Makina Blog
Machine learning : détection d'anomalies
Comment détecter des anomalies dans vos datasets en utilisant des algorithmes de machine learning.
Nous avons abordé dans notre article précédent l'import de données et sa classification automatique grâce à des algorithmes de machine learning. Mais depuis quelques années, le succès d'un algorithme de machine learning n'est atteint que si la précision dépasse 90%, et nous n'y sommes pas encore. Nous devons donc améliorer la précision de notre algorithme.
Nous allons voir comment nettoyer les données en écartant les anomalies, tout en restant vigilant sur ce que contiennent ces données mises de côté. Ce sera également l'occasion, après avoir abordé des algorithmes supervisés dans notre article précédent, de parler ici de machine learning non supervisé.
Qu'est-ce qu'une anomalie ?
Avant de chercher à les identifier dans notre jeu de données, réfléchissons à ce que nous considérons et appelons anomalie.
Il est important de garder en tête qu'une anomalie des données est toujours définie, implicitement ou explicitement, relativement à un modèle sous-jacent (c'est-à-dire une référence que l'on se donne).
Dans notre cas, il s'agit d'informations mal saisies dans des fichiers que nos clients nous envoient. Prenons l'exemple d'une colonne de codes postaux. Les adresses étant françaises, ils sont définis comme des nombres à cinq chiffres. Nous cherchons donc tous les enregistrements ne correspondant pas à ce modèle.
Nous pourrions facilement les identifier et les supprimer. Mais sans analyse de ces données écartées, il se pourrait que les anomalies qui nous dérangent contiennent une information importante que nous n'avons pas prise en compte. Dans notre exemple, ce pourrait être des adresses étrangères dont le code postal comporte des lettres, ou n'est pas dans le même format.
L'autre problème qui peut se poser en écartant trop de données est de renforcer les contraintes sur le modèle sous-jacent (sans même le vouloir). Cathy O'Neil nous donne dans sa conférence TED un exemple pour illustrer ce scénario : prenons l'exemple d'une société (Cathy O'Neil nous parle de FoxNews mais nous pouvons très bien dire de même d'une société en informatique) qui décide de remplacer sa procédure de recrutement par un algorithme. "Quelles seraient les données ? Un choix raisonnable serait les candidatures des 21 dernières années. Et la définition du succès ? Le choix raisonnable serait […] quelqu'un qui y est resté au moins quatre ans, qui a été promu au moins une fois. Ça m'a l'air raisonnable. Et puis l'algorithme serait mis au point. Mis au point pour sonder les gens, apprendre ce qui les a conduits au succès, quels types de candidatures ont historiquement mené au succès par cette définition. Pensez à ce qu'il pourrait se passer si on appliquait cela à un groupe actuel de candidats. Le filtrage éliminerait les femmes car elles ne ressemblent pas aux gens qui ont eu du succès dans le passé."
Un exemple qui rappelle les biais racistes des algorithmes de reconnaissance faciale. Pour aller plus loin, vous pouvez consulter l'ouvrage Armes de destruction mathématique de Cathy O'Neil ou l'article Sur les minorités et les anomalies de Brooke Foucault Welles.
Pour clore ce préambule, nous ne vous conseillerons donc jamais trop de prendre le temps d'analyser finement les données que vous écartez. Elles sont riches d'informations, peut-être même plus que le résultat que vous attendez de votre algorithme.
État de l'art
Comme d'habitude, avant de commencer à développer, nous avons regardé ce qui se pratiquait sur certaines plateformes de datascience et ailleurs, afin de voir si il n'existait pas une solution simple à notre besoin.
Dataiku : Machine Learning
Dataiku propose deux choses :
- La prise en compte ou non, dans les algorithmes de clusterisation, des "outliers" ;
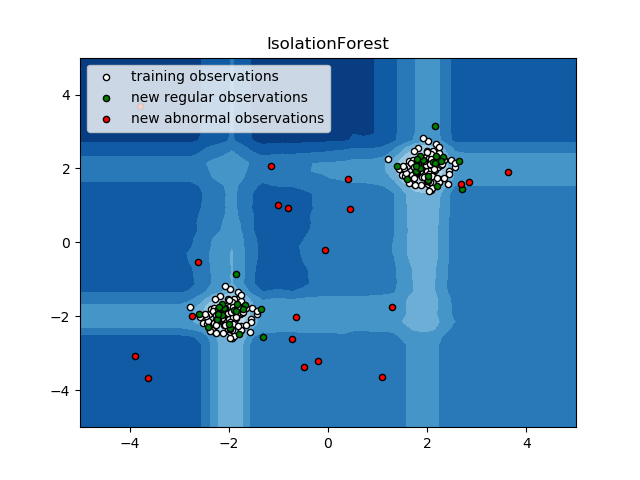
- La détection d'anomalies, basée sur un l'algorithme Isolation Forest :

Ça tombe bien, cet algorithme est implémenté dans scikit-learn, notre framework de prédilection :
RapidMiner
RapidMiner propose de vous accompagner grâce à un modèle de base de process de détection :
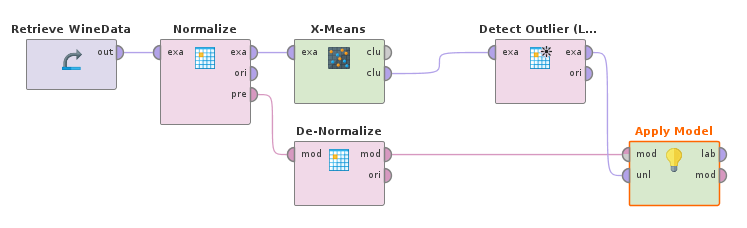
Après une phase de normalisation des données (par transformation en Z), ce modèle de base propose une clusterisation (de type K-Means) suivie d'un algorithme Local Outlier Factor qui donne un "score", utilisé ensuite pour filtrer les données après dénormalisation (dans le modèle par défaut, un score de 1.5 est utilisé comme limite).
Là encore, cet algorithme fait partie de ceux proposés par scikit-learn pour la détection d'anomalies :
H20 : Deep Learning
H20.ai utilise de son coté un auto-encodeur pour "comprendre" la structure des données, et permettre ensuite une détection d'anomalies. L'idée de l'auto-encodeur est un peu similaire à une PCA : on cherche à comprendre les caractéristiques discriminantes des données en propageant simplement les valeurs de l'entrée à la sortie, mais avec une couche interne de dimension inférieure à l'entrée (alors que la sortie est de même dimension que l'entrée) :
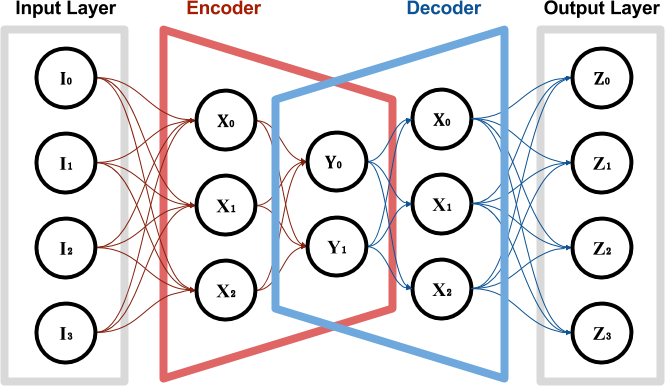
représentation schématique d'un réseau de neurones "auto-encodeur"
Une fois le modèle entrainé, il est éventuellement utilisable pour détecter les anomalies dans un ensemble de données. Par exemple, comme il essaie de conserver uniquement les informations principales, il élimine le "bruit" dans des données. Ci-dessous un exemple avec de la reconnaissance d'images :

Théorie générale
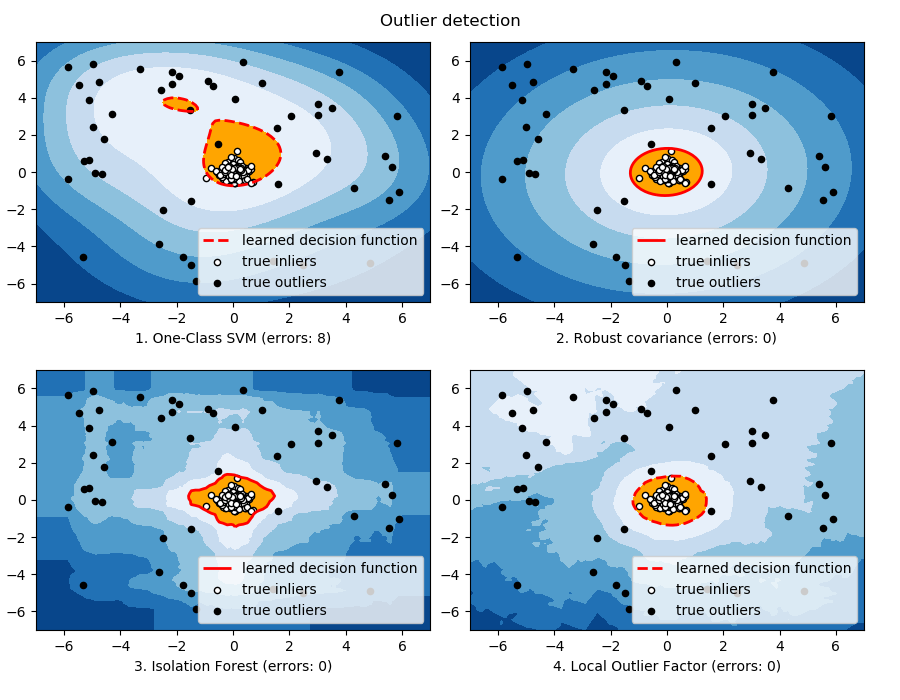
De manière plus générale, de nombreux algorithmes non-supervisés sont utilisables pour détecter des anomalies :

Je vous invite d'ailleurs avant de continuer à lire cet article référence sur le sujet ([EN]) : A Comparative Evaluation of Unsupervised Anomaly Detection Algorithms for Multivariate Data.
Notre approche
La plupart des algorithmes présentés dans la partie précédente fonctionnent plutôt bien quand ils sont entraînés sur des données "saines". Il détecte alors les anomalies dans les nouvelles données. Premier problème : nos données ne sont pas considérées comme saines, nous sommes d'ailleurs certains que nos données contiennent des erreurs.
De plus, une partie de ces algorithmes est basé sur des proximités (en utilisant différentes distances). Ils sont très utiles pour détecter des anomalies dans des listes de valeurs de même type (des séries numériques, par exemple).
Deuxième problème : dans notre cas, nous avons des données complètement différentes, parce qu'elles sont dans les mauvaises colonnes par exemple (des numéros de téléphones dans des colonnes d'adresses, …).
Ces algorithmes ne donnent donc pas des résultats très satisfaisants (ils éliminent une énorme partie des données d'entrée de nos fichiers, qui ne sont pas forcément des anomalies).
Nous avons donc du changer de méthode. Vu la richesse de nos données, nous avons tenté plusieurs choses :
Algorithmes de clusterisation
Nous avons tenté d'utiliser des algorithmes de clusterisation, qui souffrent du même problème que les autres algorithmes non supervisés : pour fonctionner de façon optimale, ils pré-supposent un entraînement sur des données saines. Dans notre cas, nous n'avons pas réussi à obtenir un résultat convaincant.
On peut tout de même signaler les algorithmes Birch (Balanced Iterative Reducing and Clustering using Hierarchies) et DBSCAN (Density-Based Spatial Clustering of Applications with Noise) qui sont prévus pour gérer des données comportant du bruit.
Dans notre cas, ils ont tout de même éliminé beaucoup trop de données (y compris des données totalement valides). Un des problèmes de DBSCAN est qu'il n'est pas prévu pour gérer des clusters trop dissemblables, et on peut espérer que son évolution OPTICS (Ordering Points To Identify the Clustering Structure), dont l'implémentation est en cours dans scikit-learn, sera plus efficace pour notre situation :
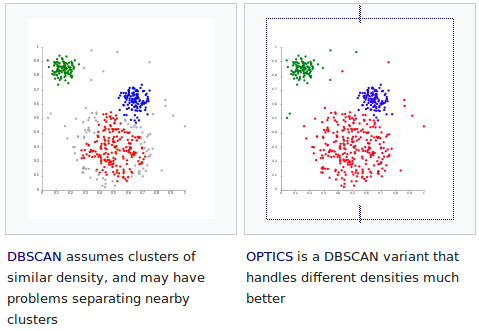
Topologies
Il existe également un algorithme permettant de détecter des anomalies en utilisant des graphes :
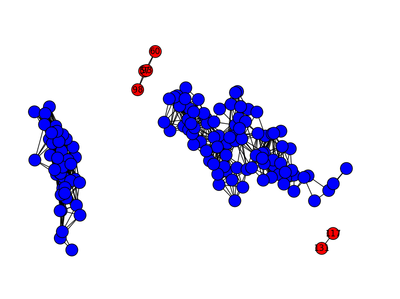
Nous ne l'avons pas testé.
Tout n'est pas si noir
Notre tentative de détection d'anomalies de façon non-supervisée avant classification n'a pas fonctionné. Mais :
- D'une part, nous utilisons (comme vu à l'article précédent) un algorithme "ensembliste" (qui combine plusieurs sous-algorithmes) ;
- D'autre part, la précision estimée de notre classifieur n'est pas brute, mais issue d'une validation croisée.
Ces deux facteurs nous donnent une certaine tolérance aux anomalies de notre dataset. Nous allons tout de même essayer de les détecter / corriger, mais après une première classification.
Détection d'anomalies post-classification
Pour chaque élément de notre fichier, initial, nous calculons la probabilité que l'élément appartienne à une classe, pour chacune des classes disponibles ("url", "numéro de téléphone", "prénom", "adresse", …). Ensuite, nous sommons ces probabilités sur une colonne de notre fichier initial, qui n'est sensée contenir que des éléments de même type (= "classe" en vocabulaire machine learning).
Nous en déduisons alors que la probabilité majoritaire de la colonne désigne le "vrai" type de la colonne, et les éléments où cette probabilité n'est pas majoritaire sont alors détectés comme des "anomalies".
À nous maintenant d'implémenter une correction !
Conclusion
À vous de pratiquer, maintenant. Vous pouvez également nous contacter pour réaliser vos projets de machine learning, ou tout simplement progresser en suivant notre formation de Machine Learning.

Drupal - SEO
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasActualités en lien
Comment réussir son projet de machine learning ?
Data Science
29/04/2018
Voici quelques retours d'expérience et des indications pour vous aider à réussir vos projets de machine learning

Machine Learning : classer automatiquement vos données à l'import
Data Science
22/02/2018
Comment utiliser des algorithmes de machine learning pour importer correctement des données dans vos projets de DataScience ?

Initiation au Machine Learning avec Python - La théorie
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette première partie se veut non technique et présente les concepts du Machine Learning, les différents types d'apprentissage et leurs principaux algorithmes. Il situe enfin Python dans cet univers en présentant les nombreuses librairies à votre disposition pour aborder cette discipline.
