Makina Blog
Retour d'expérience sur la réalisation d'un portail Drupal mêlant cartographie et Open Data
Utilisation de Drupal comme outil centralisateur de flux.
Nous avons réalisé le portail des transports dans la région de Bruxelles-Capitale. Ce fut l'occasion de mettre en oeuvre le CMS Drupal sur un gros site mêlant cartographie et Open Data à destination des citoyens des 18 communes de cette région de Belgique. Cet article vise à partager différents points que nous avons travaillés au cours de ce projet.
Choix de la version de Drupal
Cela peut sembler un peu étrange de mettre en ligne en 2017 un site Drupal 7. Mais au moment du démarrage du projet mi-2016, date de l'estimation initiale, la plupart des modules envisagés (recherche, cartographie, …) n'était pas portés ou étaient encore instables en Drupal 8. De plus, au vu de la taille et de la criticité du projet, nous ne pouvions pas nous permettre de prendre un risque en misant sur la stabilisation des modules à temps pour le projet.
Nous reviendrons dans l'article sur les points où faire le choix inverse aurait pu éventuellement nous faire gagner du temps.
Multilinguisme
Comme tout site public belge, ce site comportait un multilinguisme complet (entendre : traduction intégrale de l'ensemble du contenu et des composants (menus, taxonomies, views, …) liés.
Nous avons choisi d'utiliser sur ce site Entity Translation (module de la communauté en Drupal 7, intégré plus ou moins directement au cœur en Drupal 8), qui nous permettait de gérer plus de choses que son alternative issue du cœur Drupal 7 Content Translation, et dont on soupçonnait que son utilisation faciliterait la migration éventuelle vers Drupal 8.
Nous nous sommes heurtés à plusieurs problématiques spécifiques liées à la combinaison de modules Entity Translation et Internationalization en Drupal 7.
Migration des contenus multilingues en traduction
La migration de contenus multilingues en traduction du module Entity Translation demande l'ajout de code spécifique. En effet, les champs traduisibles doivent recevoir en une fois les données dans toutes les langues. On doit donc d'abord préparer les données en aggrégeant les différentes langues :
public function prepareRow($row) {
$row->languages = array('fr', 'nl');
$row->title = array($row->title_fr, $row->title_en);
$row->body = array($row->body_fr, $row->body_nl);
return TRUE;
}
On peut ensuite, dans notre mapping, utiliser ces valeurs pour renseigner les champs en spécifiant les différentes langues :
$this->addFieldMapping('title_field', 'title');
$this->addFieldMapping('title_field:language', 'languages);
$this->addFieldMapping('body', 'body');
$this->addFieldMapping('body:language', 'languages);
Sans oublier de renseigner la langue par défaut des contenus :
$this->addFieldMapping('language')->defaultValue('fr');
Ergonomie différente
D'un point de vue utilisateur du back-office Drupal, l'usage parallèle de 2 méthodes d'internationalisation différentes est perturbant car les traductions ne fonctionnent pas de la même façon d'une section à l'autre du site.
Par exemple : les entrées de menu, les taxonomies (les entités en général) et les chaînes de l'interface fonctionnent de façon différente. De plus, la langue pivot est parfois nécessairement l'anglais, parfois elle est la langue source de création d'un contenu. Tout ceci peut perdre un peu les utilisateurs amenés à intervenir côté back-office.
Site building "classique"
Gestion des menus
Comme dans beaucoup de sites de taille importante, nous avons quelques spécificités dans le menu de navigation principal comme la section "Se déplacer" qui contient une arborescence profonde alors que le reste du site n'a qu'un seul niveau.
Nous avons donc créé des blocs Drupal permettant d'afficher de manière contextuelle :
- les éléments de menu de niveau 2 (en haut) et les niveau 3 et 4 (à gauche, barre latérale)
- les niveaux 2, 3 et 4 dans un seul bloc en mode mobile

Ceci est typiquement fait nativement avec Drupal 8 là où il faut installer un module "menu block" avec Drupal 7.
Les icônes de certains menus sont gérés par le module Menu Attributes (l'équivalent Drupal 8 est le module "Link Attributes widget").
Gestion des liens internes
Une des demandes pourtant classiques d'un CMS et mal couverte en standard est la possibilité de faire du maillage interne dans le WYSIWYG, en faisant des liens vers d'autres contenus du CMS sans coder en dur leur alias qui peut potentiellement changer.
Ici nous avons utilisé le module cKEditor Link car LinkIt (solution classique du monde Drupal) posait des problèmes avec Entity Translation.
Services web
Le site web consomme de façon périodique une vingtaine de services web issus de fournisseurs différents. Une partie significative du projet a donc consisté à consommer, traiter et afficher les données de ces services.
Résilience
Un des soucis du site précédent était la non-fiabilité de ces services (qui peuvent cesser de répondre ou renvoyer des réponses invalides de façon impromptue). La manipulation de ces données avait tendance à faire planter le précédent portail et nous avions eu des exigences importantes de robustesse de la part du client.
Les données valides des services web sont donc désormais mises en cache et ce sont ces données qui sont renvoyées lorsque les services webs distants dysfonctionnent. Ceci nous permet de continuer à servir des données potentiellement un peu plus anciennes mais toujours valides pour présentation dans la carte. Noter que ceci ne s'applique qu'aux données statiques qu'on peut importer régulièrement (emplacement des stations de train, bus etc). Les données dynamiques comme les horaires continuent nécessairement d'être interrogées en temps réels. Comme il n'y a pas de nouvelles stations tous les jours, une défaillance temporaire d'un import ne se verra pas. Pour les données en temps réel en revanche, nous sommes dépendant de la bonne réponse des service externes.
Nettoyage et uniformisation
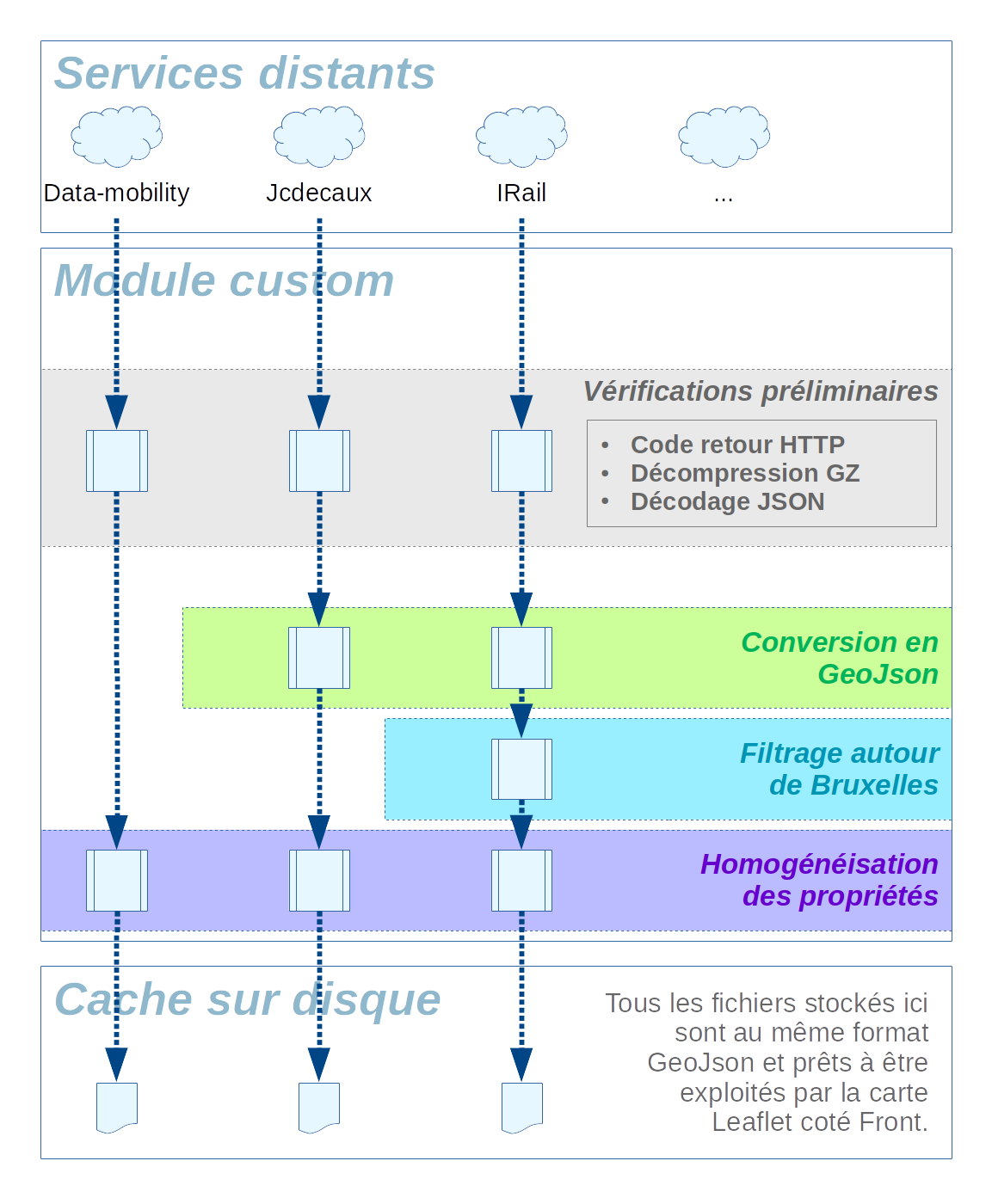
Les services sont tous des services webs REST répondant en JSON, mais les données issues de ces services sont dans des formats différents (pas les mêmes noms de champs partout, parfois JSON simple, parfois GeoJSON). Or nous devions les afficher de façon cohérente sur la même carte résultante.
Chaque "fichier" de données issu d'un service web passe par une suite de traitements destinés à :
- Filtrer les données : en effet, nous n'affichons au final des données que sur la région Bruxelloises, tandis que nous recevons parfois des services web des données sur l'ensemble de la Belgique ; pour des raisons tant ergonomiques que liées à la performance, nous ne pouvons pas tout afficher sur la carte ; nous nettoyons alors la source de données en entrée pour supprimer les données inutiles et produire des données optimisées en sortie.
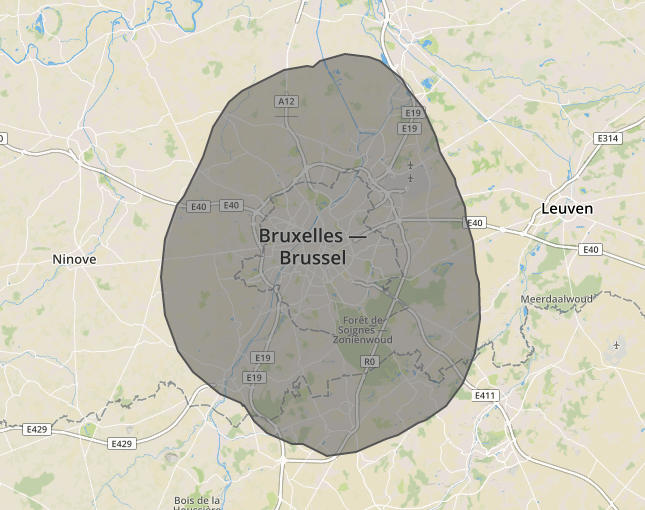
Le filtrage des points intra-bruxellois n'ayant pas besoin d'être d'une précision absolue et reposant sur un polygone simple (le contour simplifié de la ville de Bruxelles étendu de 10km supplémentaires) mais nécessitant de bonnes performance pour traiter les dizaines de milliers de points en un temps restreint, nous avons utilisé l'algorithme dit de "Ray casting" (voir cet article pour plus d'informations).
Voici le polygone qui a été utilisé pour filtrer les points sur la région de Bruxelles et alentours, en ne gardant que les informations géographiques incluses dans ce polygone :
- Uniformiser les données : les données devant être affichées de façon identique par la couche de front-end, nous devions les retravailler côté back-end afin de fournir des données cohérentes de façon la plus performante possible. Nous avons donc choisi de les retravailler avant de les stocker en cache puis de les servir au Javascript qui ne réalise donc jamais de traitement "superflu" : cela rend le code plus générique et maintenable. Les noms des champs non similaires sont uniformisés, des champs composites sont éventuellement calculés…
Chaîne de traitement complète
Voici une représentation schématique de l'ordonnancement des vérifications et traitements réalisés sur ces services web :
Cartographie
Nous affichons le résultat des traitements décrits dans la partie précédente sous la forme d'une carte, chaque service web étant affiché sur une couche différente activable ou désactivable à volonté sur la carte. Noter qu'en raison du grand nombre de sources, il était difficile de conserver le sélecteur de base de Leaflet, et nous sommes partis sur une version modifiée de github.com/davicustodio/Leaflet.StyledLayerControl qui est disponible ici github.com/makinacorpus/Leaflet.StyledLayerControl.
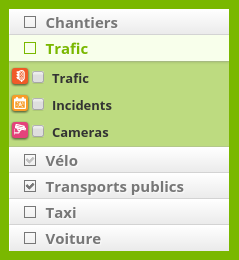
Nos modifications sont essentiellement des modifications de style et d'ergonomie :
- Ajout d'une case à cocher pour chaque "groupe" permettant de tout sélectionner ou déselectionner ;
- Ajout de la possibilité d'insérer des icônes devant les couches cartographiques ;
- Modification des noms des couches pour les transformer en véritable <LABEL> permettant de cliquer sur le nom comme sur la case à cocher.
Illustration :
Certaines couches comportent un nombre très conséquent de points, qui rendait la carte très peu performante à certains niveaux de zoom ou la position des points n'était pas fondamentale puisque trop peu précise à ce niveau de zoom.
Pour chaque service web, il a donc été décidé d'un affichage spécifique selon la volumétrie des données :
- Lorsqu'il y a peu de données et que les points sont assez espacés, nous conservons un affichage à base d'icône :
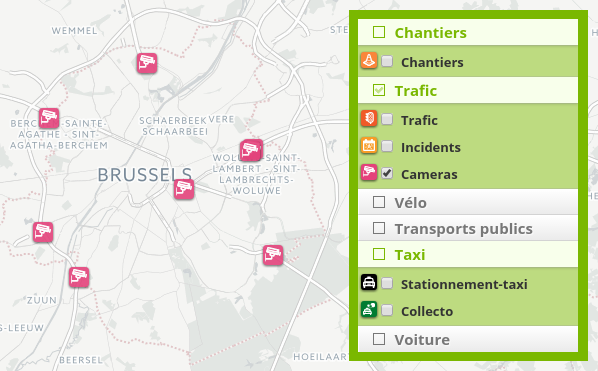
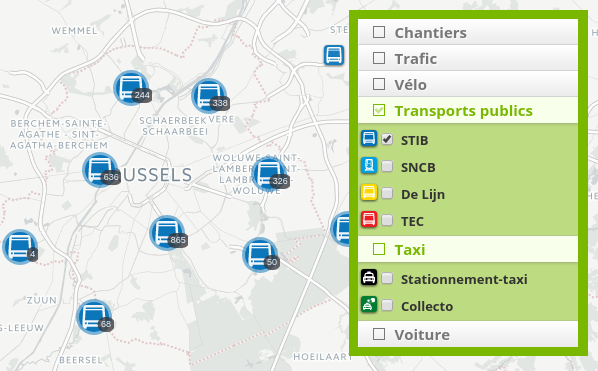
- Pour les couches à forte volumétrie, avec de nombreux points très proches (c'est le cas des bornes taxi dans le centre de Bruxelles), nous n'affichons pas les pictogrammes et les remplaçons par de simples points ce qui notre fait gagner en lisibilité et en performance ; lorsqu'on zoom, on retrouve l'affichage classique à base d'icône :
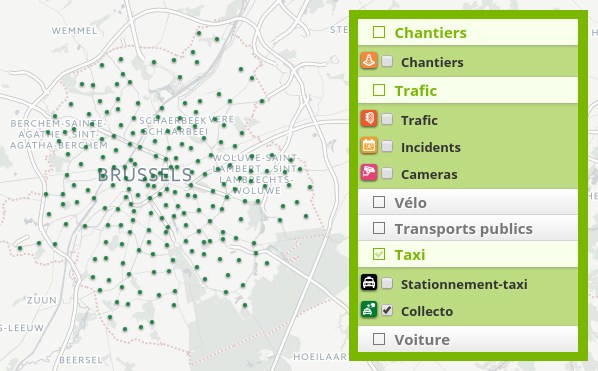
- Pour les couches avec la plus grosse volumétrie, des stratégies de clustering sont utilisées dans les niveaux de zoom les plus haut où, de toutes façons, il n'est pas possible de distinguer de façon précise l'emplacement du point sans zoomer ; mais ceci est plus ergonomique que la version précédente du portail qui ne montrait aucune données au delà d'un certain niveau de zoom, ce qui laissait pensait que l'activation de la source ne fonctionnait pas :
Toutes ces stratégies permettent d'obtenir une carte fluide bien que de très nombreuses données soient affichées. Vous pouvez consulter le résultat final ici.
Performances et cache
Runtime PHP
Nous avons l'habitude de privilégier les versions les plus récentes de tous les composants que nous utilisons. C'est particulièrement intéressant avec PHP dont la version 7 fait l'objet de nombreuses améliorations en terme de vitesse et de consommation mémoire.
Malheureusement, les prérequis de l'hébergeur nous imposaient de rester sur plateforme RedHat/CentOS qui continue de venir de base avec une version ancienne (PHP 5.3.x). L'usage des Software Collections, extension RedHat permettant de bénéficier de composants plus récents que ceux fournis avec la distribution de base, s'est révélée être un mauvais choix car mal maintenus. Nous avons donc dû utiliser d'autres sources de paquets.
Autres points
Nous avons déjà traité un peu de la performance du front-end dans le paragraphe précédent.
Mais l'objectif, au vu de la volumétrie du site, était également d'utiliser le plus possible à la fois les caches de Drupal, mais également les possibilités de Varnish, reverse-proxy utilisé en frontal.
Optimisations de l'utilisation du cache
Pour optimiser au maximum l'utilisation du cache (et notamment du cache des blocs), nous avons parfois simplifié l'interface. Par exemple, le lien "Mon compte" est identique pour les utilisateurs anonymes et authentifiés.
ElasticSearch et Redis
Nous utilisons une base de données PostgreSQl très performante. Mais pourtant nous associons à cette base deux autres outils. Un cluster ElasticSearch pour la recherche et l'indexation. Un cluster Redis pour la gestion des caches et des sessions. Ces services sont optimisés, par nature, pour ces tâches. Redis par exemple est très rapide à la fois en écriture et en lecture, mais, surtout dans la configuration que nous avons établi, ne garantit que très peu la durabilité des données. Ce type de faiblesse est en fait un atout pour des caches, à l'inverse une base de données transactionnelle est excellente pour garantir la durabilité des données, mais lente sur les opérations en écriture, un PostgreSQL ou un MySQL seront donc toujours pénalisés par la gestion des tables de cache. Pousser ces éléments dans des services dédiées permet de mieux garantir la montée en charge.
Configuration Varnish
Au niveau du Varnish nous avons opté pour une configuration 'brutale', qui privilégie le mode anonyme, quitte à supprimer les cookies de sessions sur l'immense majorité des pages. Les quelques pages (ou sous pages) authentifiées du site sont exclues du cache, mais pour l'essentiel les autres pages sont toutes stockées en cache, et pour cela Varnish est configuré pour faire abstraction des éventuelles informations de session.
La configuration Varnish est aussi prévue pour prendre le relais des backends Nginx/PHP si jamais ceux-ci sont tombés ou sont en maintenance (mise à jour).
Nous avons publié un dossier technique complet traitant spécifiquement de la configuration Varnish, avec des détails et des exemple associés (voir contenus corrélés ci-dessous).
Conclusion
Au final, l'usage du CMS Drupal sur ce projet s'est révélé être un bon choix. Nous avons pu mixer un usage de contenus éditoriaux "classiques" pour structurer certaines zones du site. Et ajouter à cela des morceaux de code plus spécifiques basés sur l'API Drupal ("Drupal as a framework") pour la gestion des sources de données externes, ce qu'il aurait été plus difficile de faire avec un CMS moins extensible. Un autre choix d'architecture aurait été d'avoir un sous projet basé sur un framework type Symfony, mais en l'occurrence on aurait perdu la facilité de stockage des données via l'API des nodes.

Drupal - SEO
Formations associées
Formations Drupal
Formation Drupal Administrateur
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation Drupal AdministrateurFormations Drupal
Formation Drupal Développeur
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation Drupal DéveloppeurActualités en lien
Drupal SEO Recipe
Drupal
14/01/2025

Migration d'un site Drupal 7 en Drupal 11
Migration Drupal
04/04/2024

Web mapping avec Drupal et Leaflet
Drupal
11/05/2015
L'intégration de @LeafletJS avec #drupal est vraiment très rapide à mettre en œuvre.