDER by x, y),
row_values AS (
-- This CTE returns a set of rows with a single array of value for each X value
SELECT v.x, array_agg(v.value ORDER BY v.y) AS row FROM flat_array v GROUP BY v.x
),
raster_value AS (
-- This CTE returns a single value which is a 2D array of pixel values
SELECT ARRAY_AGG(rv.row ORDER BY rv.x) AS v FROM row_values rv
)
UPDATE belgium_raster_coverage
SET raster = ST_SetValues(raster, 1, 1, 1, raster_value.v)
FROM raster_value WHERE id = raster_id;
$$;
Bravo si vous avez tenu jusqu'ici ! Il ne nous reste plus qu'à lancer le calcul sur l'ensemble des rasters 🎉.
-- cette requête prend environ 13mn sur une BDD Postgres en local
SELECT compute_raster(id) FROM belgium_raster_coverage;
L'opération peut durer assez longtemps.
Conclusion
À travers cet article, nous avons développé un ensemble de requêtes SQL permettant de fabriquer de la donnée raster à partir d'un nuage de points. Cette technique peut s'adapter à de nombreux cas d'usage (pas seulement les calculs de densité), il faut simplement adapter l'opération qui est réalisée au sein des pixels, ici un COUNT.
Bien évidemment, nous pouvons ensuite traiter la donnée raster avec les outils standards du monde SIG. Par exemple, voici une carte de niveau selon la densité de nœuds OSM, la donnée a été fabriquée avec ST_Contour):

Django-Python-Rust
Formations associées
Formations Outils et bases de données
Formation PostgreSQL
Nantes Du 29 au 31 janvier 2024
Voir la formationActualités en lien

Générer un fichier PMTiles à partir d’un MBTiles
Exemple de conversion d’une base de tuiles vectorielles MBTiles du Plan Cadastral Informatisé vers le format PMTiles (Protomaps).
Générer un fichier PMTiles avec Tippecanoe
Exemple de génération et d’affichage d’un jeu de tuiles vectorielles en PMTiles à partir de données publiques.
Protomaps, stockez vos pyramides de tuiles plus simplement
Présentation d'un nouveau format de stockage de tuiles cartographiques