Makina Blog
Prédiction du taux de monoxyde de carbone à Madrid - intérêt d'une approche Deep Learning
Dans cet article nous montrons comme utiliser les bibliothèques stars de l'éco-système scientifique en Python pour analyser des données publiques sur la qualité de l'air à Madrid. Nous verrons comment identifier les problèmes liés à ces données. Puis nous comparerons deux approches en Machine Learning : AutoSklearn et les réseaux de neurones de type LSTM.
C'est en cherchant sur Kaggle un jeu de données temporelles adapté pour l'une de nos formations que j'ai découvert que la ville de Madrid mettait à disposition des relevés journaliers sur la qualité de l'air. La société Decide Soluciones ayant fait l'effort de les mettre sous un format homogène, ces données sont une excellente occasion de vous parler un peu de notre démarche lorsque nous nous lançons dans du Machine Learning.
L'ensemble du code évoqué dans cet article est mis à disposion sur notre repo Github dédié aux tutoriels, sous la forme d'un notebook.
Analyse de données
La première étape, celle qui souvent nous monopolise le plus longtemps, consiste à analyser nos données. Ici nous disposons de mesures réalisées heure par heure par plusieurs stations couvrant la ville de Madrid et ses environs. Le temps de dégainer de Pandas et de Folium, et les voilà afficher sur une carte.
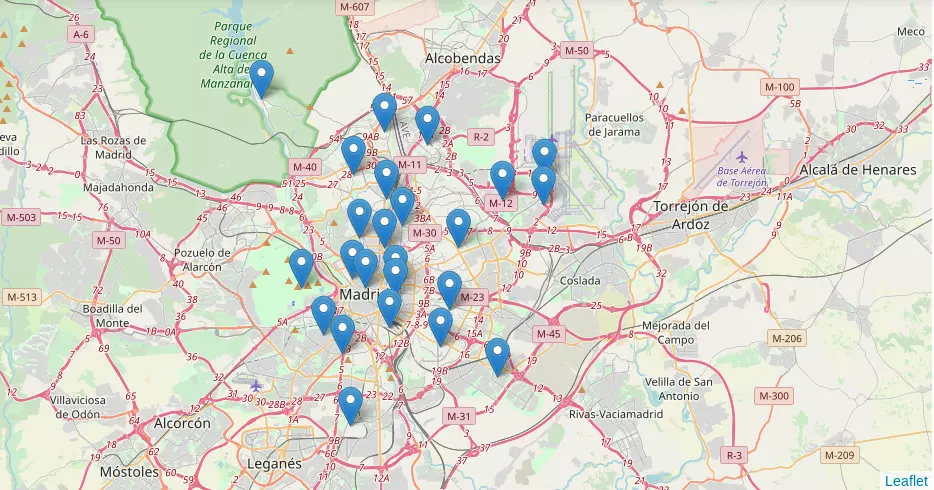
Stations mesurant la qualité de l'air pour la ville de Madrid.
Toutes les stations n'étant pas équipées des mêmes appareils de mesures, les données varient de l'une à l'autre. De plus suite à des pannes, les relevées ne sont pas toujours réalisés.
Afin d'analyser les données fournies par chaque station nous avons ajouté Seaborn à notre boîte à outil. Cette bibliothèque vient s'ajouter à Matplotlib pour créer plus facilement des visualisations plus complexes.
import seaborn as sns
stations = data.groupby('station')
sns.set(style="white", context="talk")
for station_name, station_data in stations:
station_data = station_data.copy().drop(columns=['date', 'station'])
column_set = np.empty(station_data.columns.shape)
for idx, column in enumerate(station_data.columns):
column_set[idx] = station_data.shape[0] - station_data[column].isna().sum()
plt.figure(figsize=(20, 10))
sns.barplot(x=station_data.columns, y=column_set, palette="rocket")
plt.savefig(os.path.join('imgs', f'{station_name}.png'))
Quelques lignes de code plus tard, nous voilà avec un diagramme par station indiquant, pour chaque variable, combien de relevés la station a pu réaliser.
Données relevées entre 2007 et 2009 par la station 28079058.
Le graphique suivant nous indique par exemple que la station 28079058 a été équipée pour relever les taux de NMHC (hydrocarbures non méthaniques), NO_2 (dioxyde d'azote), NOx (Protoxyde d'azote), O_3 (Ozone) et TCH (niveau d'hydrocarbures total). Cependant les relevés pour NMHC et O_3 n'ont pas été réalisés en intégralité.
L'analyse de ces diagrammes indique qu'une seule station a pu réaliser l'intégralité des relevés pour l'ensemble des variables.
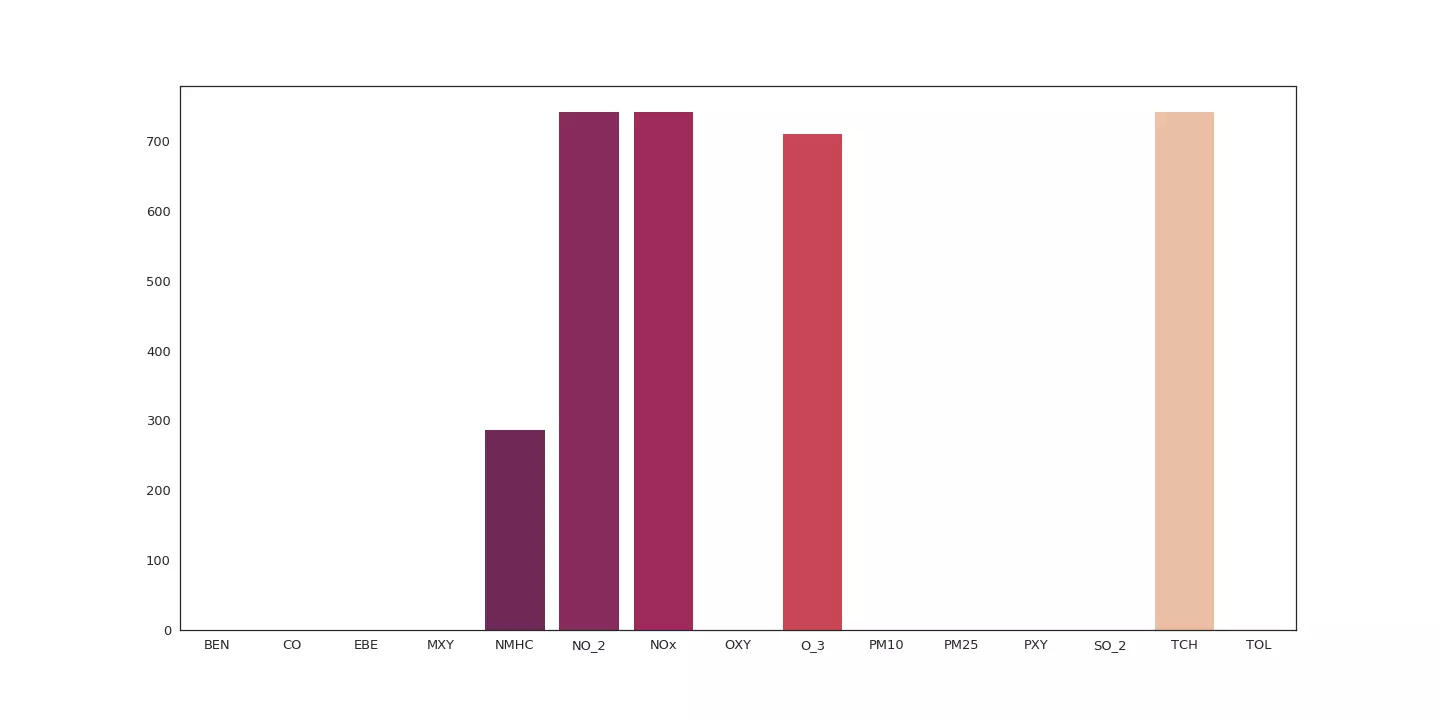
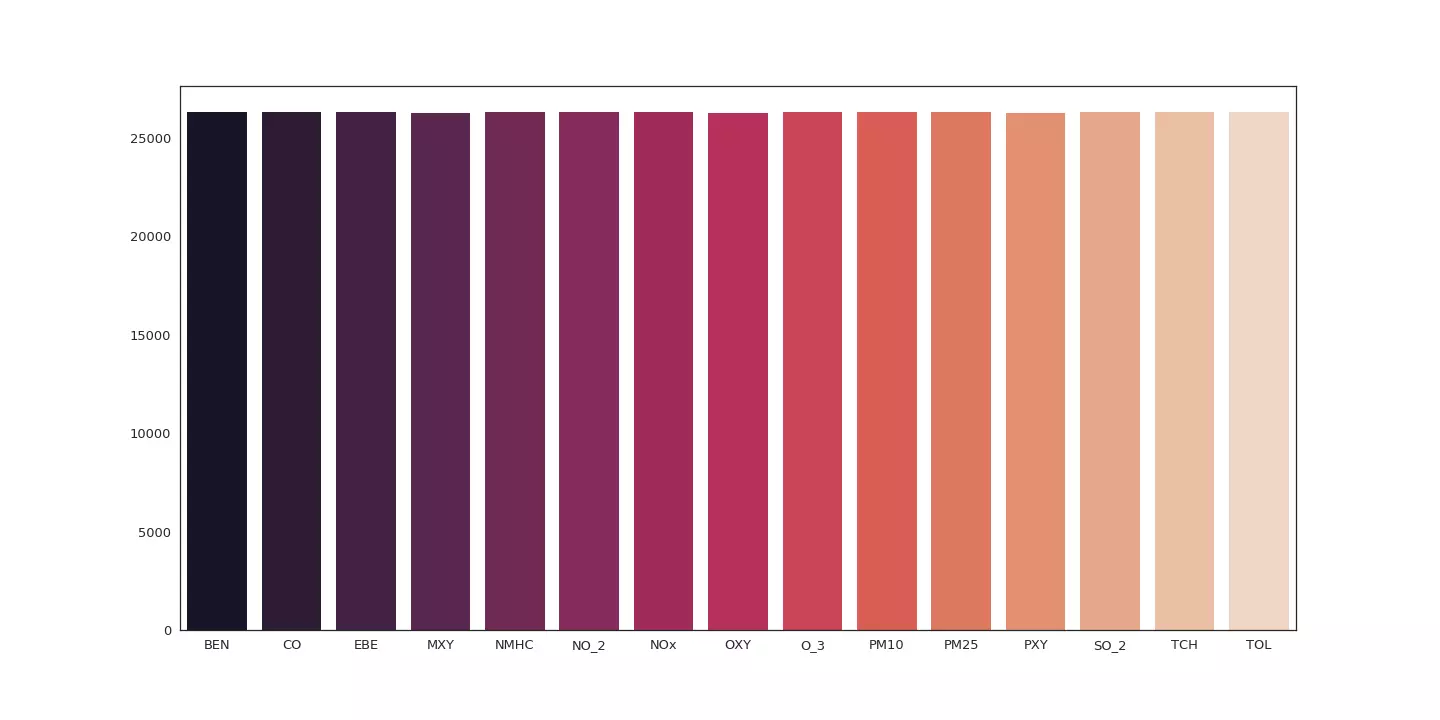
Seule la station 28079099 semble réaliser un sans faute !
Les données de cette station sont-elles réellement complètes ?
data_station = stations.get_group(28079099).copy()
data_station.set_index('date', inplace=True)
data_station.sort_index(inplace=True)
data_station[data_station.isnull().any(axis=1)]
Pas tout à fait. Pandas nous indique qu'une soixante de relevés manquent à l'appel. Un coup d'oeil rapide sur ces enregistrements problématiques nous montre que parfois seule une mesure manque. D'autres fois c'est un black-out total.
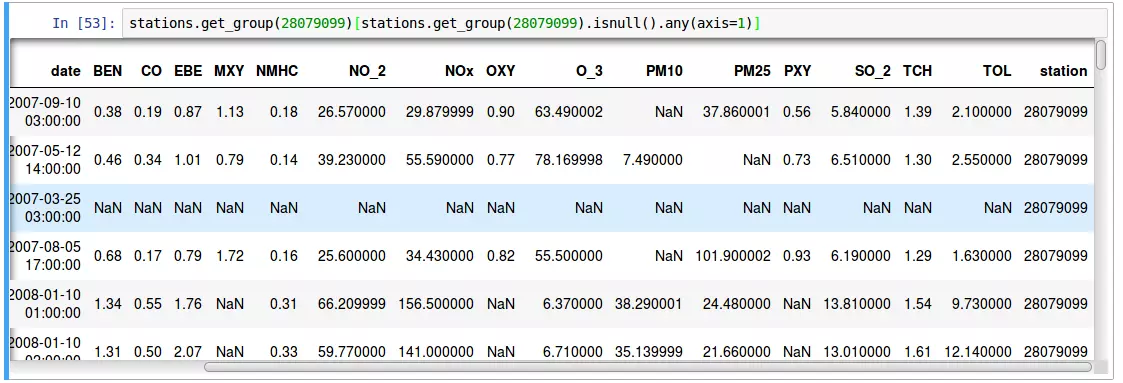
À la recherche des données perdues, avec Jupyter et Pandas.
Compléter les données
Comme nous voulons entraîner un algorithme de Machine Learning à prédire une mesure à partir des observations réalisées les jours précédents, ces données manquantes sont problématiques. À ce stade de notre analyse deux pistes s'offrent à nous : passer à une échelle de temps moins fine ou compléter les données manquantes par des données de synthèse.
Aidés de Matplotlib et Pandas, nous allons devoir continuer notre investigation pour nous orienter vers celle qui sera la plus pertinente.
Des données journalières
Avec Pandas et sa fonction rolling, calculer la moyenne journalière des relevés est un jeu d'enfant.
Toutefois la quantité de nos données se retrouve divisée par 24. Nous perdons également en précision.
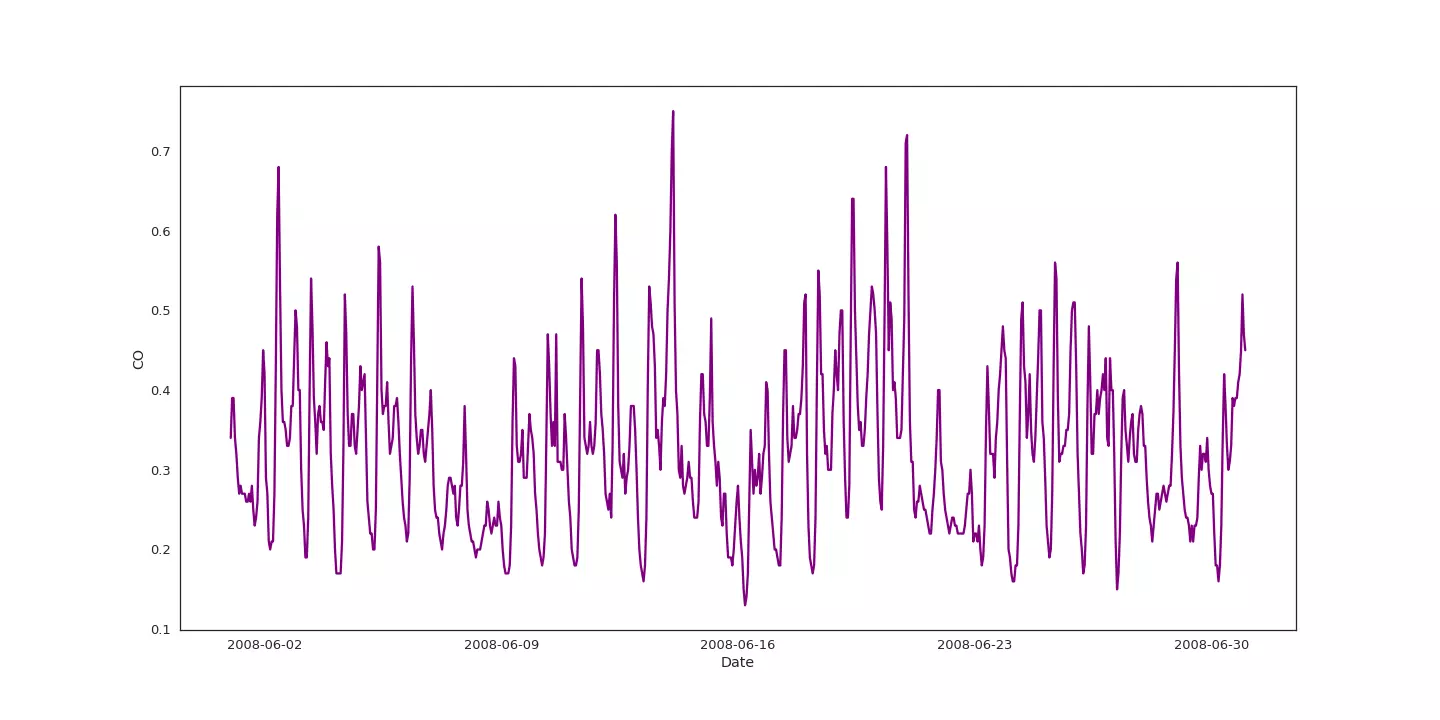
Évolution du taux de monoxyde de carbone durant le mois de juin 2008
Si nous regardons l'évolution du taux de monoxyde de carbone (CO) durant le mois de juin 2008, nous constatons que cette mesure semble évoluer de manière périodique.
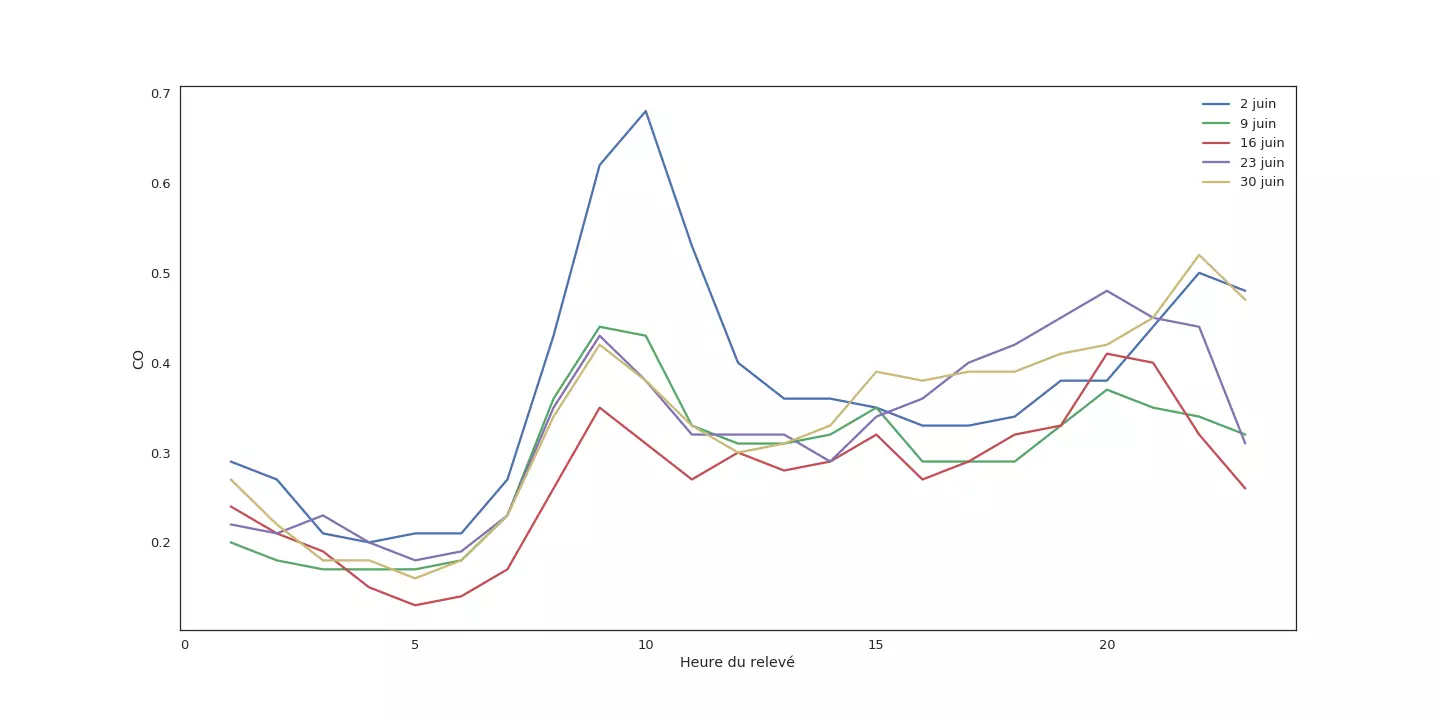
Évolution du taux de monoxyde de carbone au cours de la journée du lundi, durant le mois de juin 2008.
Une observation des données récoltées heure par heure, tous les lundis, de ce mois de juin 2008 est sans équivoque : le monoxyde de carbone augmente clairement autour de 10 heures, redescend vers midi et remonte, plus doucement, dans la soirée.
Si nous nous contentons de données journalières, nous risquons de manquer quelque chose.
Données de synthèse
Là encore deux options s'offrent à nous :
- remplacer les données manquantes par des données relevées à la même date d'une autre année ;
- interpoler les valeurs manquantes.
Commençons par observer comment évoluent les moyennes annuelles pour chaque mesure :
temp = data_station.drop(columns=['station']).dropna(axis=0).groupby(pd.Grouper(freq='Y')).mean()
plt.figure(figsize=(20, 10))
for column in temp.columns:
plt.plot(temp[column], label=column, marker='s')
plt.ylabel('Taux relevé')
plt.xlabel('Date du relevé')
plt.legend()
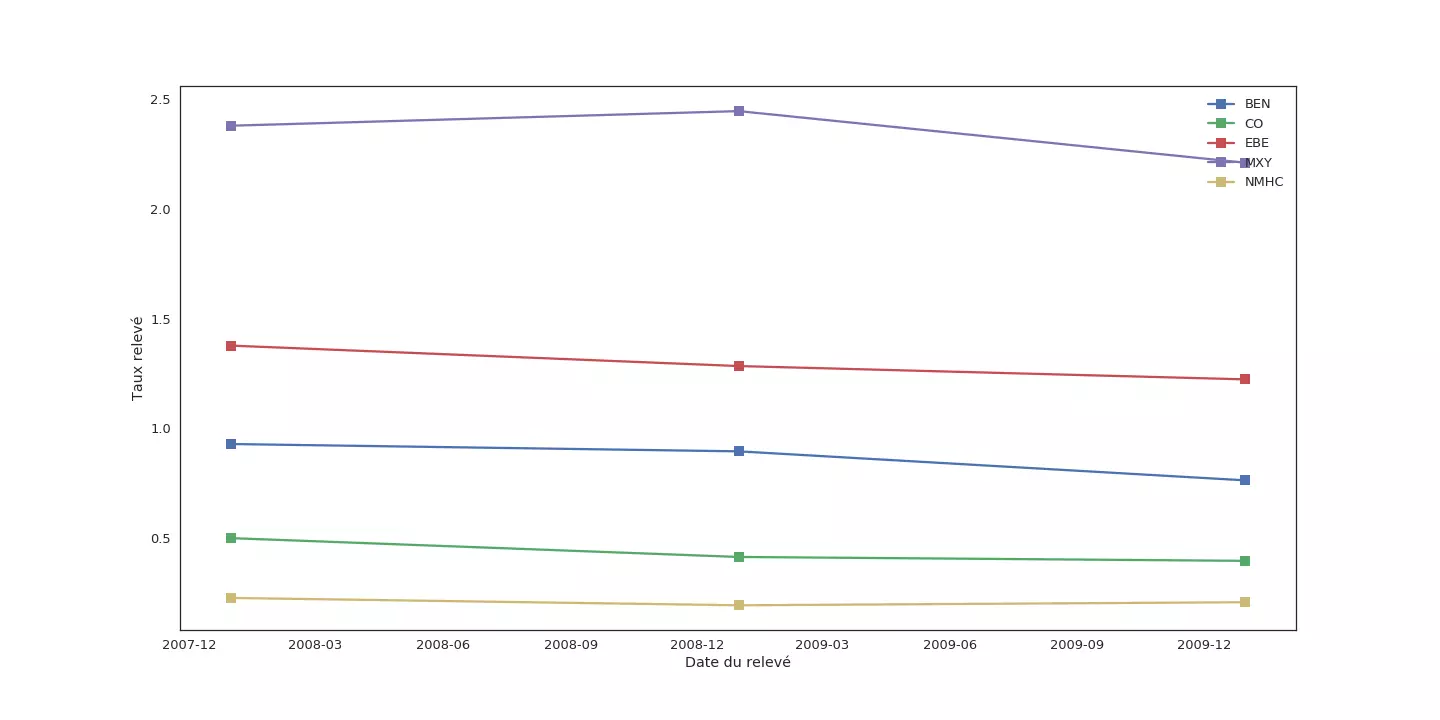
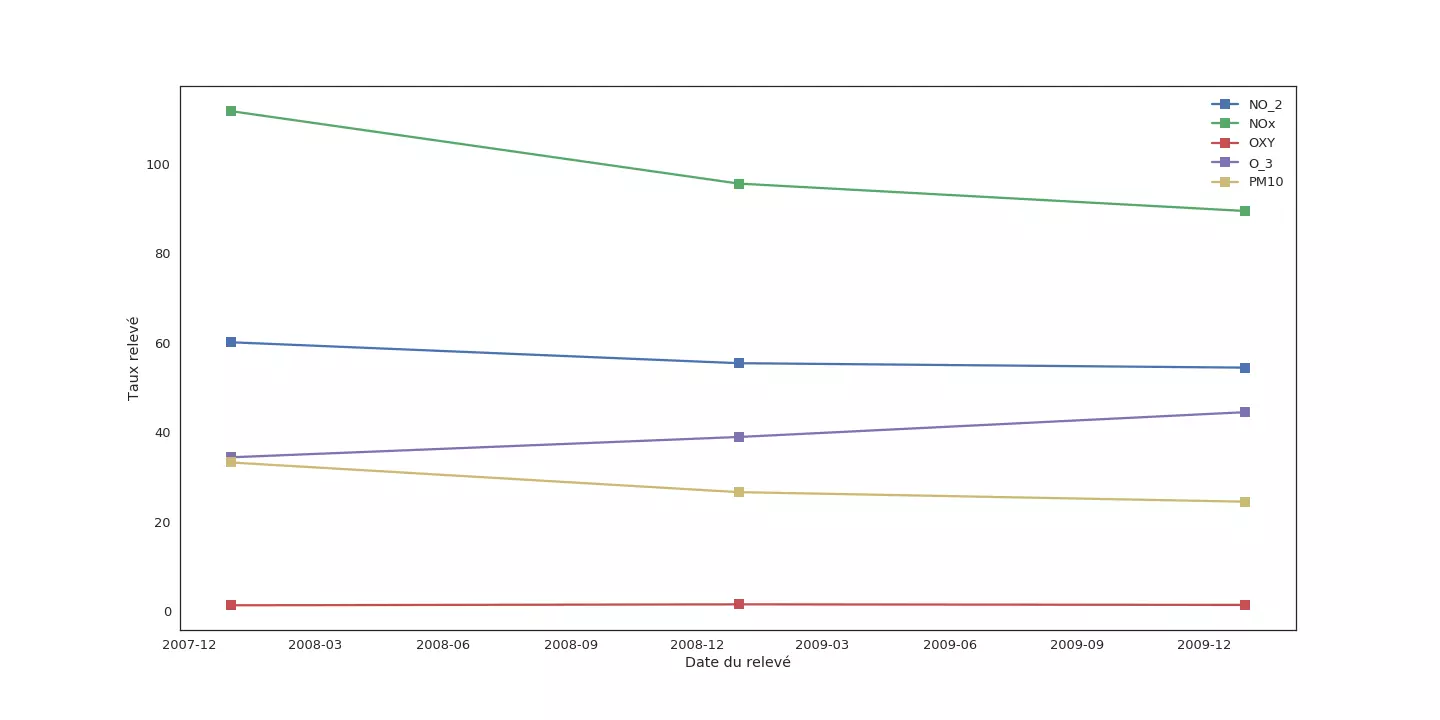
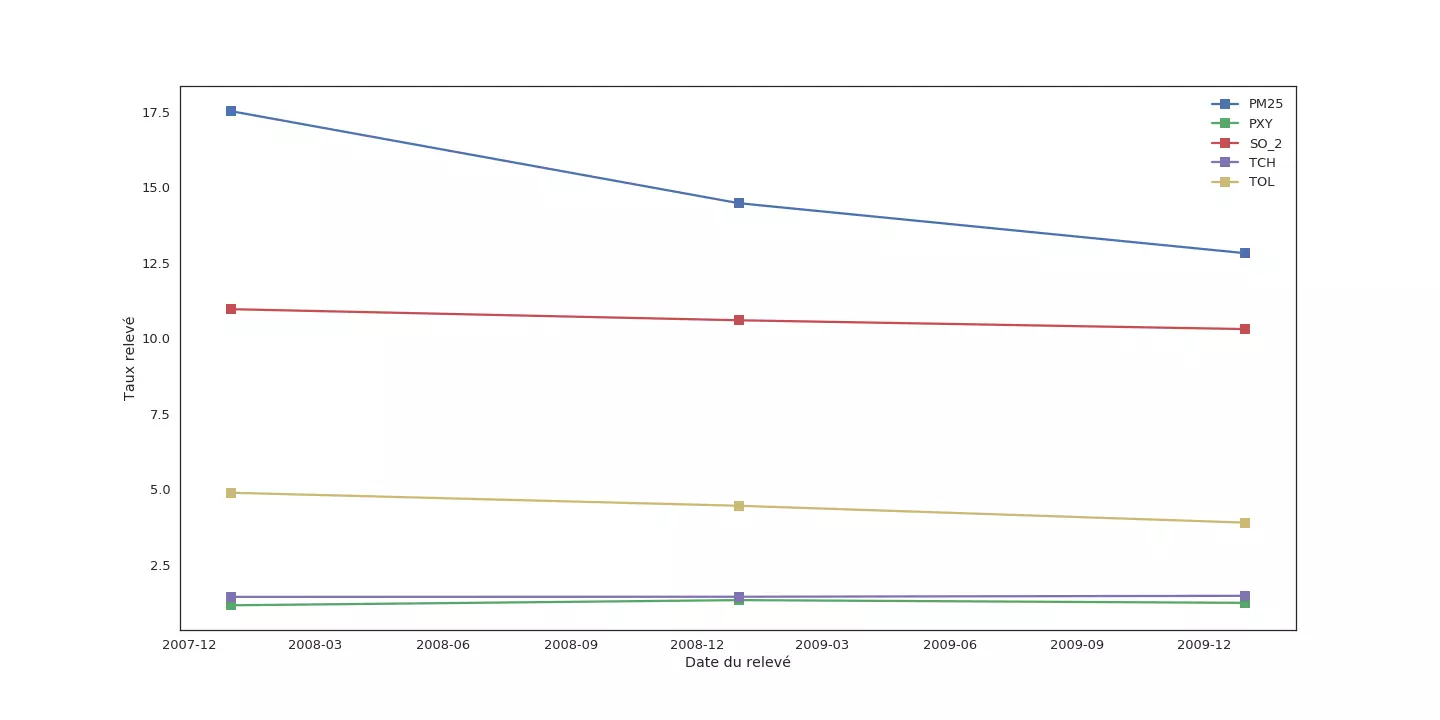
Si la moyenne de certaines mesures (PXY, TCH, OXY) semble ne pas varier sur les trois années, d'autres comme NOx sont moins stables. Pour ces mesures, remplacer une donnée manquante en 2008 par une donnée acquise en 2007 ou 2009 peut introduire une erreur importante.
Nous avons choisi d'être prudent et de nous contenter d'interpoler les mesures manquantes à partir des valeurs relevées juste avant et juste après. Nous avons opté pour une interpolation linéaire, afin de rester au plus près de nos données. Pandas - qui est presque parfait - propose une méthode interpolate pour compléter les données manquantes d'un DataFrame.
data_station.interpolate(inplace=True)
Prédiction du taux de monoxyde grâce à une méthode par apprentissage automatique
Nous avons choisi d'essayer de prédire le taux de monoxyde de carbone à partir des relevés réalisés sur les deux jours précédents.
Notre descripteur comprend donc les relevés pour les 15 mesures différentes sur 48 heures, soit au total 720 valeurs. Il s'agit des données que nous allons fournir à l'algorithme de Machine Learning pour lui permettre de réaliser une prédiction.
L'ensemble des descripteurs calculés est stocké dans un tableau X.
# create numpy array to store descriptors
nb_hours = 48
nb_releves = data_station.shape[0] - nb_hours
nb_measures = data_station.shape[1]
# to store descriptors
X = np.empty((nb_releves, nb_measures, nb_hours))
# compute and store all descriptors
for i in range(nb_hours):
X[:,:,i] = data_station.iloc[i:nb_releves+i]
À chaque descripteur nous associons le taux de monoxyde de carbone relevé à l'heure suivante. Comme nous voulons apprendre à prédire ce taux de monoxyde il faut que nous donnnions à l'algorithme de Machine Learning la valeur de monoxyde correspondant à chaque descripteur. À partir de ces exemples, l'algorithme apprendre à réaliser des prédictions pertinentes. Stockées dans un tableau Y, ces valeurs correspondent à ce que certains appellent une vérité terrain.
Y = data_station.CO.values[nb_hours:nb_hours+nb_releves]
Edit · article.md · master · Bérengère Mathieu _ article-prediction-monoxyde-madrid · GitLab Nous avons créé deux ensembles de données : un pour l'apprentissage (70% de nos données) et un pour tester que notre algorithme reste pertinent y compris sur des données différentes des données apprentissages (30%).
Comme nous travaillons sur de la donnée temporelle, nous nous sommes assurées que nos données d'apprentissage sont antérieures à nos données de tests.
nb_train = int(nb_releves * 0.70)
X_train, X_test = X[:nb_train,:], X[nb_train:,:]
Y_train, Y_test = Y[:nb_train], Y[nb_train:]
Un jeu, avec Pandas qui ordonne les données par ordre chronologique !
Auto-Sklearn
Actuellement les méthodes Deep Learning ont le vent en poupe et nous privilégions leur usage dans nos projets de Machine Learning. Toutefois, lorsque nous entraînons une méthode de zéro comme c'est le cas ici, nous faisons généralement un test avec Auto-Sklearn.
Auto-Sklearn s'appuie sur la bibliothèque Scikit Learn qui met à disposition un grand nombre de méthode de Machine Learning. Elle permet de sélectionner, de paramétrer et d'entraîner automatiquement un ensemble d'algorithmes. À chaque algorithme, elle associe un score de confiance. La prédiction finale n'est pas celle d'un seul algorithme, mais de chaque méthode sélectionnée pondérée par son score de confiance. Le tout forme ce que les anglophones nomment "a committe machine".
La combinaison de plusieurs algorithmes, chacun spécialisé sur des aspects différents des données, est connue pour donner de meilleurs résultats que l'utilisation d'une unique méthode, aussi performante soit-elle.
automl = autosklearn.regression.AutoSklearnRegressor()
automl.fit(scaled_X_train, Y_train)
automl.show_models()
Résultats et limites d'AutoSklearn
Le committe machine comprend 4 algorithmes, avec des scores de confiance similaires pour les trois premiers (de 0.34 à 0.24) et très faibles pour le dernier (0.04). Les trois algorithmes dominants sont la méthode des plus proches voisins, l'algorithme de régression de Ridge et l'algorithme du Gradient Boosting. À chaque fois AutoSklearn a trouvé pertinent d'appliquer des pré-traitements sur les données.
Sur les données de test, les prédictions du committe machine obtiennent un coefficient de détermination de 0.81. Le coefficient de détermination étant une valeur comprise entre 0 et 1, avec 1 la meilleure valeur possible, ce résultat est loin d'être décevant.
La figure suivante présente un diagramme boîte à moustache sur les écarts entre la prédiction et la valeur attendue. Il indique que l'écart maximal est inférieur à 0.8. Nous constatons aussi que 75% des prédictions ont un écart inférieur 0.1. Afin de vous donner un ordre d'idée de l'écart possible, la valeur minimale pour le taux de monoxyde est de 1 et la valeur maximale est de 3.6.
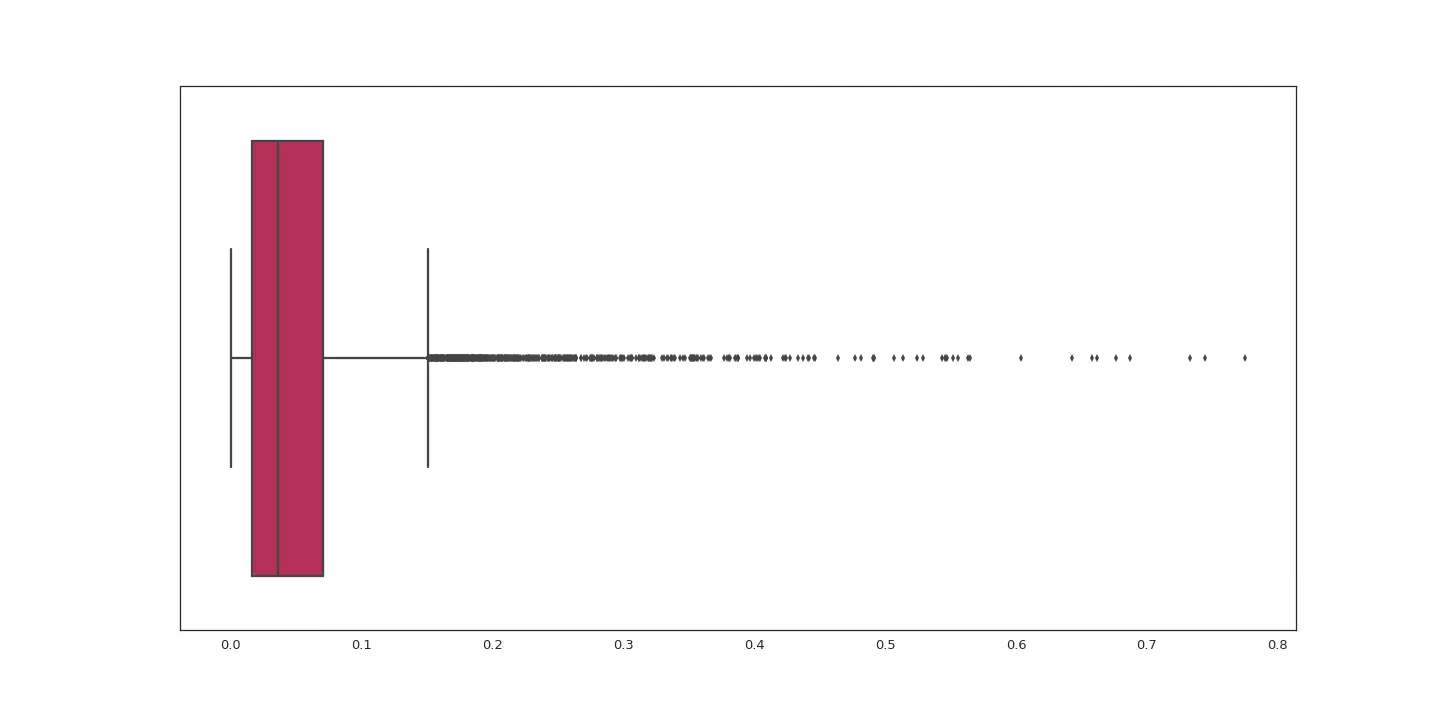
Analyse statistique de l'écart (valeur absolue de la différence) entre les prédictions et le résultat attendu.
Si nous souhaitons améliorer notre prédiction, nous pourrions décider de ne pas nous limiter aux données collectées sur les deux jours précédents. Ce faisant la taille de notre descripteur va augmenter et avec elle l'espace mémoire ainsi que le temps nécessaire à l'apprentissage du committe machine.
Les résultats obtenus par AutoSklearn vont nous servir de base à l'analyse de ceux atteints avec une approche par apprentissage profond (Deep Learning). Lors de nos projets, nous réalisons rapidement quelques tests en partant d'architectures Deep Learning validées sur des problèmes similaires. Si les résultats obtenus concurrencent ceux d'AutoSklearn, nous envisageons de consacrer un peu plus de temps à l'amélioration des modèles testés. Mais si rien de mirobolant n'en sort, nous évitons de nous embarquer plus en amont dans le Deep Learning - qui peut se révéler une aventure très chronophage sans garantie de réussite.
Deep Learning
En plus d'AutoSklearn, nous avons testé un réseau de neurones récurrent, de type LSTM. Dans un réseau standard, un neurone se contente de recevoir de l'information venant des neurones de la couche inférieure. Dans un réseau récurrent, les neurones d'une même couche sont connectés, de la gauche vers la droite.
Lorsque ce type de réseau utilise des couches de type LSTM, chaque neurone dispose en plus d'une connexion à une mémoire générale. Ce neurone ne fait pas que sélectionner une partie de l'information qu'il reçoit pour le transmettre aux neurones de la couche supérieure : il va également décider de ce qu'il renvoie aux neurones à sa droite et de comment il met à jour la mémoire générale. Ainsi, les réseaux LSTM ne sont pas seulement pourvus d'un mécanisme de mémorisation mais également d'une capacité d'oubli. Ces réseaux se révèlent ainsi très performants pour analyser des données temporelles.
Pour nos tests, nous avons commencé avec une architecture simple :
- une couche d'entrée pour récupérer les données ;
- une couche de normalisation des données par lot ;
- une couche LSTM avec 100 neurones ;
- une Couche LSTM avec 50 neurones ;
- un neurone avec des connexions dense, pour prédire le taux de monoxyde de carbone.
Grâce aux bibliothèques Tensorflow et Keras écrire le code pour la création, la compilation et l'entraînement de ce réseau ne nous ont pas pris plus de quelques minutes.
# create network
model = Sequential()
model.add(BatchNormalization(input_shape=(nb_measures, nb_hours)))
model.add(LSTM(100, return_sequences=True, dropout=0.5))
model.add(LSTM(50, dropout=0.5))
model.add(Dense(1))
# compile network
model.compile(loss='mean_squared_error', optimizer='adam')
# train network
model.fit(scaled_X_train.reshape((nb_train, nb_measures, nb_hours)), Y_train,
epochs=100, batch_size=64, callbacks=[history])
Résultats et perspectives
Première chose à vérifier : est-ce que ce fichu réseau apprend ? Pour en être certain, il suffit de suivre l'évolution de la fonction de coût. Dans notre cas elle se base sur l'erreur quadratique moyenne. Cette dernière est supposée se rapprocher de 0 au fil de l'apprentissage. La figure suivante montre que c'est bien le cas :
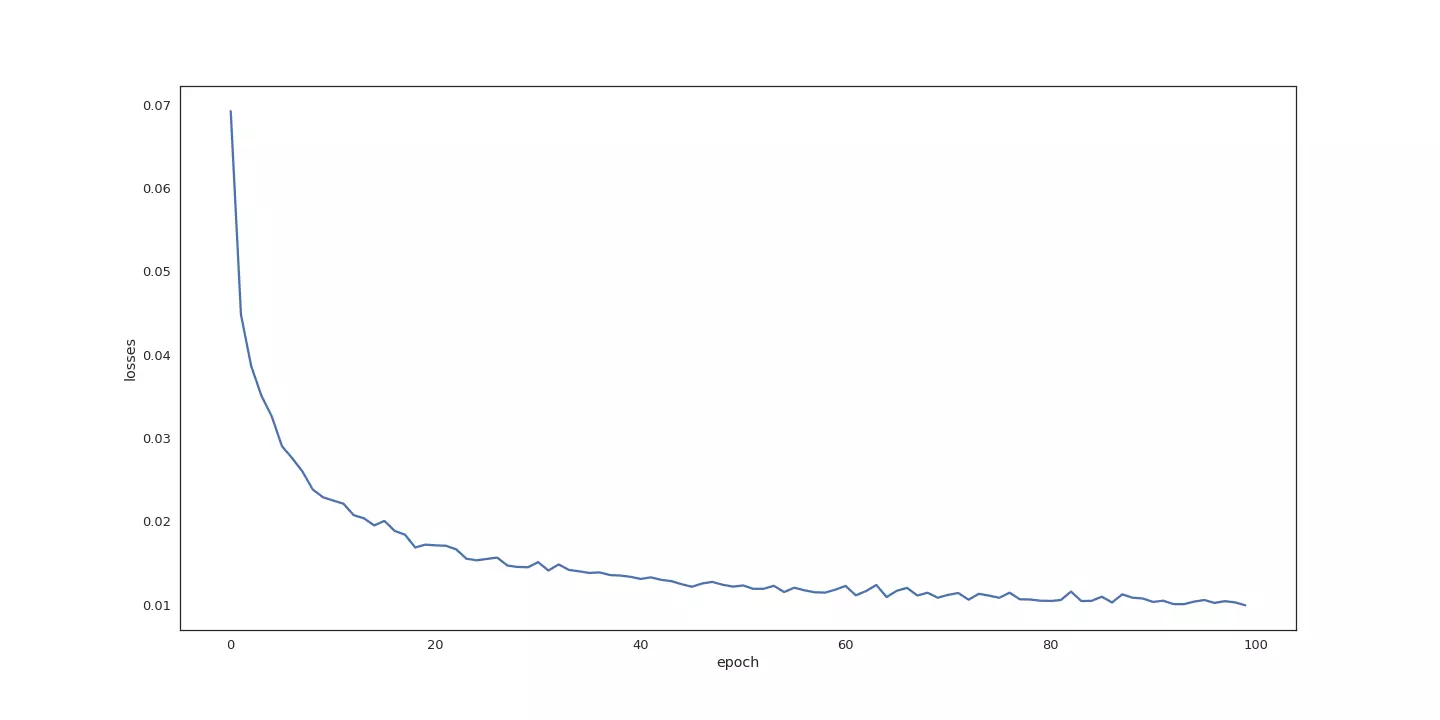
Évolution de l'erreur quadratique moyenne, lors de l'apprentissage du réseau.
Le coefficient de détermination obtenu par notre réseau, de 0.84, est légèrement plus haut que celui d'AutoSklearn. Si nous étions dans le cadre d'un projet réel, il nous suffirait pour valider une exploration des approches Deep Learning.
Si nous observons l'évolution des prédictions et des valeurs attendues sur deux jours, nous constatons que les similitudes entre les deux courbes sont plutôt encourageantes.
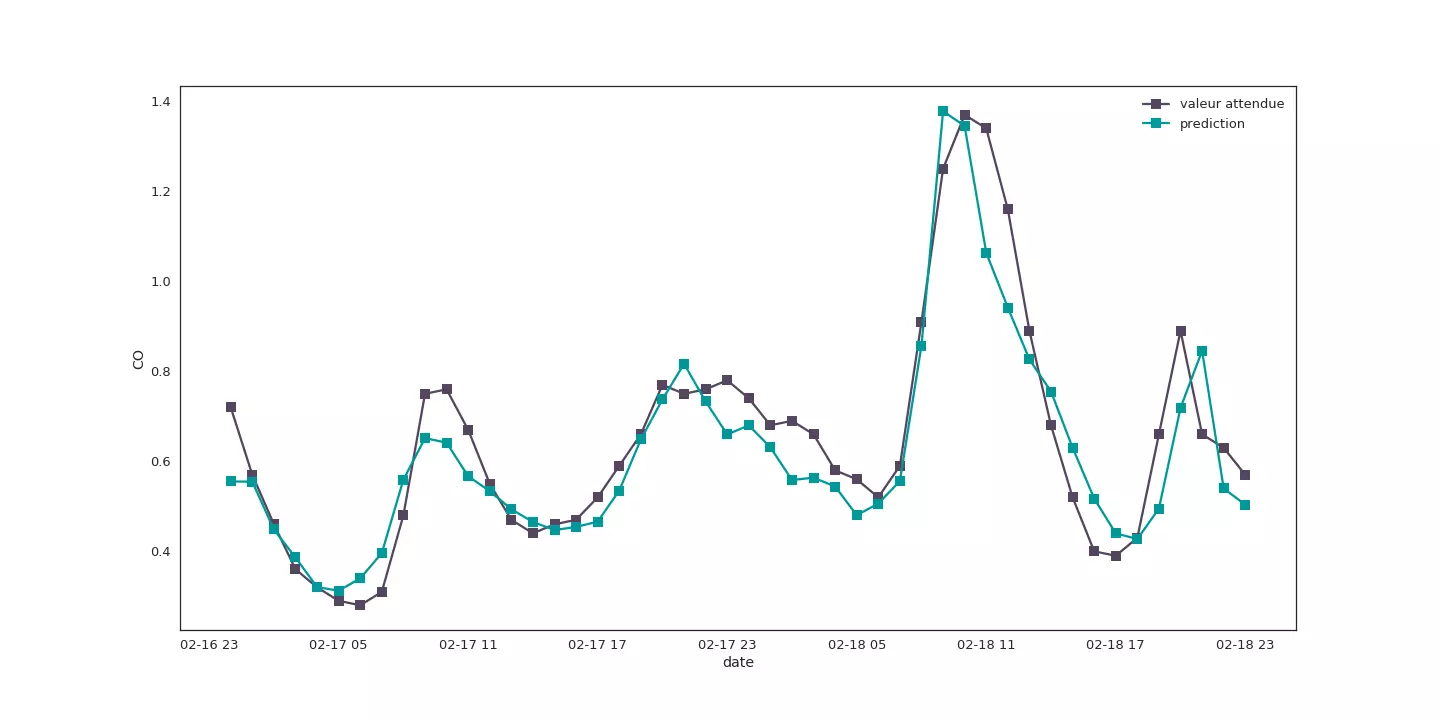
Taux de monoxyde prédis et prévu sur du 16 au 18 février 2009.
La comparaison du diagramme boîte à moustache sur l'écart entre les valeurs prédites et les valeurs attendues montre que globalement les prédictions réalisées par le réseau de neurones sont aussi stables que celles réalisées par la méthode d'AutoSkLearn.
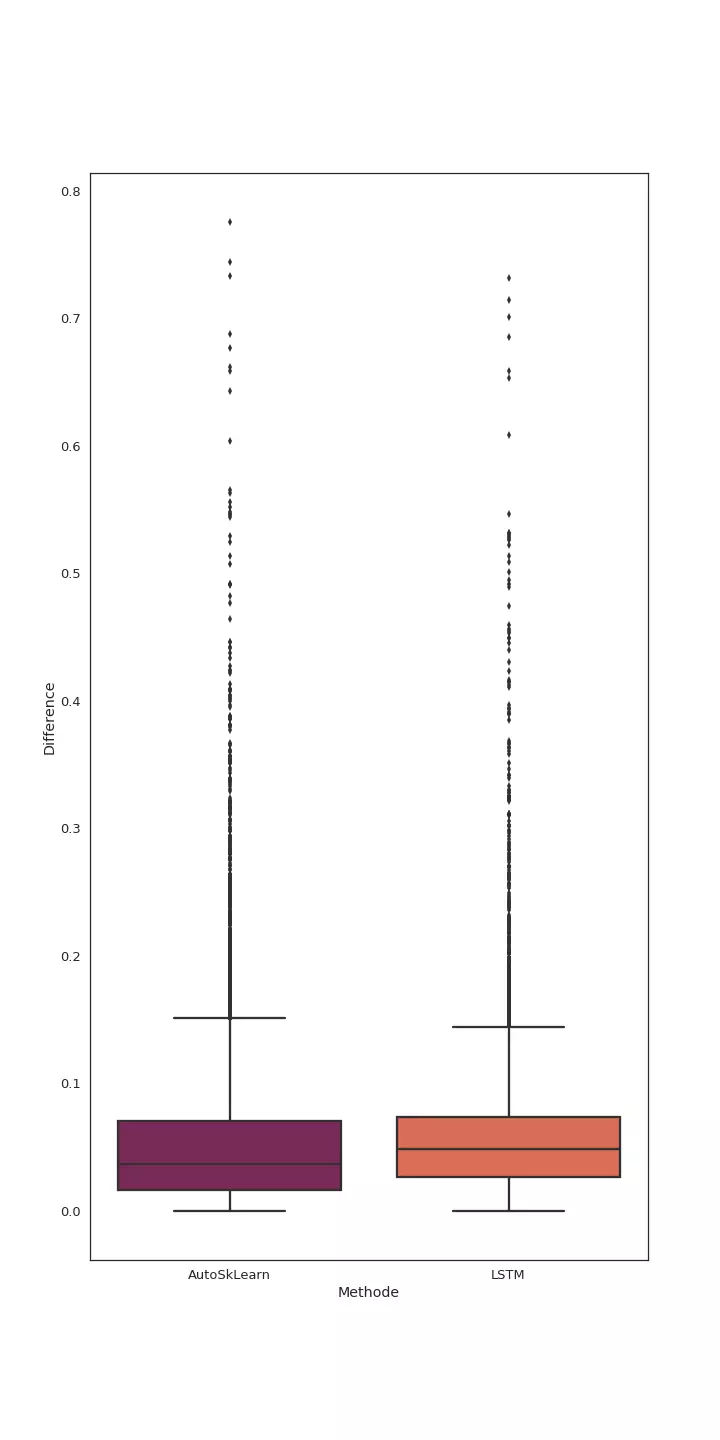
Analyse statistique de l'écart (valeur absolue de la différence) entre les prédictions et le résultat attendu : comparaison des deux approches.
Conclusion
Une suite intéressante de nos travaux consisterait à construire un réseau capable de prédire davantage que le taux de monoxyde et de fournir un résultat pour chacune des 15 mesures.
Observer l'amélioration de ces prédictions en fonction du nombre de données temporelles fournies constituerait également une piste prometteuse. Enfin, nous pourrions tester un Committe Machine constitué de plusieurs réseaux de neurones et non des algorithmes fournis par Scikit Learn.
Les données fournies par la ville de Madrid constituent une excellente base pour s'initier au Machine Learning comme au Deep Learning. Nous aurons l'occasion de poursuivre son exploration lors de nos prochaines sessions de formation Deep Learning. Si le sujet vous intéresse il ne nous reste plus qu'à y participer !

Experte data science
Formations associées
Formations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasActualités en lien
Extraction d'objets pour la cartographie par deep-learning : choix du modèle
SIG
02/06/2020
Deuxième article de la série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires.

Extraction d'objets pour la cartographie par deep-learning : création d'une vérité terrain
SIG
18/05/2020
Cette série d'articles parle de cartographie par deep-learning à partir d'images aériennes ou satellitaires. Dans ce 1er article, l'étape préliminaire à toute utilisation d'un modèle d'apprentissage supervisé est abordée: la création du jeu de données d'apprentissage. Notre outil geolabel-maker est mis à votre disposition pour vous aider.

Deep Learning et détection d'émotions
Data Science
12/04/2018
Un premier pas dans le Deep Learning pour la détection d'émotions à partir de photographies.
