Makina Blog
Structurer des données géographiques de manière arborescente avec PostgreSQL et ltree
Lorsque l'on souhaite visualiser des données géographiques provenant de sources abondantes et hétérogènes, une approche permettant d'améliorer la navigation dans le jeu de données peut être de hiérarchiser ces données par des catégories et de visualiser ces catégories de manière arborescente.
Par exemple, nous pouvons utiliser la taille de l'entité géographique pour fabriquer une arborescence allant de la taille la plus importante à la moins importante : pensez 'Pays' > 'Région' > 'Département'. Ainsi, en naviguant dans cette arborescence, les personnes peuvent spécifier de manière plus ou moins précise la catégorie des données qu'elles souhaitent visualiser.
Voici une vidéo illustrant le fonctionnement d'un tel système pour l'utilisateur :
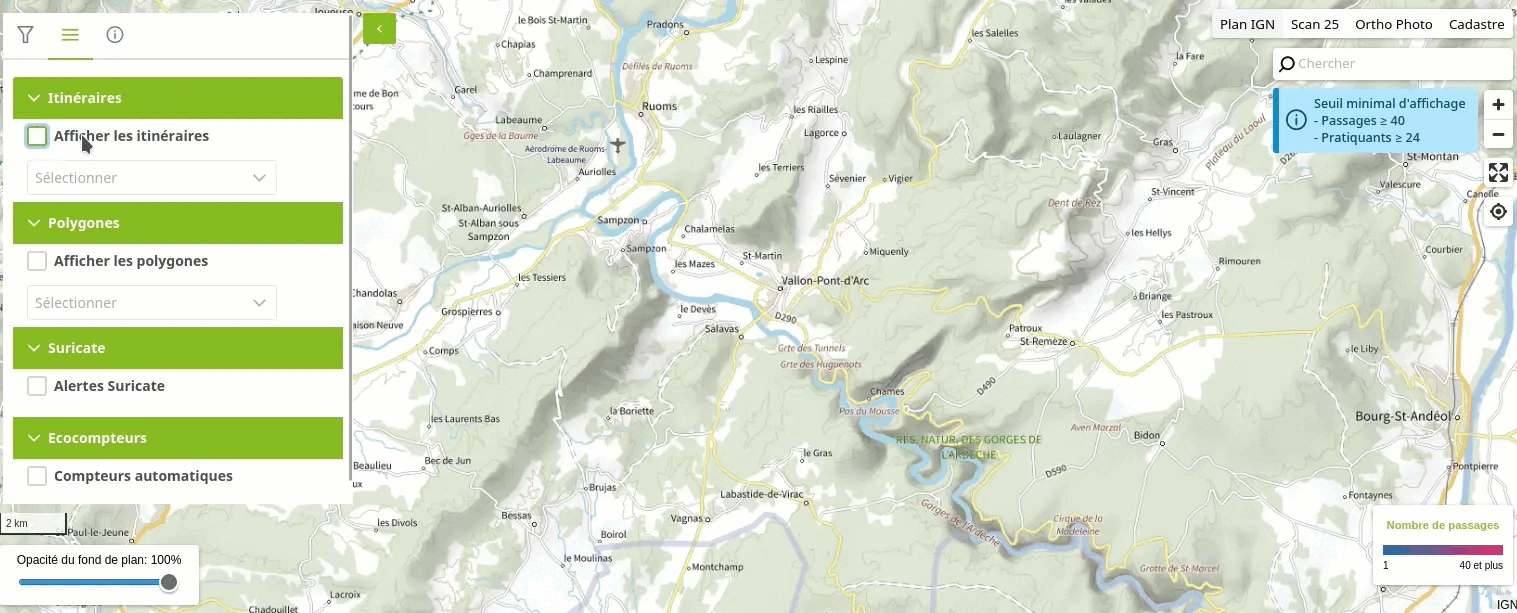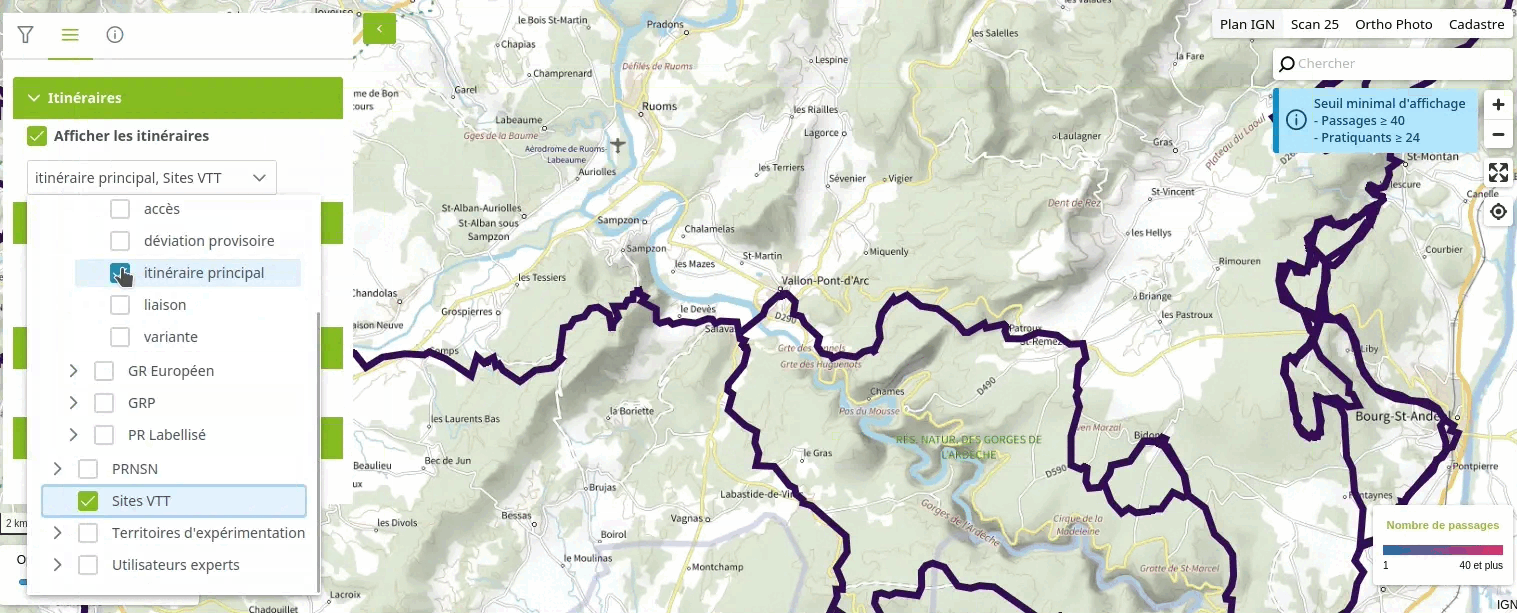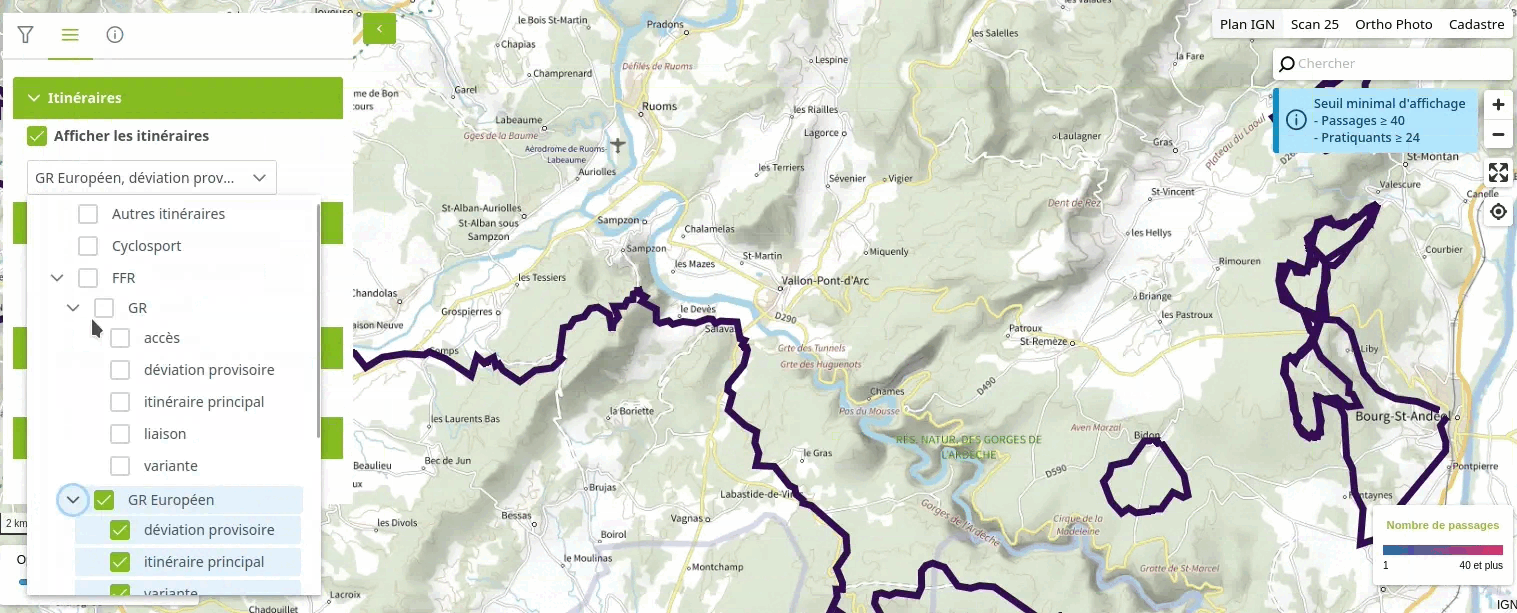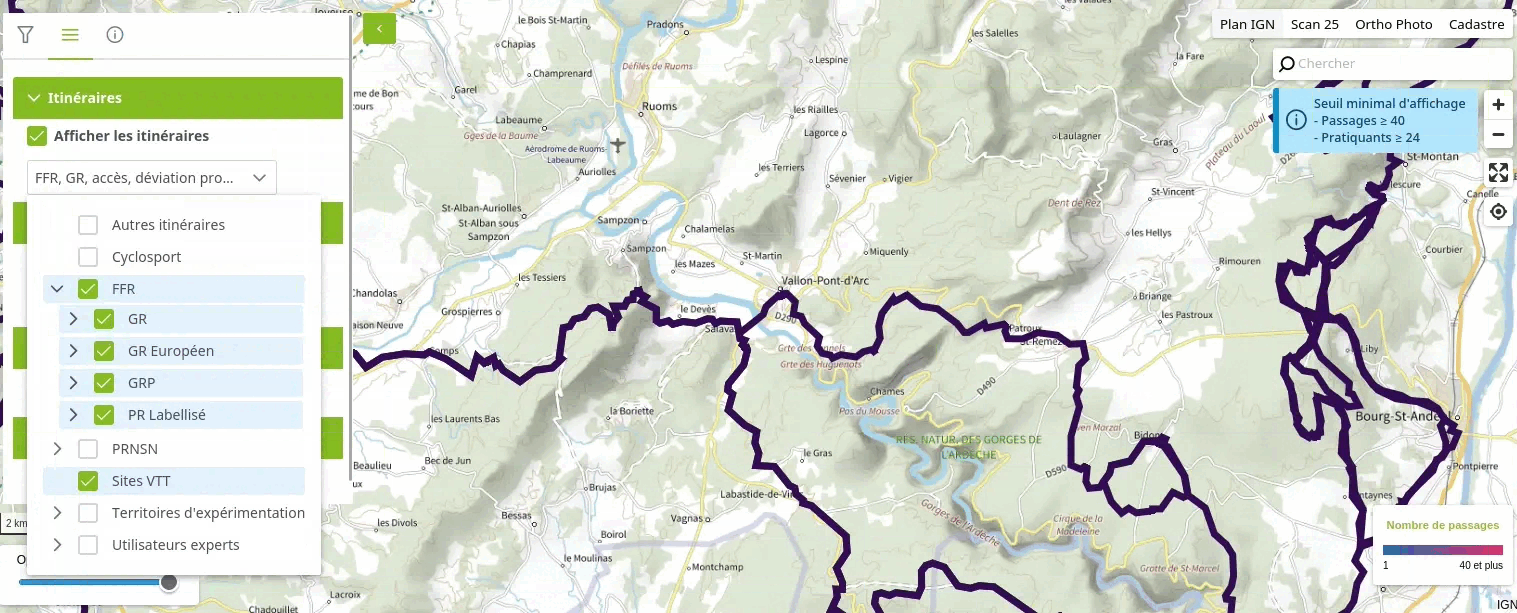
Dans cet article, je vous présente comment utiliser l'extension ltree de PostgreSQL pour créer une hiérarchie arborescente de catégories sur un jeu de données géographiques. Cette technique marche aussi avec des données non-géographiques.
Toutes les requêtes présentées dans cet article sont disponibles sur github, dans le repository suivant : makinacorpus/article_arborescence_postgres_ltree. Vous y trouverez aussi dans les releases, le dump de données pour suivre cet article.
Au court de cet article, vous allez partir d'un jeu de données où l'information d'arborescence est déjà en place sous forme textuelle. Nous allons transformer cette information pour que PostgreSQL comprenne comment est structuré votre arbre. Cela nous permettra d'interroger nos relations arborescentes en utilisant uniquement du SQL ! De plus, nous pourrons combiner la sémantique des requêtes ltree avec des requêtes géographiques.
Mise en place de la base de données
Tout au long de cet article, je vais utiliser une base de données contenant des itinéraires de parcours sportifs. Nous allons donc enrichir cette base de données pour créer la représentation suivante :
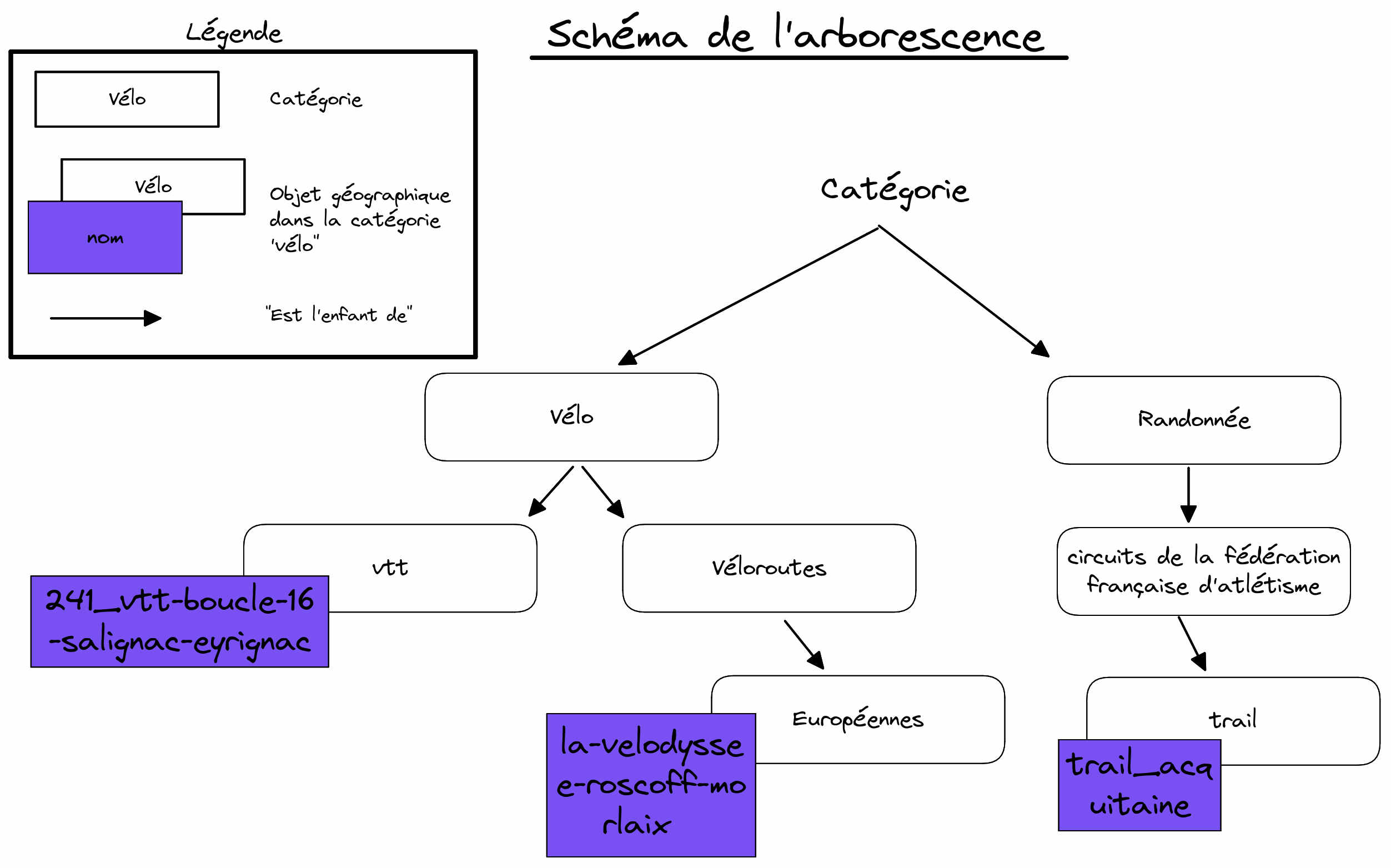
Le dump est téléchargeable ici.
Commençons par préparer une base de données PostgreSQL pour charger le dump. Ouvrez une console psql avec votre utilisateur administrateur du SGBD et exécutez les commandes suivantes pour créer l'utilisateur article et la base de données article.
CREATE USER article WITH ENCRYPTED PASSWORD 'article';
CREATE DATABASE article WITH OWNER article;
set role article; -- Nous basculons sur notre role applicatif
\c article -- Nous nous connectons à la base
Maintenant, nous allons activer les extensions PostgreSQL qui sont nécessaires pour implémenter notre fonctionnalité. Les extensions étant activées au niveau d'une base, il vous faut ouvrir la base que nous venons de créer. Pour cela, ouvrez une nouvelle console avec l'utilisateur que nous venons d'ajouter et créez les extensions suivantes :
CREATE EXTENSION ltree;
CREATE EXTENSION postgis;
CREATE EXTENSION "uuid-ossp"; -- Nous allons manipuler des identifiants uniques par la suite
Vous pouvez désormais restaurer le dump avec la commande suivante :
pg_restore -x -U article -d article article.dump
Ce dump contient une table 'iti_tmp_import' avec les colonnes suivantes :
Column | Type | Collation | Nullable | Default
--------+--------------------------------+-----------+----------+---------
path | text | | |
name | text | | |
id | text | | |
geom | geometry(MultiLineString,3857) | | |
Indexes:
"idx_iti_tmp_import_geom" gist (geom)
"iti_tmp_import_id_idx" btree (id)
Nous y retrouvons 3 lignes, contenant chacune :
- un identifiant (
id) - un nom (
name) - une géométrie (
geom) - un chemin (
path) qui représente le chemin jusqu'au nœud de l'arbre auquel notre entrée est rattachée. Ce chemin est matérialisé sous la forme d'une chaîne de caractères de type text. Cette chaîne définit une liste de nœuds séparés par des points, chaque nœud étant l'enfant du nœud précédent. Par exemple, si nous avons l'entrée A qui a pour path :vélo.vtt.sitesvttet l'entrée B qui a pour pathvélo.route.véloroutes européennesalors nous avons l'arbre suivant :
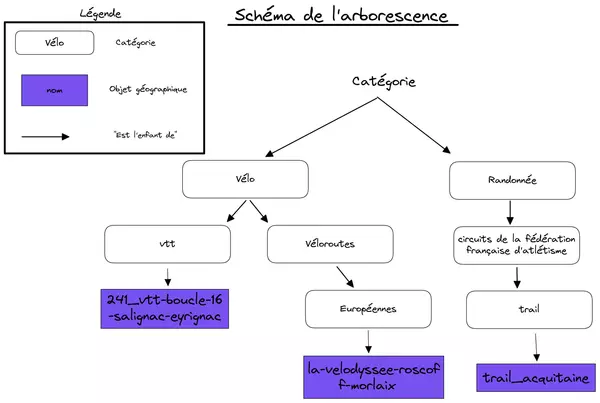
Extension postgres ltree
L'extension Postgres ltree implémente un type ltree permettant de représenter des données organisées de manière arborescente.
Nous avons notamment accès à des opérateurs de comparaison pour accéder aux enfants/parents d'une ligne.
J'aime cette solution car la complexité des opérations sur les arborescences est déportée sur une librairie tierce, de qualité ! Dans le cas contraire, nous aurions besoin d'utiliser des techniques que je considère comme plus propices aux bugs, comme les adjacency list ou les closure table. Il est aussi possible d'implémenter une structure arborescente avec des requêtes récursives, mais ltree semble proposer des performances supérieures (source).
La principale limite de cette extension est la contrainte de nommage des nœuds (label) : ceux-ci doivent être composés des caractères A-Za-z0-9_. Si vous utilisez des accents, des symboles, des espaces ou même des emoji, cela va poser problème à ltree.
Aussi, je vous recommande de ne pas stocker directement le nom de vos nœuds mais un identifiant unique, et de maintenir à côté une table de correspondance entre les noms de vos nœuds et les identifiants utilisés pour représenter l'arborescence.
La mise en place de ltree se fait en rajoutant une colonne de type ltree à nos données. Cette colonne contient, pour chaque ligne, le chemin du nœud auquel la ligne est rattachée.
Ajouter une information d’arborescence à nos données
Dans cette partie, nous allons transformer nos données pour gérer la contrainte de nommage des étiquettes ltree.
L'objectif final est de fabriquer, pour chaque ligne, un objet de type ltree qui matérialise la hiérarchie des catégories telle que décrite dans la colonne path. Grâce à cet objet, nous aurons accès à toutes les opérations classiques que nous réalisons sur des arbres : calcul de profondeur, recherche du parent, des enfants, déterminer l'ancêtre commun, etc.
Pour cela, nous créerons une nouvelle table, qui contiendra les données de la table initiale mais dont la colonne path sera de type ltree.
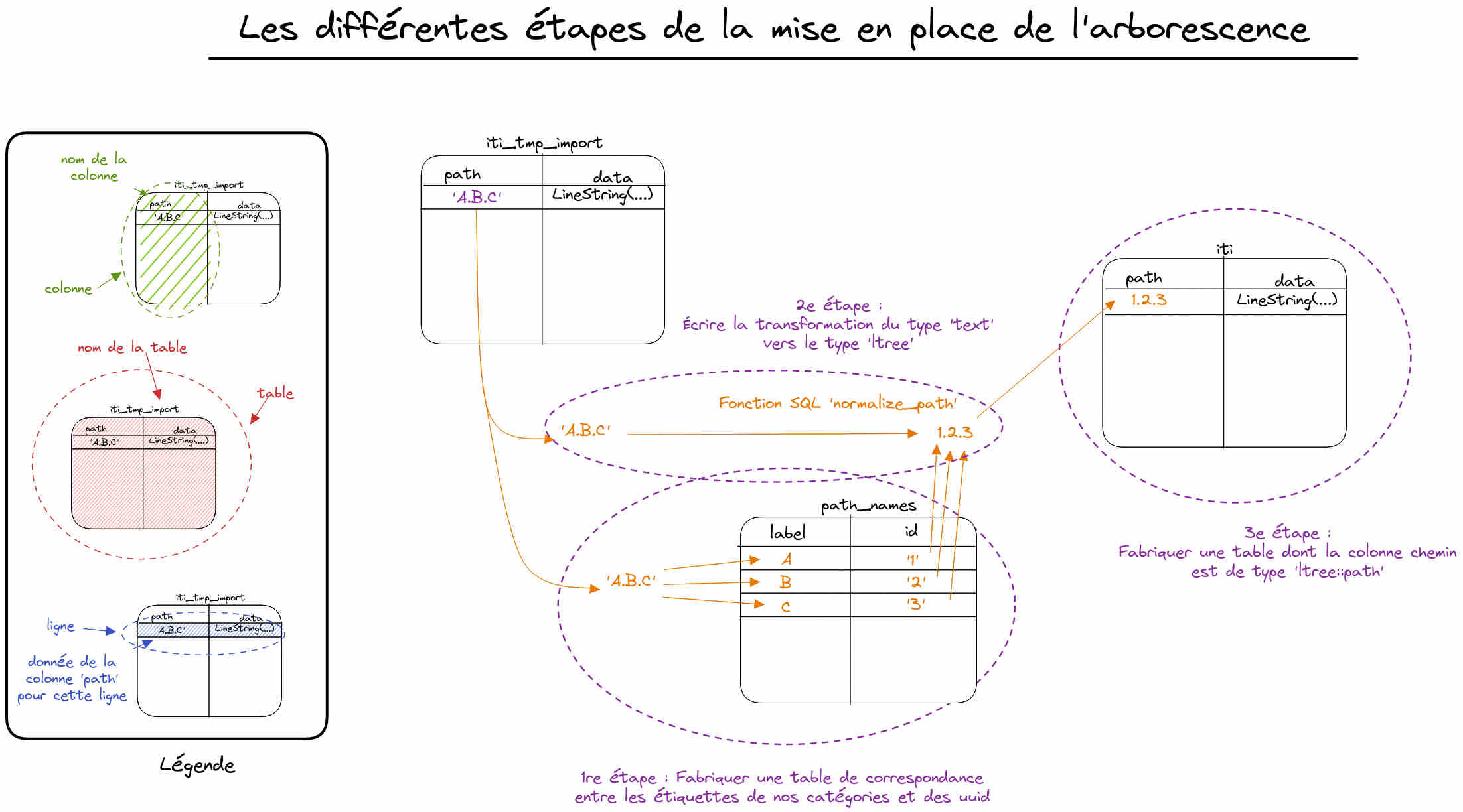
1 - Créer la table de correspondance entre nos catégories et des identifiants uniques
Commençons par créer une table de correspondance entre nos catégories et des identifiants uniques (uuid).
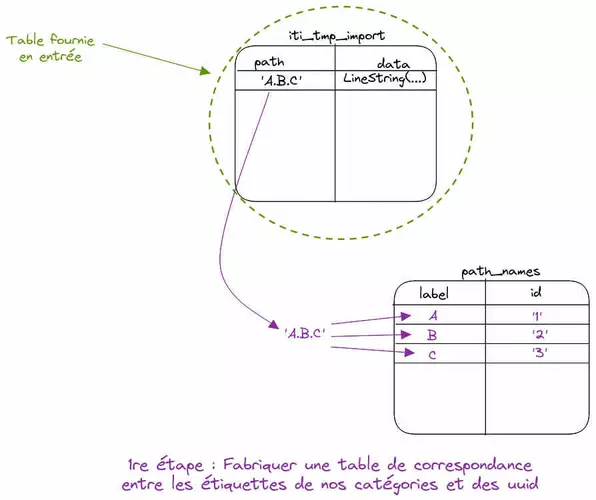
Celle-ci comportera donc deux colonnes :
- une colonne pour stocker le nom de notre catégorie
- une colonne pour y associer un identifiant unique de type *UUID*
Ouvrez une console psql avec votre utilisateur et créez la table path_names ainsi :
create table path_names
(
id text not null
primary key,
label text not null
unique
);
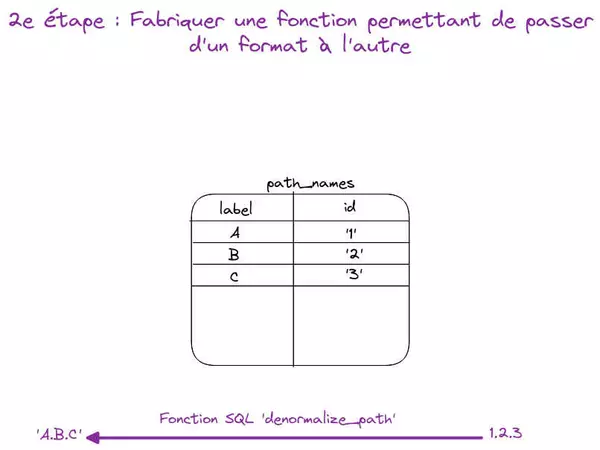
Nous allons ensuite écrire une fonction Postgre pour transformer un chemin de la forme A.B.C (avec . le séparateur hiérarchique entre les différents niveaux de votre arbre) vers un chemin composé d'uuid utilisable par ltree.
Pour cela, nous voulons d'abord extraire la liste des catégories - ici A, B et C - puis générer un identifiant unique accepté comme label par ltree. J'ai choisi de fabriquer des uuid version 4. "Pas de bol", le caractère '-' n'est pas un caractère de label ltree valide, donc je le remplace par '_'.
L'idée est d'utiliser la fonction string_to_array pour éclater notre chaîne de caractères en un tableau. Puis en utilisant la fonction unnest on transforme ce tableau en un ensemble de lignes que nous pourrons donc manipuler comme une table.
La requête suivante fabrique la liste des catégories dans la Common Table Expressions (doc) path_parts et insère ensuite dans la table path_names les uuid correspondant.
Attention, la requête suivante nécessite l'extension Postgres "uuid-ossp". Si vous avez suivi l'article depuis le début, elle est déjà installée sinon retournez lire la partie de mise en place !
WITH path_parts AS (SELECT unnest(string_to_array(path , '.'::text)) as path from iti_tmp_import)
INSERT INTO path_names(label, id)
SELECT path_parts.path, replace(uuid_generate_v4()::text, '-', '_') as label_uuid FROM path_parts
ON CONFLICT (label)
DO NOTHING;
Après avoir exécuté cette requête, j'obtiens la table suivante :
id | label
--------------------------------------+--------------------------------------------------
c2b804e8_fa57_47e2_b599_cd806eb98fe3 | circuits de la fédération française d'athlétisme
1154e570_e379_4d33_91b9_d5a3b3107045 | trail
8732aee0_fdef_46cb_a42f_38263e668621 | vélo
81da8f02_fd4c_4454_8336_a9e307293fbb | vtt
63bf6c2e_358f_438b_8201_694793db8e31 | sitesvtt
9713124e_059d_4214_abc3_cbf93bd6094d | véloroute
3ac5973a_437d_42d5_b0df_020b107fce40 | vélodyssee
Étant donné que la fonction uuid_generate_v4() renvoie un uuid aléatoire, vous n'aurez probablement pas la même table.
2 - Transformer les chemins en 'path'
Maintenant, nous pouvons nous attaquer à la transformation des chemins de la table iti_tmp_import.
Nous allons implémenter ce comportement dans une fonction plpgsql car cela nous permettra de nous servir de celle-ci dans de futures requêtes.
Écrivons donc la fonction normalize_path qui reçoit un chemin au format 'A.B.C' et retourne la version normalisée pour ltree. Nous allons appliquer la même stratégie que précédemment, c'est à dire qu'à partir de la liste des catégories, nous récupérons les uuids correspondants et nous fabriquons le chemin final à insérer dans Postgres.
Pour cela, nous allons à nouveau stocker dans une CTE l'ensemble des catégories, sauf que nous allons y adjoindre un entier permettant de retrouver l'ordre des catégories afin de conserver notre hiérarchie.
La fonction string_agg va nous permettre de réaliser une agrégation des différents identifiants.
Voici une proposition d'implémentation :
CREATE OR REPLACE FUNCTION normalize_path(path text)
-- Reçoit un chemin au format 'A.B.C' et renvoie une version normalisée de celui ci (ie : <uuid_mapping_A>.<uuid_mapping_B>.<uuid_mapping_C>)
RETURNS ltree
AS
$$
DECLARE result ltree;
BEGIN
WITH path_parts AS (
SELECT parts, n
FROM unnest(string_to_array(path , '.') ) WITH ORDINALITY AS t(parts,n) -- WITH ORDINALITY est nécessaire pour générer 'n' qui peut ensuite être utilisé pour rendre l'ordre cohérent durant l'agrégation
)
SELECT string_agg(p.id,'.' ORDER BY parts.n)::ltree INTO result -- Remarquez le ORDER BY, très important si vous voulez conservez la hiérarchie de votre chemin
FROM path_names p
LEFT JOIN path_parts parts
ON parts = p.label
WHERE parts = p.label;
RETURN result;
END;
$$ STABLE PARALLEL SAFE LANGUAGE plpgsql;
Nous pouvons tester la fonction ainsi :
select name, normalize_path(path) from iti_tmp_import ;
J'obtiens le résultat suivant :
name | normalize_path
-------------------------------------+----------------------------------------------------------------------------------------------------------------
trail_acquitaine | c2b804e8_fa57_47e2_b599_cd806eb98fe3.1154e570_e379_4d33_91b9_d5a3b3107045
241_vtt-boucle-16-salignac-eyrignac | 8732aee0_fdef_46cb_a42f_38263e668621.81da8f02_fd4c_4454_8336_a9e307293fbb.63bf6c2e_358f_438b_8201_694793db8e31
la-velodyssee-roscoff-morlaix | 8732aee0_fdef_46cb_a42f_38263e668621.9713124e_059d_4214_abc3_cbf93bd6094d.3ac5973a_437d_42d5_b0df_020b107fce40
De la même manière, nous pouvons implémenter la fonction denormalize_path qui à partir de la représentation pointée (.) d'un chemin retourne la version avec les noms des nœuds.
3 - Fabriquer la table finale
Maintenant que nous savons transformer nos chemins dans le format de ltree, nous pouvons nous attaquer à la fabrication de la table finale.
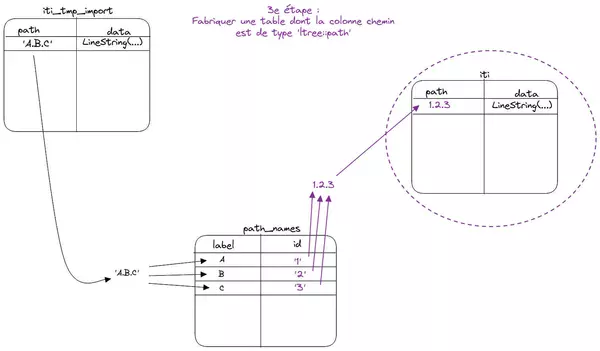
Pour cela, créons ses 4 colonnes (id, name et geom sont identiques à la table iti_tmp_import), et fixons le type de la colonne 'path' à ltree.
create table iti
(
id text not null
primary key,
name text not null,
path ltree not null,
geom geometry(MultiLineString, 3857) not null
);
Il est maintenant possible d'insérer nos données :
INSERT INTO iti(id, name, path, geom)
SELECT id, name, normalize_path(path), geom
FROM iti_tmp_import p
ON CONFLICT(id) DO UPDATE
SET name = excluded.name, geom = excluded.geom, path = excluded.path;
Et nous obtenons alors la table (j'ai omis la colonne geom) :
id | name | path
------------------------------------------------------------------------------------+-------------------------------------+----------------------------------------------------------------------------------------------------------------
MANUEL_circuits de la fédération française d'athlétisme.trail.trail_acquitaine.gpx | trail_acquitaine | c2b804e8_fa57_47e2_b599_cd806eb98fe3.1154e570_e379_4d33_91b9_d5a3b3107045
MANUEL_vélo.vtt.sitesvtt.241_vtt-boucle-16-salignac-eyrignac.gpx | 241_vtt-boucle-16-salignac-eyrignac | 8732aee0_fdef_46cb_a42f_38263e668621.81da8f02_fd4c_4454_8336_a9e307293fbb.63bf6c2e_358f_438b_8201_694793db8e31
MANUEL_vélo.véloroute.vélodyssee.la-velodyssee-roscoff-morlaix.gpx | la-velodyssee-roscoff-morlaix | 8732aee0_fdef_46cb_a42f_38263e668621.9713124e_059d_4214_abc3_cbf93bd6094d.3ac5973a_437d_42d5_b0df_020b107fce40
On peut désormais réaliser des requêtes incorporant la notion d’arborescence. Par exemple, pour obtenir toutes les lignes qui sont dans la catégorie vélo, nous pouvons utiliser l'opérateur "<@" (doc) ainsi :
select name from iti where path <@ normalize_path('vélo');
Il est aussi possible de combiner des opérateurs géographiques issus de PostGIS avec ltree :
select name from iti where path <@ normalize_path('vélo') and st_intersects(geom, …);
Conclusion
Vous avez maintenant tous les outils pour mettre en place une structure arborescente à partir de vos données. Grâce à la puissance de PostgreSQL vous pouvez coupler ce fonctionnement arborescent avec des requêtes SIG si vous avez des données SIG dans votre base (ici c'est le cas).
Si vous servez la table iti sous forme de tuiles vectorielles - par exemple avec un outil comme martin - vous avez maintenant tous les outils pour implémenter un filtrage arborescent dans le MapLibre qui consommerait ce jeu de données.
À partir des différents path stockés dans la table iti vous pouvez fabriquer une représentation au format json qui viendra alimenter un endpoint HTTP consommé par un front JavaScript. Celui-ci pourra nourrir le json à un widget de multi-select et vous pourrez vous servir de la sortie de ce widget pour filtrer votre carte.
Voici un schéma d'architecture de la fonctionnalité, dans cet article nous avons réalisé la partie entourée en rouge :
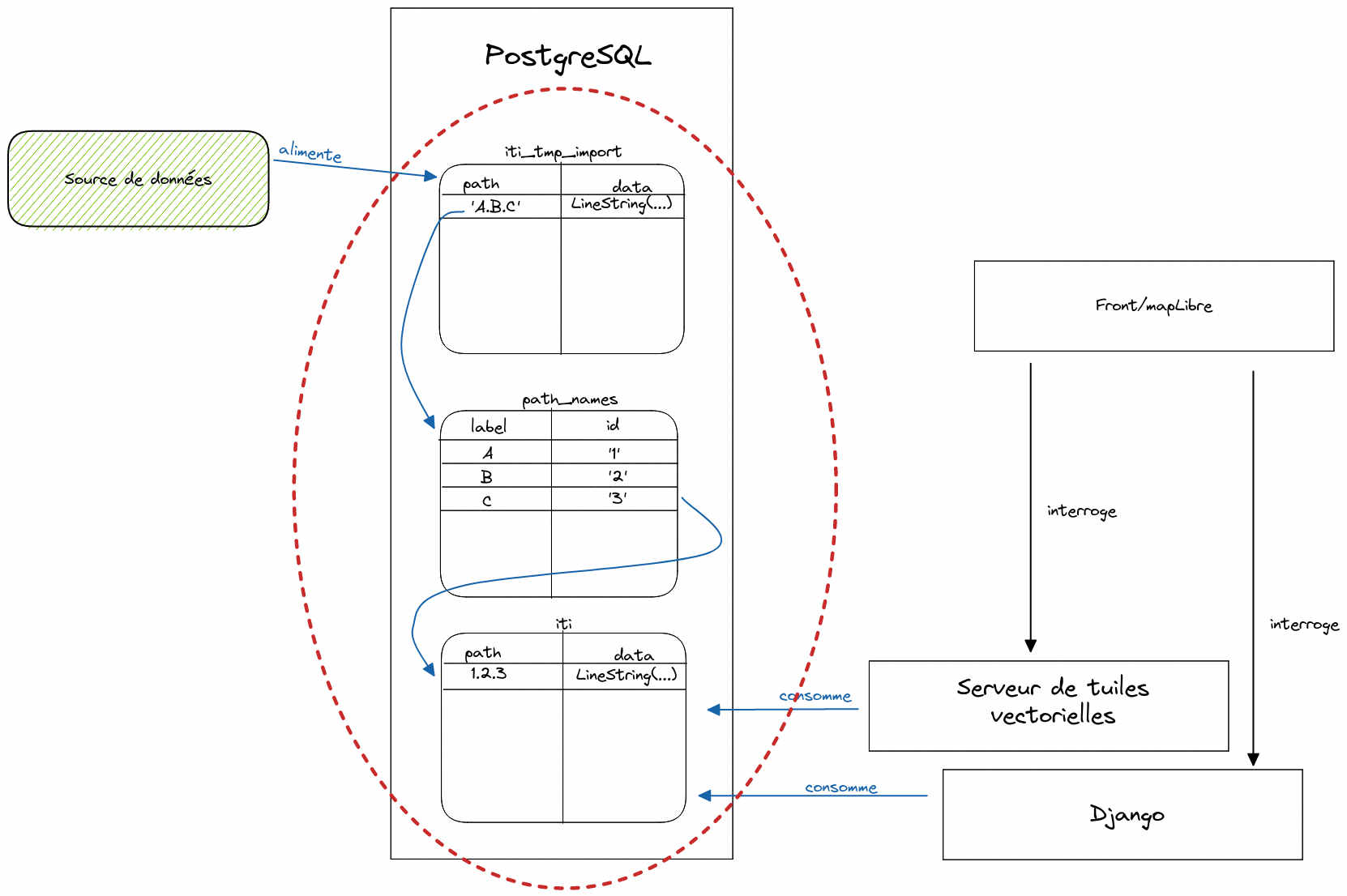
Ceci n'est bien sûr qu'un seul cas d'usage parmi tant d'autres !
Voici un dump contenant les tables finales réalisées à travers de cet exercice : Dump solution

Django-Python-Devops
Formations associées
Formations Outils et bases de données
Formation PostgreSQL
Nantes Du 8 au 10 septembre 2026
Voir la Formation PostgreSQLFormations SIG / Cartographie
Formation PostGIS
Toulouse Du 6 au 8 octobre 2026
Voir la Formation PostGISActualités en lien
Geotrek 2025–2026 : nouvelles fonctionnalités et grands chantiers à venir
Logiciel libre
27/05/2026
Administrer des comptes Keycloak depuis une application Python/Django
Django
18/11/2021
Dans cet article, nous allons créer une application Python/Django qui agira en tant que maître sur Keycloak afin de pouvoir ajouter facilement des comportements personnalisés à Keycloak.

Web mapping : comparaison des serveurs de tuiles vectorielles depuis Postgres / PostGIS
SIG
03/07/2020
Un ensemble de serveurs de tuiles vectorielles basés sur la fonction ST_AsMVT() de PostGIS sont disponibles. Makina Corpus vous propose un tour d’horizon des spécificités des différentes solutions.
