Makina Blog
Comment réussir son projet de machine learning ?
Voici quelques retours d'expérience et des indications pour vous aider à réussir vos projets de machine learning
Aujourd'hui, de nombreux projets de machine learning se lancent. Si vous aussi vous prévoyez d'intégrer un peu de machine learning dans votre fonctionnement, voici quelques conseils ou retours d'expérience sur ce sujet.
Les différentes phases d'un projet de machine learning
Contrairement à ce qu'on pense, la phase purement algorithmique n'est pas forcément le plus importante du projet. En effet, la partie la plus importante concerne la récupération et le traitement des données.
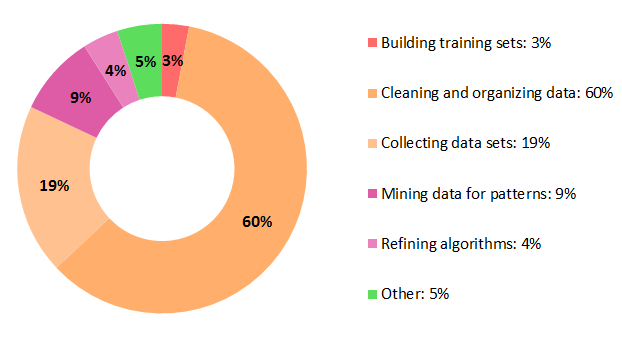
D'abord, regardez les données !
Notamment, ne vous lancez pas à l'improviste, commencez par visualiser les données pour vous faire une idée de ce qu'il sera possible de réaliser dans vos modèles :

Pour cette étape, la bibliothèque Matplolib est souvent utilisée ou des surcouches comme Seaborn qui propose notamment la fonction pairplot(), qui compare deux à deux les variables pour estimer les corrélations, distributions et éventuelles clusterisations de ces variables :
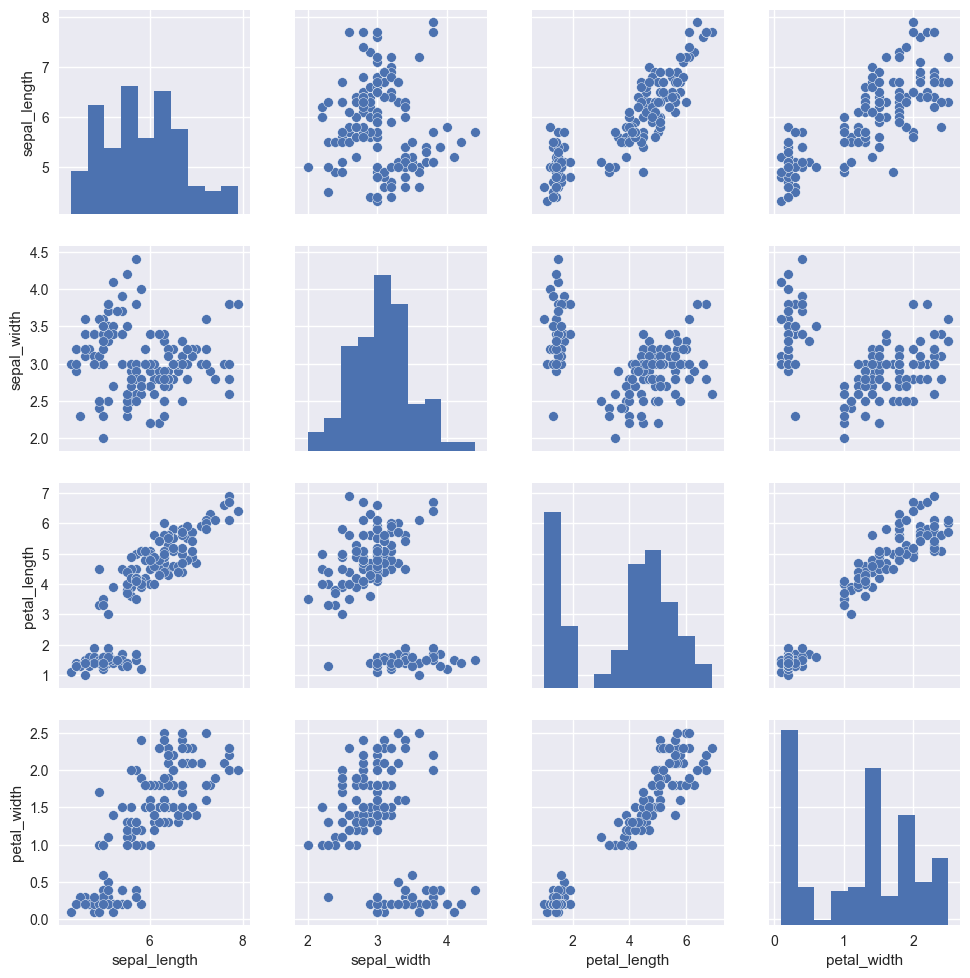
Exemple : le jeu de données "Iris" utilisé classiquement pour démontrer certains travaux. On constate par la simple visualisation que nous devrions réussir à identifier 2 clusters parmi les données ou que l'utilisation d'algorithmes de classification simple devrait suffire, les données étant clairement séparables.
Ces visualisations permettent notamment d'indiquer par quelles variables commencer vos travaux de recherche ou s'il existe un espoir d'arriver à quelque chose avec des algorithmes non supervisés.
Cela permet également de pouvoir identifier des distributions gaussiennes (par exemple), ce qui conditionnera éventuellement le choix des algorithmes supervisés ensuite.
Différence entre algorithmes supervisés et non supervisés
Les algorithmes supervisés utilisent des données "d'apprentissage" - qui sont labellisées- pour faire émerger des règles qui permettront ensuite de faire des prédictions sur de nouvelles données.
Les algorithmes non supervisés ne nécessitent pas de données d'apprentissage. Ils consitent souvent à explorer les données pour en découvrir la structure (on trouve notamment les algorithmes de clusterisation, mais pas que).
Volume de données
Mais au-delà de la représentation des données dans le cadre d'un projet de machine learning, la répartition par classes de ces données ou le volume total de données disponibles, permet d'estimer les possibilités d'obtenir un résultat significatif en utilisant des algorithmes de machine learning.

Par exemple, inutile d'essayer un réseau de neurones sur quelques dizaines de données.
Cela dit, il existe également des techniques pour augmenter artificiellement son volume de données, notamment dans le domaine du traitement d'images. On peut par exemple utiliser des effets miroirs, flous, …
Aujourd'hui, on trouve même des techniques "d'augmentation automatique". À suivre !
Qualité des données
Là encore, la visualisation des données permet d'estimer si le fichier de données contient des données uniformes ou si de nombreuses anomalies sont présentes. Cela permet également de conditionner le choix de certains algorithmes plus ou moins tolérants aux anomalies.
PCA ou pas ?
Chaque donnée est décrite par un ensemble de N variables. Chaque variable correspond à un aspect de la donnée représentée par une valeur numérique. Ces N valeurs numériques sont regroupés dans un vecteur : le descripteur.
Plus la taille du descripteur augmente, plus les temps d'exécution de la méthode de machine learning augmente, notamment durant l'apprentissage. En outre, s'ils existent des corrélations entre certaines variables, la méthode a du mal à apprendre correctement et les résultats peuvent s'avérer décevants.
L'Analyse en Composante Principale ou PCA - de l'anglais Principal Component Analysis - permet de réduire les corrélations des données. Concrètement, l'ensemble des descripteurs correspondent à des points dans un espace à N dimensions. La PCA recherche une transformation vers un autre espace à N dimensions où les N variables résultats ne sont plus corrélés.
Cerise sur le gâteau, ses dimensions sont ordonnées de manière à ce que les premières dimensions contiennent le maximum d'information. Il est donc possible de ne conserver que les M premières variables, tout en conservant un descripteur contenant la majorité des informations présentes dans les données initiales.
Pour autant, la PCA est un traitement supplémentaire : plutôt que de l'appliquer systématiquement et d'augmenter les temps de calcul, il vaut mieux vérifier son utilité.
Stratégie
En considérant l'objectif de votre projet et les données dont vous disposez, il est important de choisir la stratégie à utiliser dans le projet.
Ne pas utiliser de machine learning
On l'oublie souvent, mais c'est parfois une stratégie tout à fait acceptable. Cet article recommande même de toute façon par commencer à créer un modèle utilisant le bon sens.
Supervisé ou Non-supervisé ?
Si vous êtes convaincu d'obtenir des résultats en utilisant du machine learning, vous avez le choix entre apprentissage non-supervisé ou supervisé (même si de récentes évolutions pensent que la combinaison des deux peut fournir le plus d'avancées dans le domaine) :
Cela va dépendre en partie de la nature du problème à traiter, mais également beaucoup des données. En effet, on continue de s'apercevoir à quel point la visualisation initiale des données guide l'ensemble du projet.
Un modèle stupide
Ensuite, commencez par un modèle stupide !
Ce modèle va vous permettre de mettre en place tout le reste de votre traitement : les pipelines (suite de traitement à effectuer pour vos données), de préparer et tester votre déploiement… En bref, toutes les tâches en dehors du raffinage de l'algorithme.
Apprentissage par transfert
Si jamais vous ne disposez pas d'assez de données pour entraîner complètement un modèle, il est envisageable d'utiliser un "apprentissage par transfert".
Ainsi, vous récupérez un réseau de neurones entraîné sur un autre ensemble que le vôtre. En suivant l'hypothèse que les premières couches du réseau essaient de distinguer des caractéristiques génériques des données, vous remplacez les dernières couches du réseau pour essayer d'y insérer des couches que vous allez entraîner avec vos données pour essayer d'adapter le réseau :
![]()
L'API de Keras - surcouche à par exemple Tensforflow - vous permet de faire ce genre d'opération.
Algorithmes
Comme vu précédemment, l'algorithme n'est pas forcément la partie à laquelle vous consacrez le plus de temps. D'une part, parce que de nombreux algorithmes et leurs cas d'utilisation sont désormais bien connus. D'autre part, parce que le développement de l'automatic machine learning permet d'automatiser cette étape, comme expliqué dans l'article sur la classification de données.
Évaluer l'algorithme utilisé
Quel que soit l'algorithme utilisé, la première étape est d'évaluer correctement son résultat (en dehors du résultat brut : classe, valeur…). On retrouve ici l'idée de visualiser notre travail, partie importante des projets de data-science.
Chaque famille d'algorithmes dispose ainsi de différentes métriques pour estimer son efficacité :
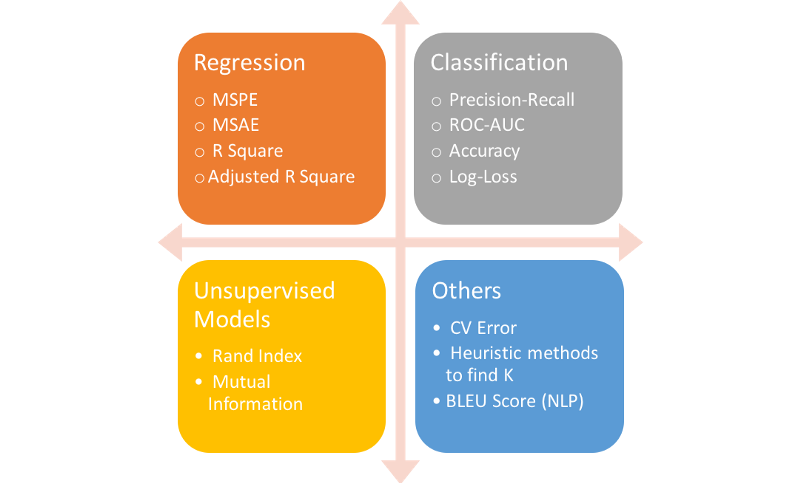
Pourquoi est-ce si important ?
En plus de connaître l'efficacité brute de votre modèle :
- il est primordial de comprendre comment il se trompe, quand il se trompe, afin soit de rejeter en bloc son utilisation (dans le domaine de la santé, un modèle qui génère des faux négatifs est inutilisable, par exemple)
- soit d'ajuster le travail préalable sur vos données pour compenser certaines faiblesses de votre modèle
Des "hacks"
"Part of ML is good grasp of theory, part of ML is a good grasp of what hacks tend to work." (William W. Cohen)
Par exemple, pour l'analyse de texte, TF-IDF - surtout IDF - est très souvent utile, même si on ne comprend pas très bien pourquoi.
De même, les algorithmes baysiens naïfs fonctionnent de façon efficace dans de nombreuses situations.
S'inspirer de ce qui existe
La plupart des avancées en machine / deep learning sont publiquement mises en ligne :
- soit avec des bouts de code - souvent sur Github
- soit par des pré-papiers de recherche, sur arXiv
Il est donc tout à fait possible de s'inspirer de ce qui existe pour accélérer les premiers développements de votre modèle. Un annuaire de modèles a même récemment fait son apparition, pour permettre d'identifier rapidement ce qui est disponible dans votre domaine : vision par ordinateur, traitement du langage naturel, etc.
Egalement à consulter des exemples de projet sur Seedbank, proposés par Google.
Comme tous les domaines techniques, il faut faire de la veille, surtout au vu des évolutions très rapides du domaine. Là encore, un petit "hack" : vous pouvez aussi lire les butinages Makina Corpus ;-)
Un canvas
Suivant l'inspiration du Business Model Canvas, il existe également un Canvas pour le machine learning :
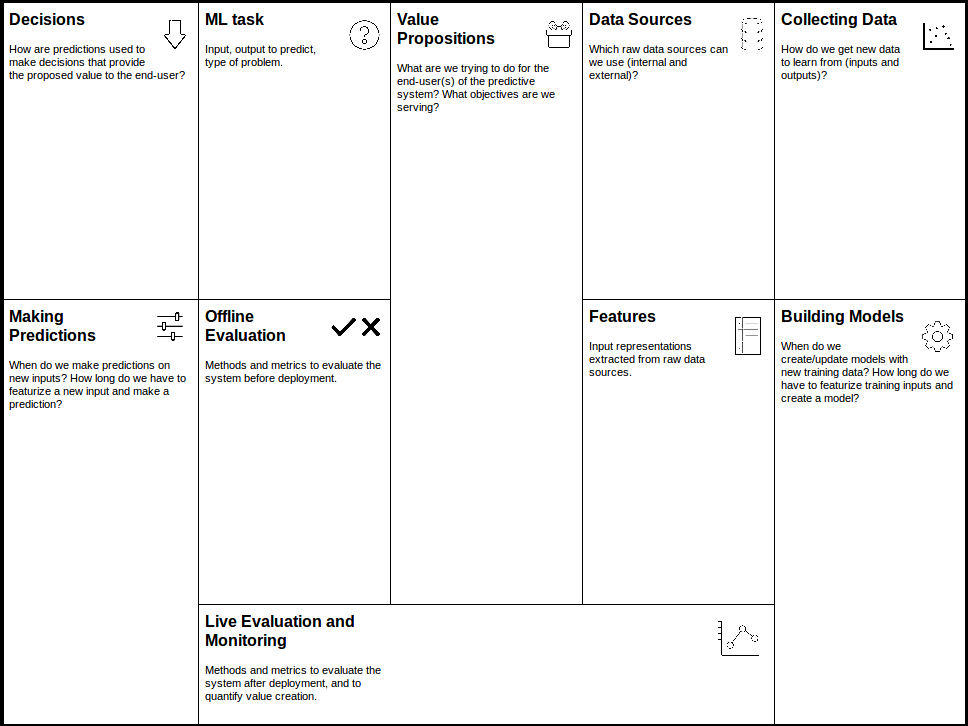
Sans être parfait, c'est un bon outil pour penser méthodiquement aux différents points de votre projet et mettre toutes les chances de votre côté.

Drupal - SEO
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningActualités en lien
Machine Learning : classer automatiquement vos données à l'import
Data Science
22/02/2018
Comment utiliser des algorithmes de machine learning pour importer correctement des données dans vos projets de DataScience ?

Scraping & Machine Learning : comment fonctionne un moteur de recherche ?
Python
19/12/2017
Ou comment utiliser des composants libres pour faire votre mini-Google (ou Qwant)
Initiation au Machine Learning avec Python - La théorie
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette première partie se veut non technique et présente les concepts du Machine Learning, les différents types d'apprentissage et leurs principaux algorithmes. Il situe enfin Python dans cet univers en présentant les nombreuses librairies à votre disposition pour aborder cette discipline.
