Makina Blog
Mise en correspondance de données textuelles hétéroclites
Lors de la mise en place d'une application web, il n'est pas rare de devoir manipuler des données décrivant des objets similaires mais provenant de sources variées. Du fait qu'elles ont été créés par des organismes différents, un même objet peut avoir des descriptions textuelles proches sans être identiques.
La mise en correspondance de ces données textuelles est une problématique classique dans les sites qui proposent des produits venant de fournisseurs différents. Mais en réalité, cette thématique touche des domaines d'applications beaucoup plus vastes et pas nécessairement commerciaux. Ainsi, si une région souhaite proposer un moteur de recherche pour mettre en avant les évènements se déroulant sur son territoire, il lui sera utile de disposer d'un outil permettant de faire le lien entre des descriptifs concernant le même organisateur ou la même activité, mais pouvant présenter des différences : nom abrégé ou en version longue, informations qui ne sont pas données dans le même ordre, etc.
Depuis deux ans, l'équipe de Makina Corpus réfléchit à des solutions intelligentes permettant d'adapter des données textuelles créées par des humains (avec toute la variété et les erreurs qu'elles peuvent contenir) aux nécessités des applications informatiques. Dans ce cadre, nos Data Scientists s'intéressent tout particulièrement aux outils de Machine Learning adaptés au traitement du langage naturel (NLP, de l'anglais Natural Language Processing).
Un cas d'application concret
C'est dans le cadre d'un projet pour le Groupe Dubreuil que l'équipe Makina Corpus travaille sur des données correspondant à une problématique concrète avec un double objectif :
- concevoir une solution pour associer des données provenant de diverses sources à un référentiel créé et maintenu par le Groupe Dubreuil ;
- concevoir des outils pour aider à créer et mettre à jour le référentiel.
Les données textuelles à disposition correspondent à des marques et des modèles, c'est-à-dire des chaînes de caractères courtes pouvant être issues de plusieurs langues (français, anglais, allemand, etc.). À noter également, la majorité des mots utilisés sont des noms propres absents des lexiques usuels. Les outils prêts à l'emploi en NLP ne sont donc pas exploitables, car conçus pour des corpus trop éloignés.
Données textuelles et Machine Learning
Contrairement à d'autres types de données (mesures, images, vidéos, signal audio, etc.), les données textuelles ne peuvent pas être utilisées directement par une méthode de Machine Learning. Il faut d'abord les convertir sous une forme numérique. Une manière rapide consiste à associer un nombre à chaque mot, par exemple :
- 1 - LOGICIEL ;
- 2 - PYTHON ;
- 3 - WEB ;
- 4 - SCIENTIFIQUE ;
- 5 - SERPENT ;
- 6 - LIBRE.
Cependant cette manière de procéder ne permet pas à la méthode de Machine Learning de savoir que les termes « LOGICIEL » et « LIBRE » sont plus proches que « LOGICIEL » et « SERPENT ».
Les réseaux de neurones de type Word2Vec ont été conçus pour résoudre cette problématique. Ils permettent d'associer un vecteur numérique à chaque mot, de manière à ce que des mots proches soient représentés par des vecteurs proches.
Le principe est relativement simple :
- un entier est associé à chaque terme (comme vu précédemment) ;
- le réseau de neurones reçoit en entrée deux mots, chacun étant décrit par un entier numérique (comme dans l'exemple précédent) ;
- le réseau convertit chacun des deux entiers en un vecteur numérique de manière à prédire correctement la probabilité que deux mots soient présents dans la même phrase, à une distance inférieure à un seuil donné.
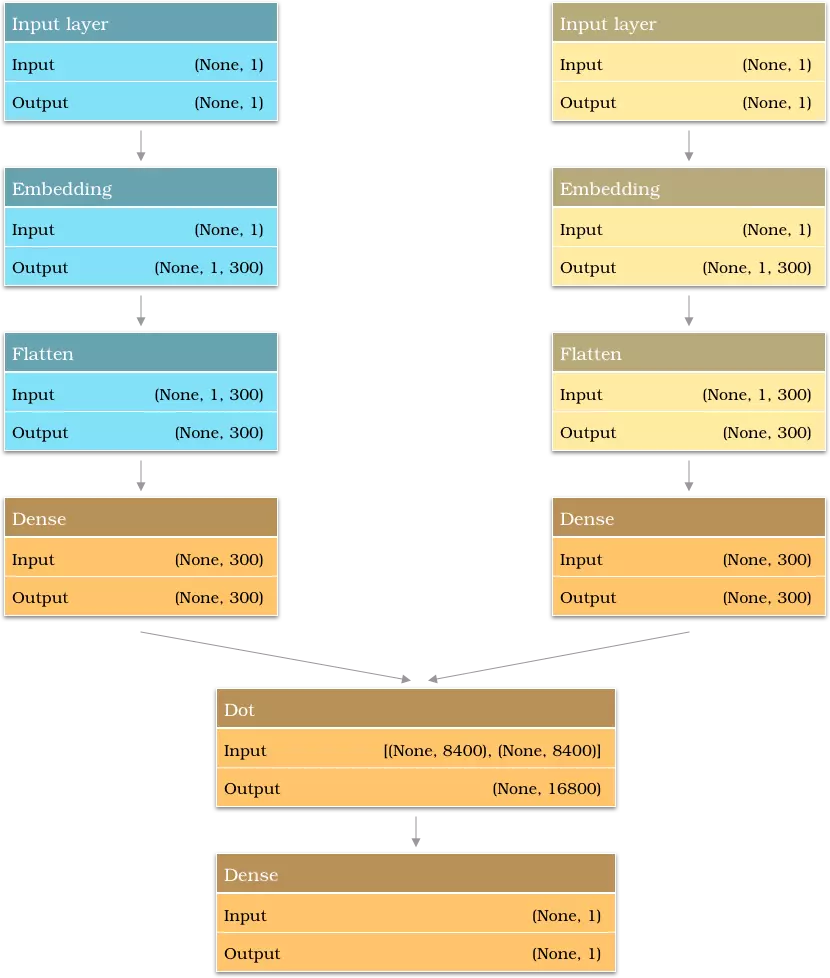
Architecture d'un réseau de neurones de type WordVec. Une fois le modèle entraîné, seule la partie bleue est conservée : elle permet de convertir un mot en vecteur numérique.
Les réseaux de neurones Word2Vec sont entraînés à partir d'un corpus. Pour poursuivre avec l'exemple, si le modèle Word2Vec est entraîné avec un corpus issu du domaine informatique les mots « PYTHON » et « SCIENTIFIQUE » seront sans doute fréquemment associés, incitant le réseau à leur donner des vecteurs numériques permettant de leur associer une probabilité de co-apparition importante. Au contraire, les mots « PYTHON » et « SERPENT » seront moins fréquemment associés. Si nos Data Scientists utilisent un corpus générique où l'association « PYTHON » et « SERPENT » est davantage présente, les vecteurs numériques seront modifiés.
Point important : le réseau de neurones ne sait convertir que les mots du corpus utilisés pour son apprentissage.
Constitution d'un lexique
L'exemple donné repose sur des mots issus de la langue française. Comme expliqué précédemment, dans le cas des données fournies par le Groupe Dubreuil, l'emploi d'un tel lexique n'est pas pertinent.
En outre, le découpage des noms de marques et de modèles en mots n'est pas nécessairement pertinent. Il existe peu de mots en commun entre les marques ou les modèles. Les exceptions correspondent souvent à des termes comme « INTERNATIONAL », qui ne permettent pas de savoir si deux groupes de mots correspondent à un même marque ou à des marques distinctes.
L'équipe a donc choisi de décomposer les marques et modèles en groupes de deux ou trois caractères aussi appelés N-grammes.
Exemple de décomposition en 2-grammes |
Exemple de décomposition en 3-grammes |
|---|---|
|
|
Les N-grammes les plus fréquents ont été uniquement conservés, ce qui donne le lexique. Ce dernier a été complété avec les caractères de l'alphabet utilisés pour être certain d'être toujours en mesure de décrire les noms de marques et de modèles comme une combinaison de N-grammes.
Ce sont ces N-grammes qui ont été transformés en vecteurs numériques à partir du réseau de neurones Word2vec. Ainsi, cela garantit que même si de nouveaux produits sont ajoutés (constitué de marques et de modèles non connus par le modèle de mise en correspondance) il sera possible de le transformer en vecteurs numériques de la manière suivante :
- décomposer la marque ou le modèle en N-grammes du lexique ;
- transformer chaque N-grammes en vecteurs numériques ;
- faire la somme de ces vecteurs pour obtenir un vecteur numériques pour la marque ou le modèle.
Réseau de neurones pour réaliser la mise en correspondance
Une fois chaque nom de marque ou de modèle décrit par un vecteur numérique, ils peuvent être utilisés avec une méthode de Machine Learning pour estimer la probabilité que deux éléments écrits différemment décrivent le même produit.
L'équipe Makina Corpus s'est orientée vers un réseau de neurones à l'architecture simple, pour conserver un temps d'apprentissage et de traitement des données court. Il s'agit d'une architecture siamoise : la donnée de référence et une possible variante subissent en parallèle la même pré-analyse qui permet d'en extraire les informations. Les résultats pour les deux chaînes de caractères sont concaténés et le réseau réalise une dernière analyse grâce à l'alternance de couches de convolution et de sous-échantillonnage.
Ce réseau nécessite environ trois millions de données pour apprendre à associer des variantes à un millier de données de référence. Ce nombre de données élevé s'explique par le fait que le réseau ne doit pas seulement apprendre à déterminer si une chaîne de caractères est une variante d'une donnée de référence : il doit aussi déterminer quand deux chaînes de caractères ne correspondent pas au même produit. En conséquence, Il est important que les données d'apprentissage comportent de nombreux exemples de chaînes de caractères ne devant pas être mises en correspondance.
Mise en place d'un apprentissage actif
Le nombre de données nécessaires pour entraîner le réseau de neurones augmente significativement quand de nouvelles données de référence sont intégrées. Les Data Scientists se sont donc penchés sur des techniques d'apprentissage actif.
Les procédures d'apprentissage actif ont été pensées pour des problématiques où de nombreuses données sont disponibles, mais où un travail conséquent est nécessaire et très coûteux afin d'obtenir une vérité terrain.
Le principe général de cette approche est décrite par l'illustration ci-dessous :

Procédure standard d'apprentissage actif.
La méthode de Machine Learning est entraînée à partir d'un petit ensemble de données pour lequel la vérité terrain est constituée. Une fois la méthode entraînée, elle est utilisée pour réaliser une prédiction pour les données sans vérité terrain. L'objectif des procédures d'apprentissage d'actif est d'utiliser les prédictions pour détecter parmi les données restantes quelles sont celles qui permettront la meilleure progression de la méthode de Machine Learning.
Dans notre cas, la vérité terrain est à disposition, mais l'équipe souhaite utiliser les techniques d'apprentissage actif pour réduire le nombre de données à fournir au réseau, en éliminant les données à faible valeur d'apprentissage.
Il a été choisi :
- d'entraîner le réseau avec un ensemble restreint de données ;
- de sélectionner parmi les données restantes celles correspondant à des mises en correspondance que le réseau détecte mal (i.e. des variantes de la donnée de référence difficiles) ;
- de sélectionner parmi les données restantes celles correspondant à des données pour des produits différents que le réseau a tendance à vouloir associer ;
- de poursuivre l'apprentissage du réseau en ajoutant ces nouvelles données aux données de base.
Vers une application fonctionnelle
Les outils de Machine Learning développés par Makina Corpus ont pour premier objectif de faciliter la création d'une table de correspondance, indiquant pour chaque désignation d'un produit une désignation de référence. Cette table permet de faire le lien entre des données de sources différentes. Il est fondamentale qu'elle ne comporte pas d'erreur. Elle pourra ensuite être utilisée pour créer des applications puissantes.
La méthode de Machine Learning conçue permet de déterminer pour un couple de données, quelle est la probabilité que le couple de données désigne un même produit. Elle est utilisée pour comparer chaque nouvelle donnée à l'ensemble des données de référence afin de repérer quelles sont les mises en correspondance possible. L'opérateur humain reçoit cette liste et doit déterminer la correspondance la plus pertinente.
Le fait que la méthode de Machine Learning développée fonctionne de manière supervisée est intéressant à plusieurs égards :
- dans les prochains mois les retours utilisateurs permettront d'augmenter significativement nos données d'apprentissage, ce qui améliorera les performances de la solution de mise en correspondance ;
- ce travail ne se limite pas à la conception d'une méthode de Machine Learning appropriée : il conduit également une réflexion pour l'intégrer de manière pertinente dans une application web afin de faciliter le travail de l'opérateur humain.
Ce dernier point est un aspect qui tient particulièrement à cœur de l'équipe Makina Corpus. "Nous sommes convaincus que se focaliser sur la question de la performance d'une méthode de Machine Learning n'est pas une approche efficace. Lors de la conception de cette méthode, il est au contraire essentiel de prendre en compte le contexte global de sa mise en place, afin de l'intégrer de manière harmonieuse aux processus métiers tout en impliquant les futurs utilisateurs au processus de réflexion."
L'un des principaux freins à l'acception du Machine Learning réside dans son aspect boîte noire : aussi appréciable que soient les services qu'il rend, ils n'arrivent pas à faire oublier la frustration quand une méthode de Machine Learning se trompe de manière inexplicable. Réfléchir à l'intégration de cette méthode au sein d'une application qui permette de rendre son utilisation sécurisée et intuitive est donc une composante essentielle de notre métier.
Conclusions
Ce projet pour le Groupe Dubreuil offre la possibilité de travailler sur une thématique intéressante : le nettoyage et la mise en forme de données avant de les intégrer au sein d'une application web. Ce projet complexe a sollicité un savoir inter-disciplinaire intégrant des experts en IA, en développement web et en interface utilisateur.
En termes de retombées, ce projet permet à Makina Corpus de relancer Smart Import (des nouvelles courant 2020). À plus court terme, notre formation Deep Learning à été mise à jour en prenant en compte ces nouvelles avancées. De nouvelles actualités sont à venir sur ce sujet de "Mise en correspondance de données textuelles hétéroclites" !

Experte data science
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Python scientifique
Toulouse Du 21 au 25 septembre 2025
Voir la Formation Python scientifiqueActualités en lien
Notre expertise en Data science
Data Science
27/03/2019
L'IA est un domaine vaste et nos différents projets nous ont permis de monter en compétences sur plusieurs sujets. Cet article vous présente les thématiques pour lesquelles nous pouvons vous offrir notre expertise.
Machine Learning : classer automatiquement vos données à l'import
Data Science
22/02/2018
Comment utiliser des algorithmes de machine learning pour importer correctement des données dans vos projets de DataScience ?

Initiation au Machine Learning avec Python - La théorie
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette première partie se veut non technique et présente les concepts du Machine Learning, les différents types d'apprentissage et leurs principaux algorithmes. Il situe enfin Python dans cet univers en présentant les nombreuses librairies à votre disposition pour aborder cette discipline.
