Makina Blog
Scraping & Machine Learning : comment fonctionne un moteur de recherche ?
Ou comment utiliser des composants libres pour faire votre mini-Google (ou Qwant)
Note : cet article aurait pu s'appeler "J'ai appris Python et le machine learning en 2 mois, la suite va vous étonner", il est donc normalement accessible à tous, sous réserve d'un minimum de compréhension basique d'algorithmique.
Les référenceurs ont depuis toujours tenté de comprendre le fonctionnement des moteurs en simulant le comportement des moteurs à l'aide d'un crawler (logiciel comme Screaming Frog ou Xenu, en Saas comme Botify ou OnCrawl), ou en analysant les traces à l'aide d'un analyseur de logs (mêmes logiciels ou plateformes Saas que citées précédemment).
L'idée de cet article est de passer de l'autre côté du miroir en créant un véritable moteur de recherche (simplifié). D'un point de vue développeur, je souhaite également montrer que dans le référencement, il n'y a pas de magie, mais beaucoup d'algorithmes impliqués (et donc de travail pour les comprendre et optimiser pour).
Fonctionnement simplifié d'un moteur de recherche
Un moteur de recherche doit en gros réaliser trois tâches :
- Découvrir les nouvelles pages web (dans le SEO, on parle de crawling) ;
- Comprendre le contenu des pages (réalisé lors d'une étape qu'on appelle l'indexing) ;
- Répondre à une requête utilisateur, en classant (on parle de ranking) les pages les unes par rapport aux autres selon cette requête (le classement peut être différent mais contenir les mêmes pages sur une autre requête utilisateur).
On parle souvent plutôt du fonctionnement de Google, parce qu'il est mieux connu que les autres moteurs (suite à de nombreux échanges, brevets, papiers de recherche…).
Ce qu'on appelle génériquement "GoogleBot" est en fait découpé en (au moins) 2 outils, le GoogleBot proprement dit, le crawler, qui parcourt les liens des pages web et n'interprète pas le javascript, et l'indexateur, "Caffeine", qui, se compose entre autres d'un WRS (basé sur Chrome) qui, lui, interprète le Javascript :

Bien sûr, les liens identifiés par Caffeine sont ensuite ré-injectés dans le GoogleBot qui continuera d'essayer de parcourir les pages, mais on peut comprendre que des sites en pur Javascript soient donc indexés plus lentement, simplement parce que l'étape de récupération des liens est dans la deuxième phase (l'indexation), et donc moins efficace que les liens récupérés dès la première phase.
Nous allons essayer de créer un mini-moteur de recherche, en Python, qui parcourt les liens, indexe le contenu des pages et utilise des algorithmes de machine learning pour comprendre les pages et classer les résultats de recherche.
Le code complet de ce projet est disponible sur le dépôt Github "MIni Search Engine in Python", alias MISEP. Pour le faire fonctionner sur votre site, il vous suffit à priori, en plus d'installer les pré-requis, de changer le nom de domaine à parcourir dans la configuration du scraper (fichier corpus/spiders/spiders.py).
Crawling (étape de découverte des pages)
GoogleBot
Le but du crawler (le fameux GoogleBot chez Google) est de découvrir les nouvelles pages webs disponibles, et de notifier l'indexeur quand des pages changent. Il n'essaie à priori pas spécialement de comprendre la page, du moins le moins possible, pour se concentrer sur la découverte de liens.
Créons notre GoogleBot
Le code de cette partie est totalement issu de l'article "Scraping a website with Scrapy".
On va chercher grâce à Scrapy, un très bon crawler en Python, à parser le code des pages que l'on visite afin de découvrir l'ensemble des liens, exporter les liens que l'on rencontre, et continuer à parcourir les nouvelles pages trouvées.
On commence par installer Scrapy, créer un projet, un crawler, et modifier ce crawler :
pip install scrapy scrapy startproject crawler
Puis on créé un fichier dans le sous-dossier "spiders", c'est celui qui contient le code principal de notre crawler.
Ici, pour ne récupérer que les liens internes à un domaine, on limite volontairement les pages identifiées, mais en supprimant le filtre sur les domaines, il est tout à fait possible de créer un "vrai" GoogleBot, qui va parcourir le web à la recherche des liens entre les pages.
Voilà le code du crawler correspondant à ce premier outil :
Ce crawl ne parsant que les liens, il est très rapide par rapport à un crawl visant à récupérer le contenu de la page.
Application directe pour un audit SEO : par rapport au code initial issu de l'article, j'ai changé les noms des colonnes du fichier CSV par commodité : cela permet d'importer directement le CSV des liens internes dans Gephi pour analyser graphiquement la structure du site, et ainsi détecter des opportunités de création / suppressions de liens internes.
Attention, par défaut, Scrapy ne récupère que les liens dans les balises <A> et <AREA> (et non pas, par exemple, le contenu des balises <LINK> dans la HEAD de la page). Cependant, il est facile de modifier cette configuration.
Googlebot va plus loin, notamment en stockant un hash des pages visitées pour déterminer si elles ont changé entre deux visites, et ainsi déclencher ou non une nouvelle indexation.
Ce crawler permet également de calculer le fameux PageRank, puisque nous disposons de la liste complète des liens (ici, internes uniquement puisqu'on se limite à parcourir 1 seul domaine).
Indexing (étape de compréhension)
Caffeine
Le but de l'indexation (réalisée par "Caffeine" chez Google) est de comprendre le contenu des pages. C'est lui qui va notamment essayer d'interpréter le Javascript. D'ailleurs, si à cette étape, il découvre de nouveaux liens après avoir rendu le javascript, ces liens seront renvoyés au GoogleBot pour être également crawlés lors du prochain passage du bot.
Récupération de l'HTML
Ici, nous allons nous contenter pour le moment d'un indexateur "simple", c'est à dire qui parse le HTML, mais n'interprète pas le Javascript. Nous ajouterons cette possibilité plus tard dans l'article.
Dans un premier temps, nous devons donc récupérer le contenu dans le HTML, et pas seulement les liens. Cela va nous donner l'occasion de creuser un peu plus dans les fonctionnalités de Scrapy, et on va chercher à récupérer, dans un premier temps, la balise TITLE, importante dans le référencement, et le contenu de la page (le contenu de la balise BODY) :
Là encore, on se contente d'une récupération simple, on ne tient pas compte des différents éléments de la page (les titres, notamment) pour mettre un quelconque poids sur nos mots clés.
Transformation en texte
Pour pouvoir traiter notre texte avec des algorithmes, il faut d'abord transformer le HTML en lui appliquant plusieurs traitements successifs :
- Suppression des balises HTML ;
- "Tokenisation", c'est-à-dire découpage du texte restant en "mots" (les algorithmes se basent quasiment tous sur des listes de mots) ;
- Lemmatisation : réécriture des mots dans leur forme la plus simple (suppression des pluriels, conjugaisons…).
Là encore, on peut profiter des fonctionnalités de scrappy pour ajouter des "Pipelines", c'est à dire des traitements réalisés sur les éléments récupérés. On commence par transformer en texte l'HTML récupéré, en remplaçant toutes les balises par un espace :
Ensuite, on va décomposer nos textes en mots. Bien sûr, il faudrait aller plus loin (ajouter des lemmatiser ou stemmer (traitements qui suppriment les pluriels et les conjugaisons), mais on va se contenter d'un traitement simple pour le moment, d'autant que ces traitements sont spécifiques à des langues. Ce sera une piste d'amélioration pour notre moteur.
On va donc faire appel à des algorithmes de traitement du langage, ou NLP.
Le traitement du langage, c'est un peu comme apprendre la grammaire à un collégien.
Ici, on va utiliser les bibliothèques Python de traitement du langage nltk et gensim :
pip install nltk pip install gensim
La suite des fonctionnalités que nous allons rajouter tend vers un seul but : transformer le texte en une forme permettant d'utiliser des algorithmes mathématiques de recherche de proximité.
TF-IDF
La première approche pour indexer un contenu est de se baser sur la fréquence des mots dans le texte (on se rappelle les premiers temps du référencement où il suffisait d'aligner suffisamment de fois un mot-clé pour se positionner…). Les algorithmes basés sur la fréquence de mot ont depuis un peu évolué, mais sont éventuellement toujours utilisés.
Le plus connu, TF-IDF, donne un poids plus important à un mot en fonction de sa fréquence dans le document, pondérée par sa relative rareté dans le corpus de documents complet :
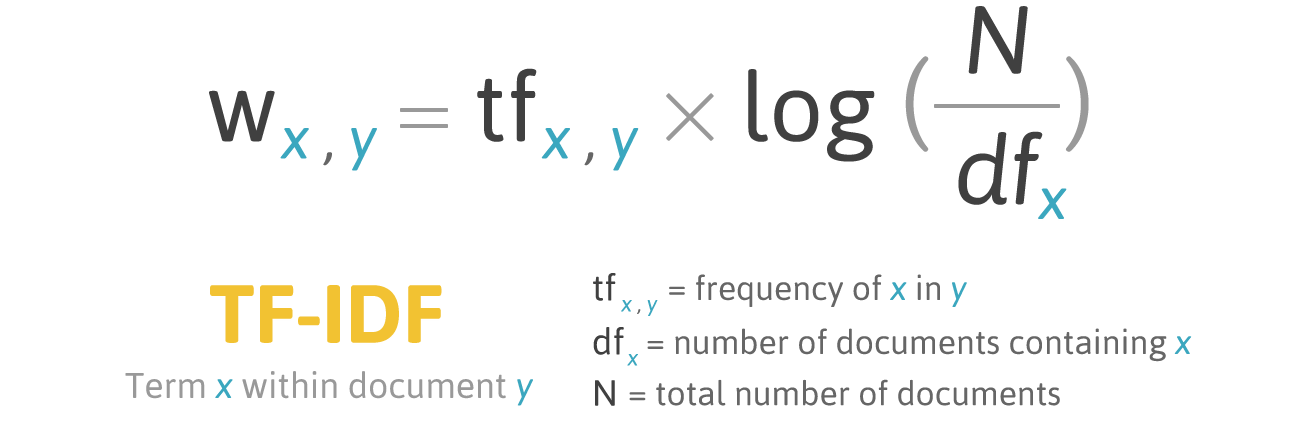
L'implémentation dans notre projet se fait là encore en quelques lignes :
TF-IDF a été pendant longtemps l'algorithme de ranking utilisé par les moteurs de recherche Solr et Elasticsearch (tous deux basés sur Lucène). Ils ajoutaient seulement une pondération sur la taille du champ (un mot clé dans le titre aura plus d'importance qu'un mot clé dans le body).
Cet algorithme reste le plus connu, et le seul implémenté par la plupart des bibliothèques de traitement naturel du langage, mais ce n'est pas le plus performant : notamment, Wikipedia recommande l'utilisation d'Okapi BM25 (BM pour "Best Matching"), un algorithme dérivé de TF-IDF, prenant notamment en compte la longueur des documents du corpus.
Plus d'informations sont disponibles sur le papier de recherche de Wikimedia : "Improving search result relevancy on Wikipedia with BM25 ranking", où l'on constate notamment que le BM25 n'est pas le seul facteur à contribuer à améliorer les résultats de la recherche.
Cet algorithme est désormais ajouté dans Lucène, et est disponible dans Solr (depuis la version 6) et dans Elasticsearch. Attention, Elasticsearch combine avec d'autres facteurs.
Bien sûr, on peut également l'implémenter avec Gensim, mais on se contentera de TF-IDF pour le moment, l'exercice est laissé à la curiosité du lecteur ;-)
Conséquence appréciable de l'utilisation d'un algorithme de fréquence, les mots et documents sont désormais transformés en vecteurs et matrices, que l'on peut plus facilement comparer entre eux ou manipuler pour essayer de faire correspondre une requête utilisateur.
Recherche de sens
L'utilisation seule de la fréquence ne donne pas de résultats suffisamment pertinents pour nos moteurs préférés. Pour aller plus loin, on va ajouter à ce simple support de fréquence des termes des notions de sémantique. On ne va ainsi plus seulement faire des recherches de mots dans un document, mais des recherches de "concepts" liés à ce mot dans nos documents. On tente en fait de s'approcher de la compréhension humaine d'un texte.
Première idée : les mots ayant une signification similaire vont apparaître dans des documents similaires. En gros, on étudie les co-occurences de mots.
On distingue en gros 2 types d'algorithmes : ceux basés sur un simple compte de mots dans le documents, et ceux basé sur la probabilité de trouver ces mots dans le document (ou à proximité d'autres).
Le premier algorithme utilisé par les moteurs pour analyser ça est l'analyse (ou indexation) sémantique latente (LSA ou LSI en anglais). L'idée est de représenter un corpus sous forme de matrice : en ligne les documents, en colonne les mots et leur nombre dans le document. Il suffit de comparer les lignes pour identifier les documents similaires (donc qui parlent du même sujet). Et on peut réordonner la matrice pour mettre en évidence les "concepts" en regroupant les mots utilisés.
LSI existe aussi en version "probabiliste", pLSI, qui a évolué de façon plus performante en LDA : l'idée principale derrière LDA est qu'un document est à priori constitué d'un faible nombre de sujets (2 ou 3), et que ces sujets peuvent être représentés par un faible nombre de mots utilisés fréquemment. Ici, on s'approche vraiment de la notion de "concept". Du coup, le moteur peut désambiguiser un mot en regardant le concept auquel il est lié, et renvoyer ainsi le document le plus pertinent.
Mais LSI & LDA sont des algorithmes d'extraction du sujet d'un document, on n'est pas encore sur la compréhension des mots ou des phrases…
Des équipes de recherche de Google ont alors développé en 2013 un nouvel algorithme pour "donner du sens aux mots" en les transformer en vecteurs : Word2Vec (lire "Learning the meaning behind the words"). Cet algorithme, basé sur du machine learning et des probabilités, permet de comparer les vecteurs entre eux, et même d'utiliser des opérations simples : V(roi) - V(homme) + V(femme) ~ V(reine), par exemple :
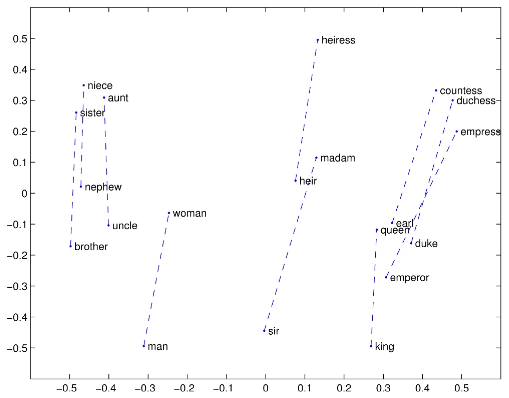
Et ces vecteurs permettent de mettre en évidence de très nombreuses relations différentes entre les mots :
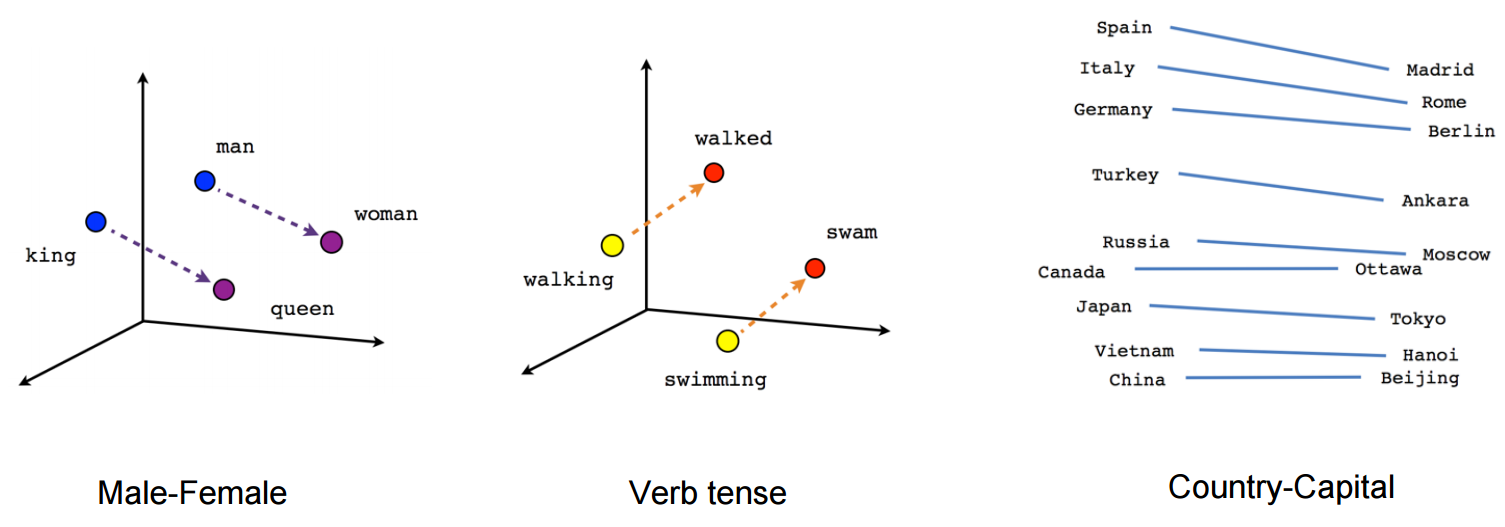
On s'approche d'une interprétation "humaine" ;-) La bonne nouvelle est que nous pouvons également implémenter Word2Vec, toujours avec la même bibliothèque :
Il y a d'autres algorithmes qui répondent au même objectif (vectorisation des mots), notamment "Bag of Words (bow)", le plus simple, et GloVe (pour Global Vectors, développé par Stanford), plus récent et plus efficace (apprentissage plus rapide, efficace même sur de petits corpus).
À noter qu'au final, nous cherchons à classifier des documents entiers, pas juste des mots. On pourra donc utiliser une évolution de Word2Vec : Doc2Vec.
Ranking (étape de classement)
Pour déterminer le document le plus proche d'une requête donnée (le plus pertinent sémantiquement sur cette requête), on transforme de la même manière que précédemment cette requête en vecteur, et on utilise des algorithmes de similarité, notamment basés sur des vecteurs (le fameux Cosinus de Salton bien connu des référenceurs).
Ici, la même librairie gensim permet une implémentation là encore très rapide :
Je ne sais pas quels(s) algorithme(s) ils utilisent, mais vous avez désormais des pistes pour tenter de coder vous-mêmes un outil similaire à 1.fr, YourTextGuru, Visiblis, SEOQuantum …
Nous avons ici l'implémentation d'un algorithme de scoring basé sur la pertinence sémantique. Bien sûr, un "vrai" moteur tiendra également compte du PageRank (celui dont on a vu plus haut qu'il était toujours utilisé ;-)) pour classer les résultats de pertinence similaire.
Mais les moteurs vont aujourd'hui plus loin, en intégrant les données issues des utilisateurs dans les résultats de recherche (en reclassant les éléments issus de cette première étape, par exemple en utilisant des algorithmes de type Learning to rank).
On obtient comme shéma final de l'architecture de notre moteur quelque chose comme :
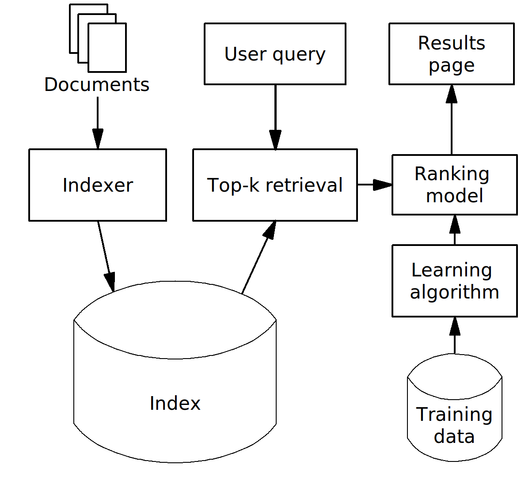
Schéma issu de l'article wikipedia cité précédemment (Learning to rank)
Performances
Nous avons désormais un code fonctionnel qui simule le fonctionnement d'un moteur de recherche. C'est certes un beau prototype. Mais un point clé pour aller vraiment plus loin est l'amélioration des performances, afin de pouvoir appliquer ce fonctionnement au web complet.
Chaque partie peut (et doit) donc être améliorée.
Crawling
On peut imaginer utiliser le cloud proposé par Scrapy pour améliorer la performance de notre crawler. Mais il est plus probable que l'on se tournerait vers des solutions type Sparkler, un regroupement de produits Apache et une évolution d'Apache Nutch, leur crawler, qui fonctionne sur cluster Spark. En somme, nous créons notre propre infrastructure cloud de crawling.
Cela nous permet de parcourir plus de pages plus vite, mais on peut gagner beaucoup en parcourant beaucoup moins de pages !
Le GoogleBot dispose d'ailleurs d'un planificateur (voir cette présentation sur le sujet) qui lui indique ce qu'il doit crawler et à quelle fréquence : les pages d'accueil des sites sont par exemple parcourues beaucoup plus souvent que des pages à faible contenu ou valeur ajoutée, ou des pages qui n'ont pas changé depuis longtemps.
On pourrait donc stocker les fréquences de modification des pages, et utiliser par exemple encore le machine learning pour déterminer quand parcourir à nouveau ces pages.
Indexation
Là encore, le plus simple est de ne rien faire : on devra également ajouter à notre crawler le calcul d'un "hash" de la page, que l'on stockera et qui permettra de ne déclencher l'indexation que des pages qui ont bougé.
On peut aussi travailler tout simplement sur une plus petite partie de l'HTML : pour diminuer le parsing d'HTML non pertinent, et se concentrer sur le contenu principal de la page, on pourrait imaginer dire à Scrapy de se contenter de la zone <MAIN> de la page. Il suffit de remplacer dans notre spider
response.css("body").extract_first()
par
response.css("main").extract_first()
On pense d'ailleurs que Google, par exemple, accorde moins d'importance aux liens qui ne sont pas dans le contenu principal de la page.
Toujours dans l'optique de ne rien faire, le calcul du hash à l'étape précédente nous permet de détecter les contenus "dupliqués" : des pages qui ont des URLs différents, mais qui semblent contenir la même chose.
Celles-là sont des doublons exacts, mais on peut aussi tenir compte des pages qui recopient le contenu principal d'une page sur une autre. Il faudrait pousser l'analyse plus loin pour éviter le travail dans ce cas, en tout cas les référenceurs savent que le contenu dupliqué sur d'autres sites peut être un enjeu ;-).
Ranking
Ici, pas de secret : il faut améliorer la performance de nos algorithmes de machine learning. Ici, on sort du cadre du pur fonctionnement d'un moteur de recherche pour parler de manière générique de machine learning, ceux qui le souhaitent peuvent sauter à la section suivante.
Plusieurs possibilités s'offrent à nous, par exemple :
- Choisir un algorithme performant, c'est toujours mieux ;-) Si vous avez le choix, privilégier un algorithme comme XGBoost, qui gagne toutes les compétitions de machine learning ces temps-ci ;
- Améliorer la performance d'un algorithme que vous utilisez, en diminuant le nombre de dimensions sur lesquelles vous travaillez, au moyen d'un algorithme comme "Principal Component Analysis" :
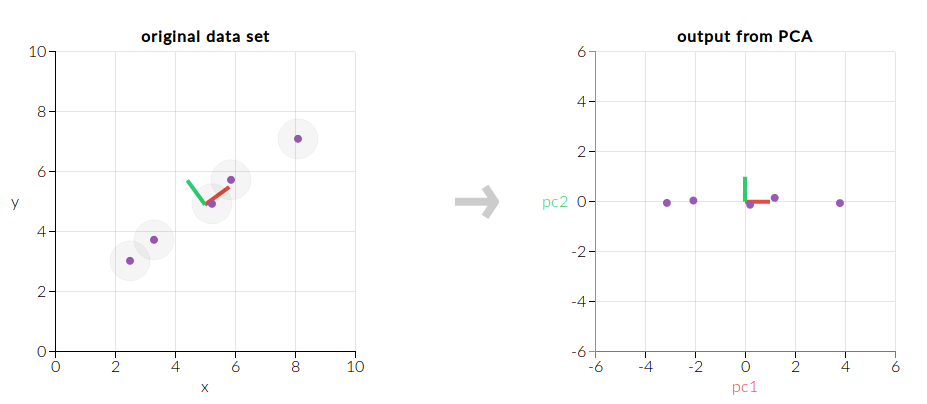
Cet algorithme ne conserve que les dimensions qui comportent le plus d'informations afin de diminuer l'occupation mémoire (et donc d'améliorer les performances) de modèles complexes.
Et bien sûr, comme tout machine learning, l'infrastructure physique rentrera également en ligne de compte pour pouvoir monter en charge sur vos traitements.
Autres pistes d'améliorations fonctionnelles
Recherche d'entités nommées
On peut également aller plus loin dans notre compréhension du texte, en utilisant des bibliothèques qui permettent de détecter des "entités nommées", c'est à dire qui comprennent grammaticalement la phrase. Il existe par exemple la bibliothèque spacy, mais nous allons nous contenter de tester avec ce que nous utilisons déjà, NLTK.
On essaie de récupérer les entités nommées dans une simple phrase pour commencer :
from nltk import word_tokenize, pos_tag, ne_chunk
sentence = "Makina Corpus est une societe specialisee dans la realisation d'applications web
complexes basees exclusivement sur des logiciels libres"
print ne_chunk(pos_tag(word_tokenize(sentence)))
(S (GPE Makina/NNP) (ORGANIZATION Corpus/NNP) est/JJS une/JJ societe/JJ specialisee/NN dans/NNS la/VBP realisation/NN d'applications/NNS web/VBP complexes/NNS basees/NNS exclusivement/VBP sur/NN des/NNS logiciels/NNS libres/NNS)
Bon, il semble détecter correctement Makina Corpus comme la seule entité nommée, mais en tant qu'entité géo-politique ("GPE") et organisation ("ORG"). Ce n'est pas parfait pour le moment, et on pourrait probablement entraîner un peu mieux l'algorithme (on se base là sur l'entraînement par défaut de la bibliothèque, pas forcément entraîné sur des corpus en français).
Ce type d'algorithme peut détecter les lieux, personnes, organisations, liens… et permet de structurer un texte inconnu. On imagine aisément l'intérêt pour les moteurs de disposer de balisage sémantique (au sens de schema.org cette fois) pour être sûr de correctement interpréter les entités nommées essentielles du contenu.
Google a le net avantage de pouvoir s'appuyer sur le Knowledge Graph pour cette partie.
Interprétation du Javascript
Scrapy supporte nativement de nombreuses options : par exemple, pour supporter l'ancien système de rendu javascript (Ajax crawling scheme, déprécié depuis fin 2015, mais toujours supporté jusqu'en 2017), il suffit d'ajouter un paramètre à la configuration de Scrapy :
AJAXCRAWL_ENABLED = True
Mais pour aller plus loin, on peut se baser sur la documentation de Google :
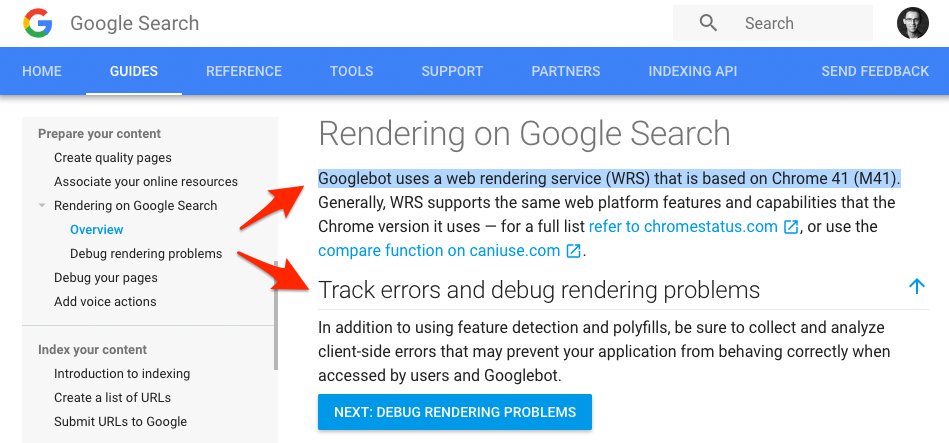
Dans la mesure où le rendu des pages web est basé sur Chrome (actuellement, Chrome 41, mais à terme, cela devrait être basé sur la dernière version de Chrome), il est possible d'utiliser l'API de Chrome headless (disponible depuis Chrome 59) pour récupérer le contenu de la page :
chromium-browser --headless --disable-gpu --dump-dom https://www.example.com
Comme je suis sous Linux, j'utilise Chromium, mais cela fonctionne de manière identique avec Chrome.
Pour un contrôle encore plus poussé, vous pouvez manipuler Chrome avec Python & Selenium.
N-gram
Le découpage en mots simples n'est pas une si bonne idée, notamment quand on veut pouvoir interpréter des expressions, ou des noms ("Makina Corpus", "Linux Magazine", "Richard Stallman"). Il existe des solutions, comme la détection de "Phrases" de gensim.
Autres fonctionnalités que l'on pourrait implémenter
- Détecter le SPAM (Qwant se sert de machine learning pour détecter le spam et le supprimer de ses résultats, par exemple) ;
- Utiliser des critères de qualité du site (Scrapy dispose de statistiques sur le nombre de 404, 301, 302, par exemple) ;
- Détection automatique de la langue (par exemple, on trouve ici une méthode qui utilise les "stop words" du texte : Detecting text language with NLTK) ;
- Détecter la thématique d'une page, à l'aide d'algorithmes de clustering
Remerciements
Je tiens à remercier Sylvain Peyronnet pour sa conférence aux JRES Nantes 2017 et l'équipe d'OVH (Vincent Terrasi et Rémi Bacha) pour les nombreuses informations, réflexions et codes qu'ils partagent (voir la série d'article sur l'IA et le SEO de Rémi, ou leur conférence au OVH Summit 2017). C'est grâce à eux si cet article a vu le jour, et je vous encourage à suivre leurs différents travaux si vous souhaitez découvrir le potentiel du machine learning pour les SEOs.
Pour aller plus loin
Si le sujet vous intéresse, voici quelques liens que j'ai trouvé assez intéressants, avec parfois d'autres exemples de code, ou qui expliquent un peu plus en détail certains algorithmes que j'ai évoqués ici.
- Sur le crawling : Intelligent web crawling ;
- Sur l'utilisation d'algorithmes de traitement du langage pour le web : Mining Web Pages: Using Natural Language Processing to Understand Human Language ;
- Sur les algorithmes "Learning to rank" : A short introduction to Learning to Rank ;
- Sur Word2vec : A word is worth a thousand vectors ;
- Un grand nombre de papiers sur le traitement du langage et le classement en sujets : Publications de David Mimmo ;
Enfin, l'étude de différents documents de ou concernant Google et le ranking :
- How Google might Disambiguate Different Entities with the Same Names in Queries and Pages ;
- Incorporating Clicks, Attention and Satisfaction into a Search Engine Result Page Evaluation Model ;
- Learning to Rank with Selection Bias in Personal Search ;
Et bien sûr, vous pouvez suivre nos formations !

Drupal - SEO
Formations associées
Formations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Python scientifique
Toulouse Du 21 au 25 septembre 2025
Voir la Formation Python scientifiqueActualités en lien
Notre expertise en Data science
Data Science
27/03/2019
L'IA est un domaine vaste et nos différents projets nous ont permis de monter en compétences sur plusieurs sujets. Cet article vous présente les thématiques pour lesquelles nous pouvons vous offrir notre expertise.
Initiation au Machine Learning avec Python - La pratique
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette seconde partie vous permet de passer enfin à la pratique avec le langage Python et la librairie Scikit-Learn !

Initiation au Machine Learning avec Python - La théorie
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette première partie se veut non technique et présente les concepts du Machine Learning, les différents types d'apprentissage et leurs principaux algorithmes. Il situe enfin Python dans cet univers en présentant les nombreuses librairies à votre disposition pour aborder cette discipline.
