Makina Blog
Profiling Drupal : analyser et optimiser les performances du trafic authentifié
Les solutions pour optimiser les performances de Drupal avec du trafic anonyme sont nombreuses. Avec du trafic authentifié, les solutions existantes sont plus complexes et masquent souvent un problème de conception en amont. Il est préférable dans un premier temps d'analyser son application pour identifier les goulots d'étranglements puis de les améliorer.
Bien souvent, Drupal est utilisé avec du trafic anonyme uniquement. Afin de drastiquement améliorer les performances du CMS, on a recours à des politiques de cache de pages complètes plus ou moins simple à mettre en place :
- cache de page Drupal basique
- reverse proxy cache (Varnish, Nginx)
- …
Mais pour du trafic avec des utilisateurs connectés (sessions utilisateurs actives), ces politiques de cache sont plus dur à mettre en place. En règle générale, on essaye alors dans la mesure du possible de cacher certains morceaux de pages :
- ESIgate
- cache de bloc Drupal
- cache partiel de page avec Varnish + AJAX en POST pour les données authentifiées
- …
Bien que souvent utiles, ces politiques de cache peuvent masquer des problèmes de conception en amont. Et si ce cache est par exemple momentanément indisponible, peu d'utilisateurs connectés simultanés pourraient être supportés sans avoir des serveurs surdimensionnés.
Dans un premier temps, il convient donc de régler le problème à la source. Dans cet article, nous allons uniquement nous concentrer sur les optimisations au niveau de l'application, en dehors de tout environnement. Autrement dit, juste au niveau du code, et côté serveur (l'optimisation côté client fera l'objet d'un article ultérieur). C'est le type d'analyse que nous fournissons lors d'un audit de performance web.
Outils de profilage et présentation
Afin d'analyser un site Drupal, on va utiliser ici Xdebug et sa fonctionnalité de profilage. Nous ne parlerons pas ici de XHProf, qui offre l'avantage de mesurer l'usage mémoire en plus d'être très léger (usage en production). Nous supposons que vous avez déjà installé et configuré Xdebug pour utiliser le profilage. Petite astuce : afin de trier naturellement vos traces de profilage, nommer les fichiers de traces avec un motif incluant l'heure courante. Par exemple :
xdebug.profiler_output_name=cachegrind.out.%u.%p
Afin d'interpréter les résultats du profilage, on peut par exemple utiliser un client comme KCachegrind. Et pour vous simplifier la vie, vous pouvez installer des plugins (comme Xdebug helper) pour votre navigateur afin d'envoyer les bons cookies à PHP ("XDEBUG_PROFILE") lors de la navigation sur le site. Garder à l'esprit que vos scénarios doivent être simples et communs : un utilisateur connecté sur des pages à fort trafic en front office. Évitez notamment les rôles utilisateurs particuliers ou des pages peu fréquentées.
Avec ce type de trace, on peut facilement identifier pour une fonction :
- le nombre d'appels de fonction ;
- la durée totale des appels (de la fonction elle-mêmes ou incluant les appels enfants). Attention, la durée d'exécution des fonctions dépend de votre environnement. Elle n'est donc pas forcément pertinente et vous ne devez pas la prendre en compte. Cependant, on peut (très grossièrement) deviner ce qu'il faut optimiser ou pas ;
- avoir la pile d'appels depuis une fonction, notamment pour trouver les coupables !
- …
Les principaux goulots d'étranglements
- Les échanges avec des services externes : requêtes SQL (quantité, type : lecture/écriture, optimisation), mais également les requêtes HTTP (plus rare mais beaucoup plus longues) ;
- Les I/O du système de fichiers (inclusion de fichier, file_exists() inutiles…). Il est vrai qu'avec l'OPcache, ça n'est pas toujours vrai et que cela dépend aussi de l'environnement. Mais cela reste tout de même un point à surveiller ;
- l'usage répété / abusif de méthodes récursives.
Analyse d'un fichier de profilage
On va se connecter avec un utilisateur lambda et aller sur la page d'accueil. On va profiler la même page 2 ou 3 fois de suite. En effet, parfois, certaines requêtes d'écritures aléatoires apparaissent (comme l'historique de navigation des contenus, certaines constructions de caches…). De plus, vous aurez parfois plusieurs traces relatives à chaque bootstrap de Drupal : appel ajax, mais également génération des styles d'image manquants… Donc plusieurs traces de la même page sont nécessaires afin de trouver la trace qui semble être la plus commune, aussi bien pour la page principale que pour les appels ajax (qui doivent eux aussi être profilés) !
Ouvrez ensuite le fichier de trace avec KCachegrind. Le poids de la trace est déjà significatif en lui-même. Une trace de 2,4 Mo n'est pas une trace de 5 Mo ! Vous pourrez donc déjà grincer des dents d'avance ou pas ! De même, quand vous avez plusieurs traces pour une même page (appel ajax ou autre), vous pouvez facilement identifier la page principale (poids le plus lourd).
Un des premier réflexes consiste à trier les fonctions par temps d'exécution de la fonction elle-même. En effet, le temps d'exécution de la fonction n'inclut pas le temps d'exécution totale incluant les appels en profondeur (sinon, ça n'est plus mesurable). Dans notre cas, on obtient en premières lignes :
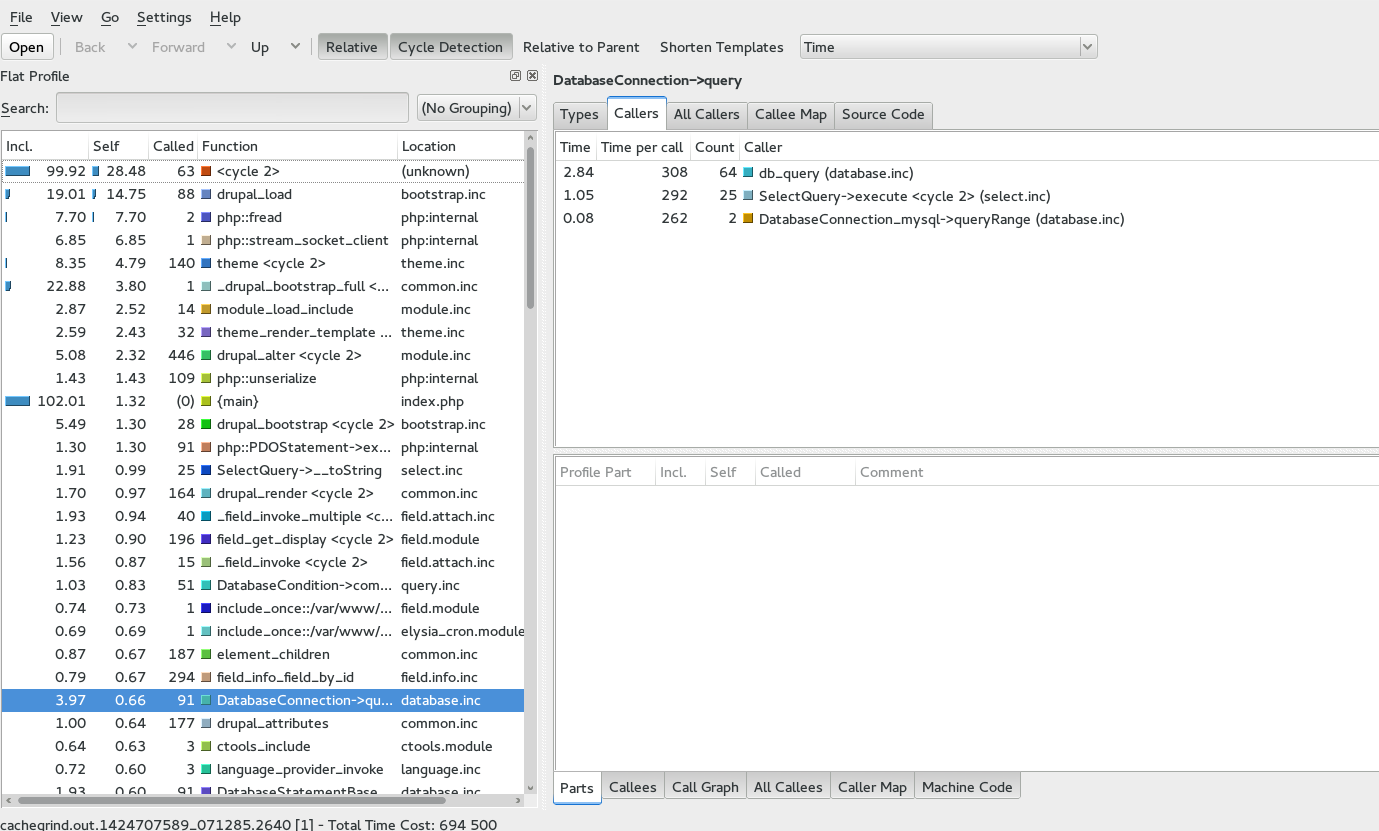
Très vaguement, outre la requête HTTP effectuée par drupal_http_request, vous retrouverez ce genre de traces d'un projet à un autre. Par ailleurs, on voit bien ici qu'il n'y a pas d'OPCache actif, d'où le temps perdu avec les inclusions de fichiers.
php::PDOstatement : cette dernière indique le nombre de requêtes (ici 91, qui est correct pour une page Drupal). Vous pouvez ensuite facilement naviguer dans la pile d'appel en double-cliquant sur la fonction, puis sur ses enfants, ou revenir au parent…
Si on regarde de plus près, on a :
php::PDOstatement > DatabaseStatementBase->execute > DatabaseConnection->query
Après, les appelants sont différents. Notamment :
- db_query : généralement du cache, mais aussi les chargements d'entités, de champs etc. C'est la plus utilisée ;
- SelectQuery->execute : généralement du code personnalisé, des Views : db_select() ;
- DatabaseConnection_->queryRange() : très rare, correspond à db_query_range (menu_get_item()), tableExists() (Ce qui n'est pas terrible sur une page d'accueil, merci CTools et Metatag !).
Grâce à ces traces, vous pouvez donc rechercher quels sont les plus gros consommateurs, dont voici une liste non exhaustive.
Les hooks *_load(), tueurs de performance
Quand on chasse la requête, le plus frappant, c'est le nombre phénoménal de requêtes bien souvent inutiles effectuées via les hook *_load() :
- hook_entity_load()
- hook_ENTITY_TYPE_load() comme hook_node_load()
- …
Généralement, ces hooks sont implémentés par souci de simplicité (comprenez facilité ;-)) sans se demander quels sont les réels besoins : a-t-on vraiment besoin à chaque chargement de l'entité d'avoir ces données ? Est-ce vraiment utile pour une intégration avec d'autres modules comme Entity et ses fameuses metadata ? À tel point qu'un des premiers réflexes à avoir pour juger de la qualité d'un module se vérifie avec ces implémentations. Ne vous y méprenez pas, ils ont parfois bien sûr une utilité.
À titre d'exemple et pour ne citer qu'eux :
- le module Scheduler (en version 7.x-1.3) implémente le hook_node_load() et charge les dates de planifications de vos contenus. Cela fait une requête pour un node_load_multiple(), ce qui n'est pas catastrophique en soi. Mais si vous avez par exemple 6 listing de contenus sur votre page, cela fait également 6 node_load_multiple() et donc 6 requêtes pour récupérer des planifications qui … ne vous serviront sûrement à rien en front-office sur votre page d'accueil ! Rappelons qu'en principe, c'est vraisemblablement utile uniquement dans les tâches de cron pour planifier la publication / dé-publication…
- le module Metatag (7.x-1.4) implémente le hook_entity_load() et pour chaque type d'entité supportée (par exemple les nœuds) tente de charger des entités metatags. Pour rappel, charger des entités, c'est au moins 1 requête dans la table de base de l'entité et 1 requête de cache pour les champs. Quoiqu'il en soit, même constat que pour Scheduler, 6 listings de contenus en résumé ~= 6 à12 requêtes inutiles. Là encore, il semblerait que les metatags ne vous soient utiles que pour votre page, pas pour des bouts de page !
- toujours dans le même esprit, le module User du cœur tente vainement de charger les entités utilisateurs des auteurs des contenus (qu'importe que leurs noms soient affichés ou non). Cela dit, cet effet reste mitigé et limité par l'usage du cache statique si vous avez plusieurs fois le même auteur.
- un dernier exemple pour finir : le module Comment du cœur. Si les commentaires sont actifs pour un type de contenu, les statistiques de ces commentaires sont chargées. Pas forcément utile, surtout si vous n'affichez pas le nombre de commentaires par exemple.
Bref, l'idée n'est pas tant de taper sur les doigts de certains modules (la liste est longue sinon), mais plutôt de constater que ces hooks sont dangereux, parfois inutiles et que leur nombre cumulé est une catastrophe ! Rien qu'avec une dizaine de modules ayant des implémentations similaires, on a donc 6 * 10 = 60 requêtes SQL purement inutiles. Pour ce type de hook, il convient donc de surveiller d'avantage vos pages de listing de contenus à fort trafic (page d'accueil notamment).
Quelles sont les solutions ?
- Pour les modules personnalisés, il faut remplacer ces hooks si possible. Si les données sont nécessaire pour de l'affichage en masse (listes), utilisez plutôt un hook comme hook_entity_prepare_view() qui est parfaitement adapté pour cela. En règle plus générale, ciblez les moments opportuns pour charger ces informations.
- Pour les modules communautaires, à part tenter de bricoler avec des hook_module_implements_alter() ou hacker le cache statique des modules quand ils en ont (autant de mauvaises pratiques à éviter absolument pour la maintenance de votre projet), il ne vous reste parfois pas grand chose. En effet, malheureusement, certains modules souffrent de leur histoire et ne peuvent pas changer cette conception sans engendrer certaines régressions ou incompatibilités (d'autres modules peuvent par exemple espérer avoir ces infos au chargement de l'entité). De même, des tentatives de patch spécifiques à votre projet pourraient poser des soucis évolutifs à terme. Donc le plus souvent, vous devrez faire avec mais au moins, vous tiendrez les coupables !
Access callbacks et requêtes redondantes
Les access callback de vos entrées de menus sont souvent appelées plusieurs fois (entrée de menu, mais aussi les liens de menu). Par conséquent, si vous exécutez des requêtes SQL ou des opérations lourdes, pensez à cacher statiquement le résultat avec une indexation numérique limitée. Sauf exception, vos contextes seront d'ailleurs probablement limités (utilisateur courant, etc), donc il y a peu de risque de saturer l'espace mémoire !
Menu router et liens de menus, une complexité coûteuse
Soyons honnête : les personnes qui ont écrit le fichier menu.inc (remplaçable avec la variable menu_inc) se sont levées très tôt ! C'est probablement le fichier le plus complexe et le plus magique de Drupal. Il y a de très bonne choses (un nombre important de fonctionnalités, un effort indéniable pour les performances comme le stockage normalisé des liens parents entre autre), mais aussi des moins bonnes qu'il est beaucoup plus simple de constater que de comprendre complètement !
Par exemple, pour une page dont l'entrée dans le menu router n'a pas de menu_name explicite (via hook_menu), elle hérite par défaut du menu navigation. Quand le menu est reconstruit, les liens de menus sont synchronisés avec le menu router. Un lien dans le menu navigation va donc être crée pour cette page. Quand vous allez sur la page, le titre et le fil d'Ariane vont par défaut être construits à partir du lien considéré comme "préféré" (menu_link_get_preferred(), déduit depuis le chemin courant puis des ancêtres). Autrement dit, le menu courant considéré est navigation (ce qui n'est probablement pas votre cas mais plutôt main-menu ou un autre). Tous les liens de ce menu navigation considérés comme actifs sont chargés (menu_get_active_trail()) à savoir les parents, le lien lui-même mais aussi les autres liens qui n'ont pas de parent ! Et pour chacun d'entre eux, les access callback sont exécutés (menu_tree_check_access). Ainsi par exemple avec le module Scald actif en front-office, vous effectuez des requêtes de vérifications d'accès pour le chemin /scald/add (qui est aussi un lien du menu navigation sans parent) quand bien même le lien n'est pas affiché !
Afin d'éviter d'avoir le menu navigation pour la page courante, vous pouvez :
- créer des liens de menu cachés (attribut hidden) pour le menu souhaité associé au chemin de l'entrée de menu (menu router) ;
- forcer votre entrée de menu dans le hook_menu à utiliser le bon menu avec l'attribut menu_name. Vous pourrez toujours ultérieurement surcharger le lien généré automatiquement (_menu_link_build) par un lien de menu manuel (attribut custom).
Tout cela devrait faire parti des bonnes pratiques.
A noter qu'il est bien plus intéressant de supprimer toutes cette partie si :
- vous êtes audacieux et pas frileux (!)
- vous n'avez pas de fil d'Ariane (ou fait manuellement)
- vous n'avez pas de gestion de titre atypique.
Vous pouvez alors simuler le pré-calcul de menu_set_active_trail() et de drupal_set_title() en jouant sur leur cache statique ; voir réécrire le menu.inc. Vous gagnerez 6 petites requêtes et surtout beaucoup de code inutile. L'effort n'en vaut cependant souvent pas la chandelle et vous aurez sûrement bien mieux à optimiser.
Conclusion
Nous avons vu ensemble seulement quelques goulots d'étranglement potentiels avec Drupal. La liste est longue et spécifique à chaque projet. C'est pourquoi il n'existe pas de méthode magique et que chaque projet Drupal nécessite un profilage spécifique.
Une des règles à retenir est surtout de se concentrer sur le nombre de requêtes SQL à diminuer. Requêtes de cache comprises (donc non déportées dans d'autres back-end comme Redis ou MongoDB), obtenir un nombre avoisinant les 150 requêtes SQL est grossièrement correct (mais pas satisfaisant ! Moins de 50, c'est bien mieux et pas impossible selon les projets !). Idéalement, surveillez aussi l'utilisation mémoire (avec d'autres outils comme XHProf).
Cependant, veuillez à ne pas non plus plonger dans un excès de chasse à la requête ! Cela est rarement le seul point bloquant et peut parfois aboutir à des problèmes de maintenance plus graves (développement de code complexe afin d'éviter quelques requêtes). Il convient donc de trouver un bon compromis.
Si vous trouvez que votre site a des problèmes de performance, contactez-nous pour réaliser un audit.

Geotrek-Django-Python-CSS
Actualités en lien
Bibliothèque d’authentification OpenID Connect Django
Django
08/04/2025
DbToolsBundle, sortie de la version 2
Symfony
18/03/2025
Drupal SEO Recipe
Drupal
14/01/2025
