Makina Blog
Machine Learning : classer automatiquement vos données à l'import
Comment utiliser des algorithmes de machine learning pour importer correctement des données dans vos projets de DataScience ?
Cet article est le premier d'une (longue ?) série sur notre utilisation du machine learning pour nos clients.
La première étape d'un projet de machine learning est la récupération et l'import des données. Malheureusement, dans des projets réels, nous obtenons régulièrement des fichiers incomplets, comportant des erreurs…
Il est donc crucial, avant même de travailler sur des visualisations ou des algorithmes, de s'assurer d'obtenir des données correctes, et correctement étiquetées.
Dans cet article, nous regarderons comment font les plateformes de data-science pour importer des fichiers, puis nous expliquerons les différentes étapes de conception de notre propre solution de classification des données.
État de l'art
Avant de commencer à développer, nous avons regardé l'état de l'art de la partie "import" des plateformes de Datascience, en suivant les recommandations annuelles de Gartner et en se concentrant sur les plateformes opensource ou gratuites :
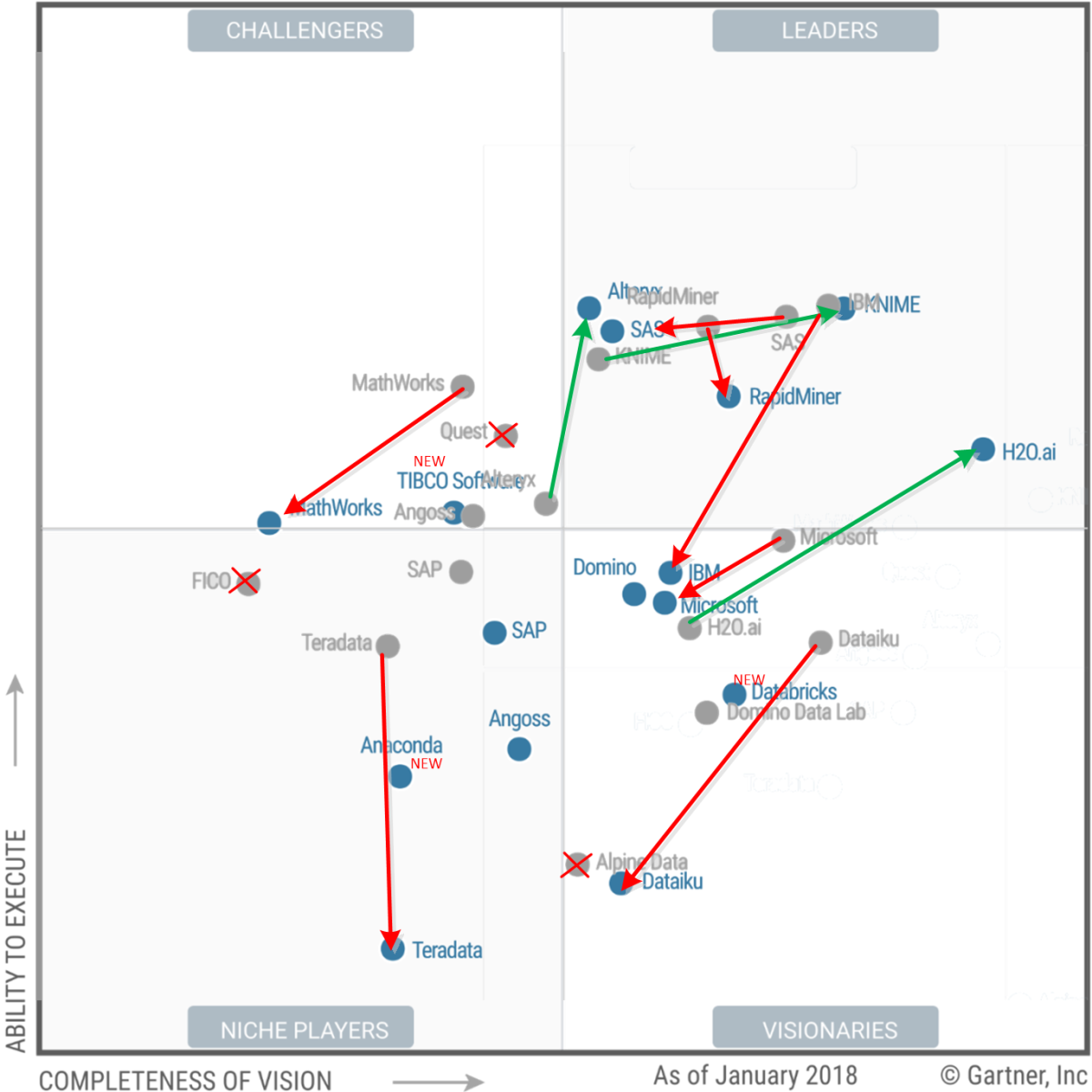
Dataiku
Bien que non open-source, il existe une version gratuite de cette application. De celles que nous avons testé, c'est l'application qui propose la meilleure fonctionnalité d'import, à la fois en terme de format de fichiers supportés automatiquement et au niveau du parsing automatique des champs :
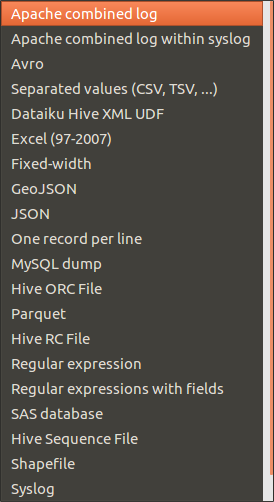
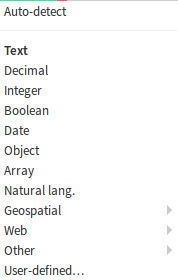
Enfin, les performances et l'expérience utilisateur sont nettement supérieures aux autres applications.
H20.ai
Les types de données automatiquement reconnus par H20.ai sont plus limités :
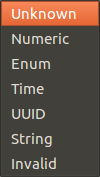
D'ailleurs, lors de l'import de notre fichier de test, la majorité des données ont été étiquetées "Enum".
OpenRefine
Sous OpenRefine, les URLs n'ont été correctement parsées que lorsqu'elles commençaient par un protocole ("http") valide. L'import de notre fichier de test, pourtant pas si conséquent (un fichier excel de 700 Ko, 115 colonnes et 600 lignes) a par contre complètement empêché l'application de continuer à fonctionner ensuite, rendant cette application de fait inutilisable pour un projet de Datascience un peu conséquent, du moins sur ma machine, pourtant relativement puissante.
À noter qu'OpenRefine possède un nombre d'extensions permettant de supporter d'autres types de données (par exemple les données géographiques).
K-Nime
Ici, pas de parsing automatique. L'application est centrée sur la manipulation de données, comme des applications ETL type Talend.
Pour améliorer les performances de l'ensemble des applications, il est recommandé de typer les données manuellement. Cependant, cette solution n'est pas pratique pour des ensembles massifs de données, et ne permet pas la détection rapide d'anomalies ou de données mal placées.
Notre solution : "Smart Import"
Petite vidéo comme mise en bouche :
Globalement, nous n'avons pas été satisfait par les possibilités des plateformes de datascience actuelles, même si Dataiku représente un bon exemple de ce que nous souhaitons obtenir en terme de couverture de données. Nous avons donc décidé de réaliser notre propre solution de typage automatique de données, à base d'algorithmes de machine learning.
Nous cherchons à identifier le type précis de chacune des colonnes d'un jeu d'entrée. Nous ne voulons pas nous arrêter à un classement simple par chaîne de caractère / entier / date, mais être capable de faire la différence entre un code postal et un numéro de téléphone ou encore distinguer une adresse d'un nom de famille.
Nous pourrions envisager de fonctionner avec des expressions régulières, mais la diversité des saisies nous obligerait à constamment mettre à jour notre code et notre application serait peu tolérante aux légères erreurs que l'humain peut produire. De plus nous souhaitons pouvoir prendre en compte différentes informations qui tournent autour de la donnée, comme la position d'une colonne par rapport aux autres, ce qui n'est pas compatible avec l'usage d'expressions régulières.
Traitement du langage
Pourquoi ne pas utiliser les algorithmes classiques de traitement du langage ?
Ici, nous n'importons qu'un seul document, donc les algorithmes basés sur la fréquence (Tf-Idf) ou la catégorisation (LDA) ne peuvent pas être utilisés. Nous pourrions éventuellement considérer chaque colonne comme un document différent, mais la plupart des colonnes d'un CSV sont constituées de données complètement indépendantes, et ces algorithmes ne fonctionneront probablement pas.
Enfin, les colonnes contiennent de nombreuses données numériques, pour lesquelles ces algorithmes ne sont pas forcément prévus.
Il y a tout de même un point sur lequel ces algorithmes nous ont inspiré : Word2Vec contient un paramètre qui détermine la distance jusqu'à laquelle les mots seront pris en compte. De la même façon, nous pensons utiliser les colonnes proches dans le CSV pour améliorer la pertinence de notre classification. Mais nous y reviendrons.
Transformation numérique des textes
Si nous n'utilisons pas d'algorithmes classiques de NLP, nous devons tout de même convertir les chaînes de caractères en vecteurs numériques, pour pouvoir les manipuler dans les algorithmes de machine learning.
Nous générons une matrice indiquant pour chaque caractère sa place dans le fragment de texte analysé. Les colonnes de notre matrice correspondent aux différents caractères possibles, les lignes aux positions dans le texte. Par exemple, pour le mot Bac nous obtenons la matrice suivante :
| a | b | c | […] | Maj | |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | […] | 1 |
| 2 | 1 | 0 | 0 | […] | 0 |
| 3 | 0 | 0 | 1 | […] | 0 |
| 4 | 0 | 0 | 0 | […] | 0 |
| 5 | 0 | 0 | 0 | […] | 0 |
La dernière colonne nous permet d'indiquer si la lettre est une majuscule ou une minuscule. Le résultat peut également vu comme une image noire et blanc, où les pixels blancs correspondent aux caractères.

Exemple 1 : matrice obtenue pour le nom d'une entreprise (image originale x 16)

Exemple 2 : matrice obtenue pour une date (image originale x 16)
Les deux exemples ci-dessus nous montrent que ce descripteur permet de distinguer facilement un nom d'entreprise (principalement composé de lettres et commençant par une majuscule ) d'une date (composée en majorité de chiffres).
Tests des algorithmes

Ici, nous cherchons à déterminer le type de n'importe quelle donnée du fichier, nous pensons donc naturellement utiliser des algorithmes de classification. Mais il en existe de très nombreux. Scikit-learn, notre framework de prédilection, fournit d'ailleurs une aide au choix de l'algorithme :
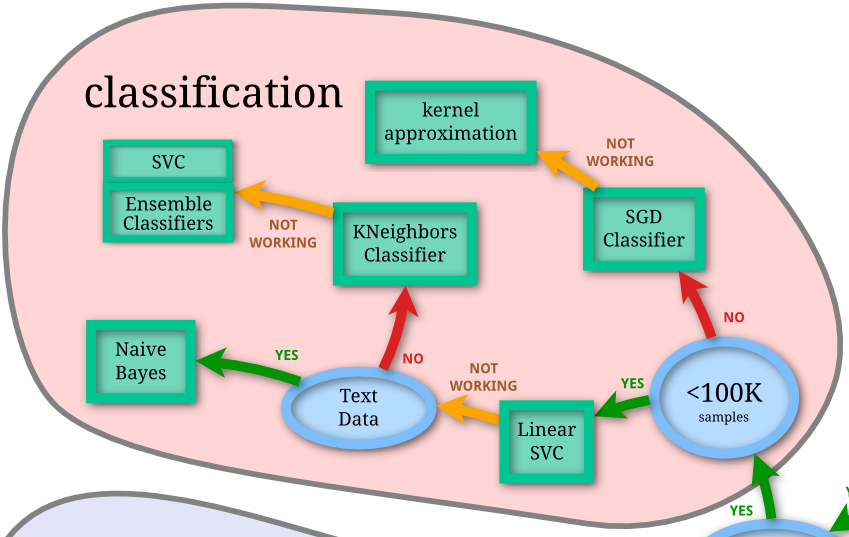
Baseline
On cherche naturellement à évaluer la performance de nos algorithmes, et donc, il faut partir de quelque chose.
Heureusement, scikit-learn inclus un "faux" classifieur pour avoir un point de départ : DummyClassifier. Bien sûr, il donne une précision de 8%, mais au moins nous avons un résultat pour comparer avec les autres algorithmes, et cela nous a permis de mettre en place la majorité de notre code fonctionnel : utilisation d'un algorithme, validation des résultats, métriques…
Il est important de valider les résultats de notre classifieur, à la fois au niveau de la performance "brute", mais aussi de comprendre comment le classifieur fonctionne. Ici, nous utiliserons des "matrices de confusion", qui permettent d'illustrer comment chaque classe est identifiée, en comparant l'écart entre les classes prédites par l'algorithme et les classes réelles.
Algorithmes classiques
En pratique, pour une baseline réaliste, on utilise plutôt un algorithme Baysien naïf, souvent relativement performant et surtout très rapide plus ou moins quelles que soient les données. Dans un contexte de classification de texte, la documentation de scikit-learn recommande de tester MultinomialNB et BernouilliNB. Nous avons obtenu un peu plus de 70% de précision avec ces deux algorithmes.
Voici la première matrice de confusion que nous avons obtenue :

Ensuite, nous avons testé SVM, considéré comme le plus efficace pour classifier du texte. Nous sommes arrivés à plus de 80% de précision.
Autres algorithmes
Nous avons fini par tester tous les classifieurs fournis par Scikit-learn, plus quelques autres (XGBoost, par exemple). Attention, ici ils sont testés avec leurs paramètres de base, sans aucune modification.
Note : ici, c'était plus par curiosité, ce n'est bien sûr pas à faire : chaque classifieur a une raison d'utilisation (par exemple, l'algorithme GaussianNB est à utiliser si les features ont une distribution Gaussienne, ce qui n'est pas forcément le cas ici). Voilà une illustration des différences entre les classifieurs implémentés par scikit-learn :
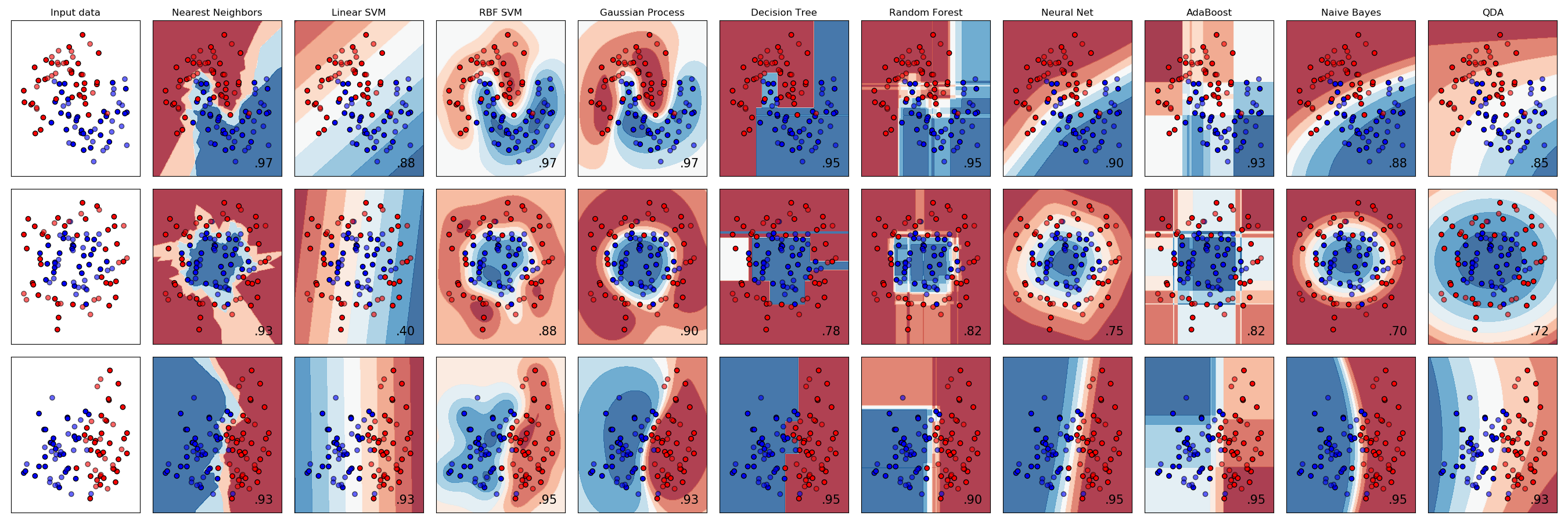
Voilà les résultats obtenus :
|
Classifieur |
Temps d'entraînement |
Précision moyenne (95 % de confiance) |
|---|---|---|
| ExtraTreesClassifier | ~ 1 s | 0.85 (+/- 0.07) |
| RandomForestClassifier | ~ 1 s | 0.83 (+/- 0.07) |
| LinearSVC | ~ 3 s | 0.83 (+/- 0.07) |
| MLPClassifier | ~ 17 s | 0.83 (+/- 0.07) |
| ExtraTreeClassifier | < 1 s | 0.83 (+/- 0.06) |
| DecisionTreeClassifier | ~ 2 s | 0.83 (+/- 0.06) |
| BaggingClassifier | ~ 5 s | 0.82 (+/- 0.07) |
| XGBoostClassifier | > 10 min | 0.82 (+/- 0.08) |
| SGDClassifier | ~ 3 s | 0.81 (+/- 0.07) |
| BernoulliNB | < 1 s | 0.74 (+/- 0.12) |
| MultinomialNB | < 1 s | 0.72 (+/- 0.10) |
| KneighborsClassifier | ~ 1 min 30 s | 0.70 (+/- 0.09) |
| GaussianNB | ~ 1 s | 0.58 (+/- 0.18) |
Les enseignements que nous avons tiré :
- Les algorithmes baysiens naïfs sont en effet les plus rapides (et pas si mauvais) ;
- SVM (ici LinearSVC) est effectivement plus efficace, et les performances se tiennent avec les autres algorithmes ;
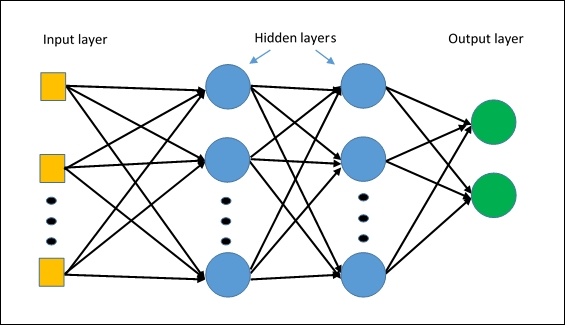
- Nous avons également tenté d'utiliser de l'apprentissage profond, mais ici, ça n'a pas fonctionné mieux que SVM. Nous n'avons pas tout construit nous-mêmes, mais utlisé les fonctionnalités de scikit-learn : les lettres MLP dans le MLPClassifier signifient "Multi Layer Perceptron", c'est-à-dire un réseau de neurones relativement simple dans son fonctionnement :
- La plupart des matrices de confusion se ressemblent, mais certaines permettent de mettre en avant un problème précis pour un algorithme, nous permettant de l'éliminer. Voici un exemple de matrice avec un problème spécifique sur une des classes qui nous a conduit à éliminer cet algorithme :

Le mauvais classement d'une classe précise (au milieu à droite) a disqualifié directement l'algorithme, malgré sa précision globale.
Automatic Machine Learning
Bien que nous soyons satisfaits des résultats précédents, nous avons décidé de tester auto-sklearn. Cette bibliothèque d'Automatic Machine Learning choisit seule le(s) meilleur(s) algorithme(s) et le(s) meilleur(s) paramétrage(s) pour cet algorithme :
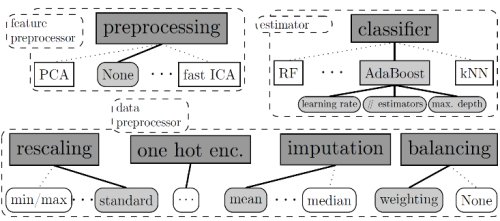
Étant pleinement compatible avec scikit-learn, très peu de code est à changer pour l'utiliser.
Nous avons également testé, toujours dans le domaine de l'Auto-ML, l'algorithme TPOT. La principale différence avec auto-sklearn réside dans la méthode d'optimisation : là où auto-sklearn utilise une optimisation baysienne, TPOT utilise une méthode basée sur de la programmation génétique afin d'indiquer la meilleure suite d'algorithmes à utiliser :
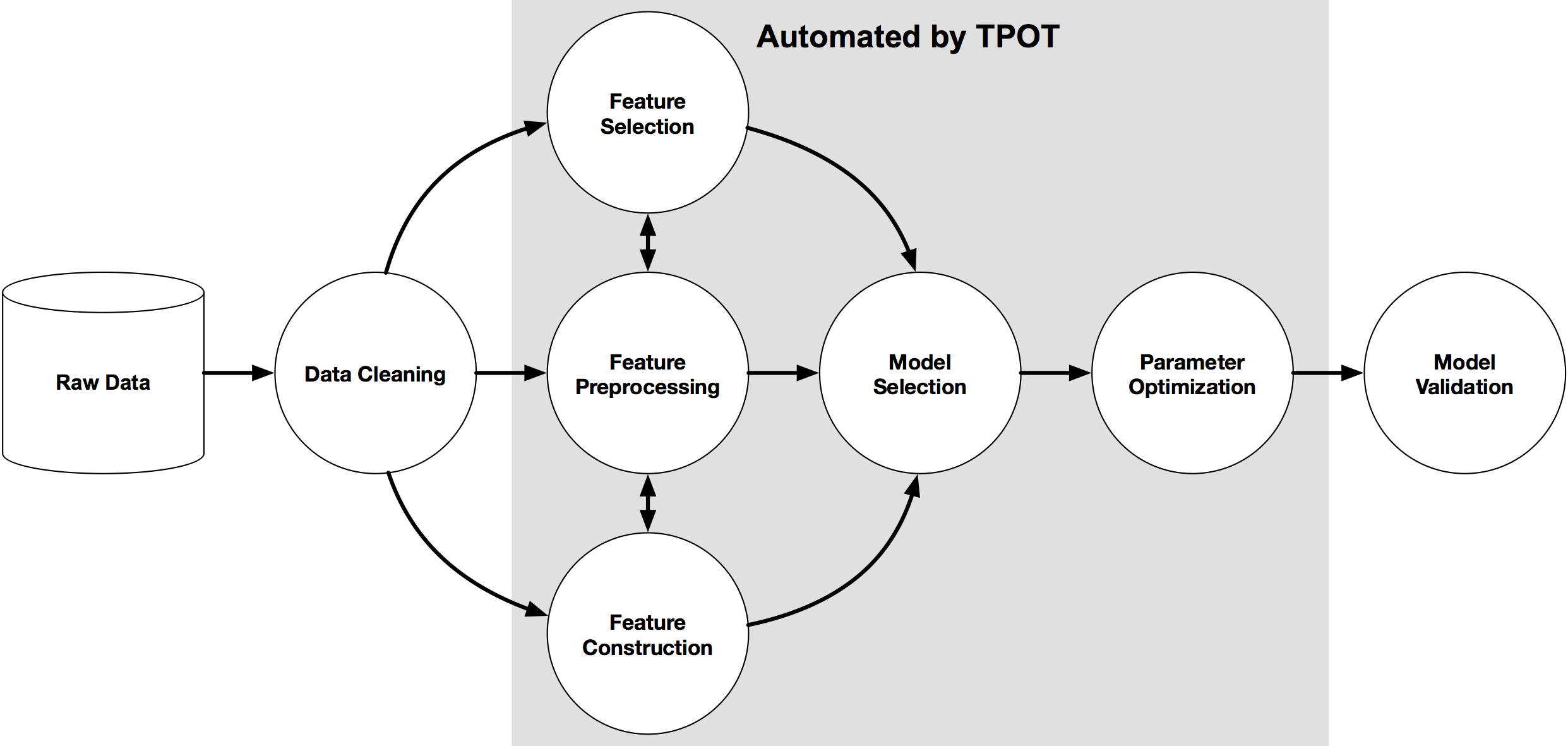
Là où auto-sklearn génère un fichier .json indiquant les pipelines retenus, TPOT va jusquà générer le code Python permettant l'exécution du meilleur pipeline.
À noter que TPOT permet de choisir facilement la liste d'algorithmes et de paramètres à tester, permettant de ne le lancer que sur un seul algorithme, par exemple.
Globalement, les deux algorithmes ont confirmé que les arbres de décision, notamment ExtraTreesClassifier, étaient à privilégier dans notre cas. Cependant, en ne les laissant tourner que quelques heures, la performance finale obtenue n'a que très peu augmentée (85% dans les deux cas). Une fois stabilisé le reste de notre code, nous referons tourner ces algorithmes plusieurs jours pour établir le meilleur pipeline à utiliser dans notre cas précis.
Entraînement du modèle
Jusqu'à maintenant, pour tester nos algorithmes, nous sommes partis d'un fichier de données réelles que nous savions défaillantes (mauvaises données, données dans de mauvaises colonnes…). Maintenant que nous avons une base de travail algorithmique, nous pouvons entraîner notre modèle avec des données de très bonnes qualité issues de source reconnues (notamment, data.gouv.fr), par exemple :
- La base SIREN des entreprises ;
- Adresse des musées de France ;
- …
Amélioration de la pertinence
Inspirés par ce très bon article sur le sujet [EN] (à lire avant d'aller plus loin), nous avons essayé plusieurs choses :
- modifier les données ;
- modifier l'algorithme ;
- tuner l'algorithme (c'est la partie Automatic Machine Learning) ;
- utiliser des ensembles (scikit-learn propose nativement certains algorithmes qui fonctionnent comme ça, les familiers du framework auront d'ailleurs noté que l'algorithme qui offre actuellement la meilleure performance, ExtraTreesClassifier, est dans le package sklearn.ensemble).
Transformation du texte en features
D'abord, nous avons tenté d'exprimer nos features différemment, en indiquant directement la position de chaque caractère (toujours pour le mot Bac) :
| a | b | c | […] | |
|---|---|---|---|---|
| 1 | 2 | 1 | 3 | […] |
| 2 | 0 | 0 | 0 | […] |
| 3 | 0 | 0 | 0 | […] |
Nous n'avons pas réussi à améliorer la précision de notre classifieur avec cette modification.
Contexte
Pour améliorer la pertinence de notre classifieur, une idée (inspirée de Word2Vec) est d'utiliser les colonnes proches de la colonne étudiée, afin de donner un contexte à certaines données (notamment, les adresses décomposées en plusieurs colonnes, par exemple).
Nous y reviendrons dans un prochain article.
Optimisation du modèle
Cette phase d'optimisation du modèle, qui aurait pu être nécessaire, est en pratique réalisée par les algorithmes d'Automatic Machine Learning que nous pouvons utiliser. Nous n'avons donc pas à tester manuellement toutes les combinaisons de paramètres, yay ! ;-)
Compréhension du modèle
L'utilisation de certains algorithmes de machine learning ne permet pas immédiatement de comprendre la décision du classifieur. Ce point, pas forcément gênant pour certains usages, est rédhibitoire dès que l'on touche a des algorithmes décisionnels dans le service public (on pense aux nombreux débats sur l'affectation des élèves après le bac) ou dès que la vie privée ou la sécurité des gens est impliquée.
Une branche des recherches sur le machine learning se penche donc actuellement sur ce que la DARPA appelle XAI : l'eXplainable Artificial Intelligence.
Nous avons cherché à comprendre les prédictions de nos modèles (même si elles peuvent paraître intuitives pour le moment : un code postal est représenté par 5 chiffres qui se suivent, par exemple).
Il existe plusieurs bibliothèques en Python sur le sujet, et nous avons notammé considéré Lime (pour Local Interpretable Model-agnostic Explanations) et SHAP (pour SHapley Additive exPlanations).
Voilà le résultat obtenu pour l'analyse d'un résultat sur Lime : on observe la corrélation entre nos features (ici, numériques, comme vu plus haut (résultat de la décomposition de l'élément de texte en matrice de caractères) et la prédiction donnée par le classifieur :
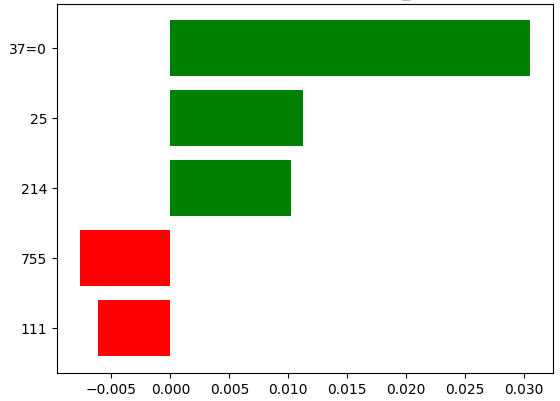
Reste à faire
Nous avons un modèle qui nous satisfait pour le moment. Il reste cependant un certain nombre de choses à faire :
- Nettoyer les données dès l'import : pour cela, nous devons apprendre à détecter les anomalies dans nos données ;
- Tester certaines améliorations de notre modèle, par exemple en implémentant notre propre réseau de neurones, si possible utilisant le contexte (comme les Recurrent Neural Networks, et peut-être uniquement les réseaux LTSMs (Long Term Short Memory), qui n'utilisent que les éléments proches), ou en utilisant des algorithmes basés sur les séquences ;
- Déployer notre modèle en production.
Ces étapes feront l'objet d'autres articles.
Conclusion
Nous disposons désormais d'un modèle relativement fiable pour automatiquement comprendre des fichiers structurés. Nous espèrons pouvoir utiliser le même modèle pour des fichiers moins structurés (ou de longs fichiers textuels).
Pour réaliser vos propres modèles, n'hésitez pas à suivre nos formations !

Drupal - SEO
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Python scientifique
A distance (FOAD) Du 15 au 19 juin 2026
Voir la Formation Python scientifiqueFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasActualités en lien
Notre expertise en Data science
Data Science
27/03/2019
L'IA est un domaine vaste et nos différents projets nous ont permis de monter en compétences sur plusieurs sujets. Cet article vous présente les thématiques pour lesquelles nous pouvons vous offrir notre expertise.
Initiation au Machine Learning avec Python - La pratique
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette seconde partie vous permet de passer enfin à la pratique avec le langage Python et la librairie Scikit-Learn !

Initiation au Machine Learning avec Python - La théorie
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette première partie se veut non technique et présente les concepts du Machine Learning, les différents types d'apprentissage et leurs principaux algorithmes. Il situe enfin Python dans cet univers en présentant les nombreuses librairies à votre disposition pour aborder cette discipline.
