Makina Blog
Varnish et Drupal : gérer un cache anonyme étendu
Le rôle d'un Reverse Proxy Cache Varnish dans une architecture Web (type Drupal).
Nous montrerons un exemple concret d'implémentation de cache, pour un site Drupal gérant une majorité de pages anonymes, mais avec quelques parties connectées, dont un back office.
Ces parties connectées, dans lesquelles les utilisateurs peuvent obtenir des informations propres à leur profil, sont par nature problématiques pour un Reverse Proxy Cache. Le cas idéal pour ce type de composant étant un site quasi uniquement anonyme (comme un site de presse par exemple). Il existe des solutions assez complexes pour gérer des blocs connectés (comme l'ESI) mais les solutions présentées dans cet article sont plus simples, il s'agit plutôt de gérer la présence de quelques pages connectées. Ces quelques pages dépendant d'une session utilisateur pourraient réduire à néant votre politique de cache, car elles imposent la présence de cookies de session utilisateur. Nous allons donc détailler un peu plus les problèmes et les solutions.
Varnish : Un Reverse Proxy Cache, mais quoi qu'est-ce ?
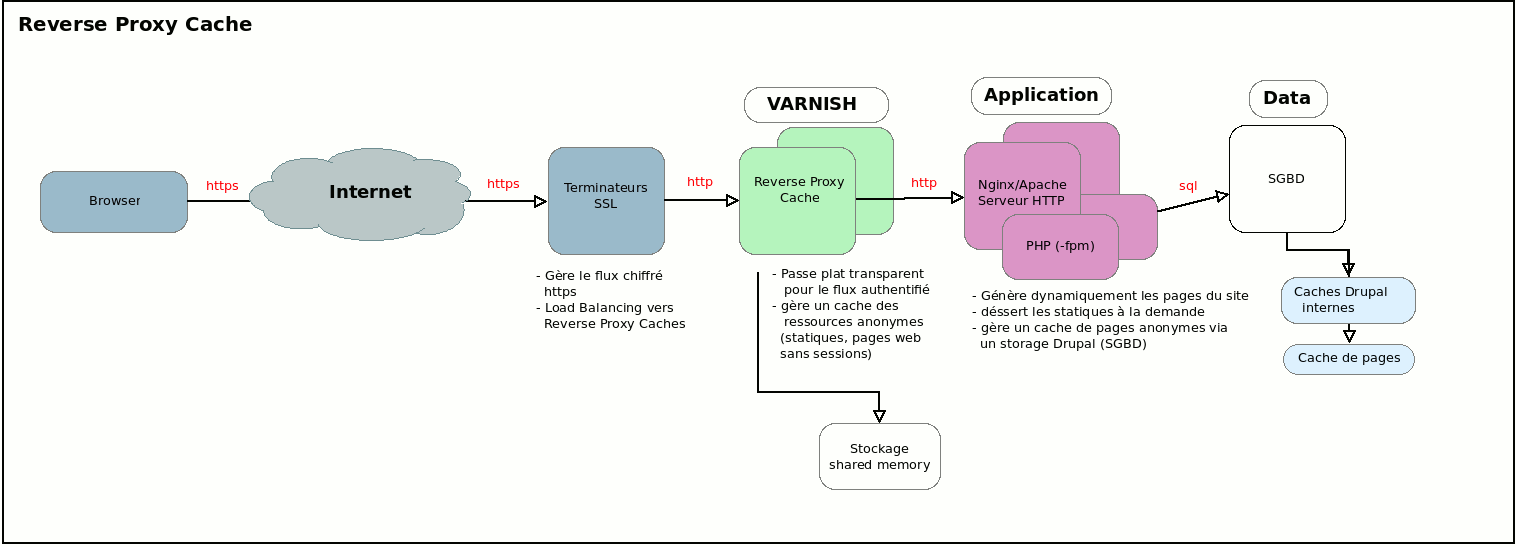
Quand on a un tout petit site Drupal, on le fait tourner avec un nombre de composants limité :
- une base de données (SGBD) ;
- un serveur web (serveur HTTP, Nginx ou Apache) ;
- un serveur PHP (php-fpm, ou bien mod_php dans apache).
Mais quand le trafic grossit on ajoute quelques éléments dans la chaîne :
- des serveurs de caches internes (type memcache, Redis), qui peuvent aussi gérer le stockage de sessions ;
- des serveurs d'indexation (comme Elasticsearch) ;
- on multiplie les serveurs d'application (la partie PHP) ;
- on ajoute de la RAM sur le serveur SGBD ;
- et, donc, aussi, on ajoute des Reverse Proxy Caches, devant les serveurs web/PHP.
On connaît souvent le terme proxy, un service qui sert de pont d'accès à Internet utilisé par un navigateur web (forward proxy). Le reverse proxy lui n'est pas du tout géré par les navigateurs web. Un reverse proxy vient se placer entre le navigateur et le vrai serveur du site, il utilise son nom (DNS), il répond à la place du "vrai" site, tout en étant situé juste à côté. Au sens physique le reverse proxy est très souvent hébergé sur le même réseau local que le serveur applicatif, il lui est dédié.
Sa première tâche est de faire de la répartition de charge (load balancer). Si, comme je le disais plus haut, on multiplie le nombre de serveurs applicatifs PHP générant les pages du site, on évite le plus souvent de multiplier les DNS servant le site (du genre au lieu de taper www1.drupal.org, www2.drupal.org et www3.drupal.org on veut juste taper www.drupal.org et la machine qui répond à cet endroit s'arrange pour répartir la charge sur les 3 autres).
La deuxième tâche est de gérer un cache, les pages générées par les serveurs applicatifs sont potentiellement coûteuses en CPU et en temps de génération, le reverse proxy cache va donc garder un cache de ces pages et essayer de s'en servir pour absorber une grande partie du trafic (on peut viser des scores à plus de 99% de trafic absorbé si le site ne contient que des pages anonymes).
Une autre charge pourrait être de gérer le rôle de terminateur SSL/TLS, permettant de gérer toute la couche SSL/TLS qui fait la différence entre https et http.
Ceci pour absorber en un point unique cette gestion du chiffrement de la communication, qui n'est pas neutre en terme de CPU, et qui demande un stockage de session SSL (qui n'a rien à voir avec la session applicative, ou une session à base de cookie, on est au niveau protocolaire, mais il y a des éléments de gestion de session qui existent et qui peuvent coûter cher si à chaque requête il faut ré-initier une session).
L'autre avantage d'un système de terminateurs SSL est de permettre une communication HTTP (sans S) à l'intérieur de l'architecture, qui par nature est plus simple et plus rapide.
En l’occurrence Varnish ne gère pas le https. La présence d'un terminateur SSL devant Varnish est donc obligatoire, le trafic doit déjà être downgradé en http avant d'arriver sur Varnish.
La plupart des hébergeurs disposent de clusters de terminateurs SSL performants, ou vous pouvez monter le votre avec des outils récents, open source, et bien maintenus comme HaProxy (notez que je n'ai pas dit pound…).
Dans l'idée vous avez un système redondant de terminateurs SSL, qui font du load balancing vers au moins deux services Varnish. Ces services Varnish font eux-même du load balancing vers l'ensemble des serveurs applicatifs. Et les serveurs applicatifs communiquent tous avec le même SGBD (ou système Master/Slave de SGBD).
Ici, il existe plusieurs configurations en terme de load balancing. Certains utilisent du load balancing avec une gestion de persistance du chemin. Si un navigateur A commence à discuter avec un Varnish A et un serveur applicatif A, des éléments de session (cookies, headers http) sont mis en place pour que dans les prochaines minutes la communication ne se fasse pas avec des serveurs B. On dit parfois qu'il y a une gestion de persistance au niveau L7, en terme de niveau dans la couche théorique TCP/IP.
Dans l'idéal, il faut éviter ces solutions, et faire un load balancing aveugle, à chaque nouvelle requête j'envoie vers le Varnish A ou le Varnish B, qui envoient eux-même vers des serveurs applicatifs A, B ou C, sans se soucier du passé. Car un tel système résiste mieux aux pannes. Mais pour que cela fonctionne vous devrez avoir bien prévu votre système de serveurs applicatifs, pour que les gestions de fichiers temporaires ou de fichiers uploadés soient bien gérées sur des systèmes de fichiers partagés entre les serveurs applicatifs, par exemple. Mais ceci nous emmène un peu loin de Varnish.
Ok, donc un Cache, comme le cache de page Drupal?
Pas exactement.
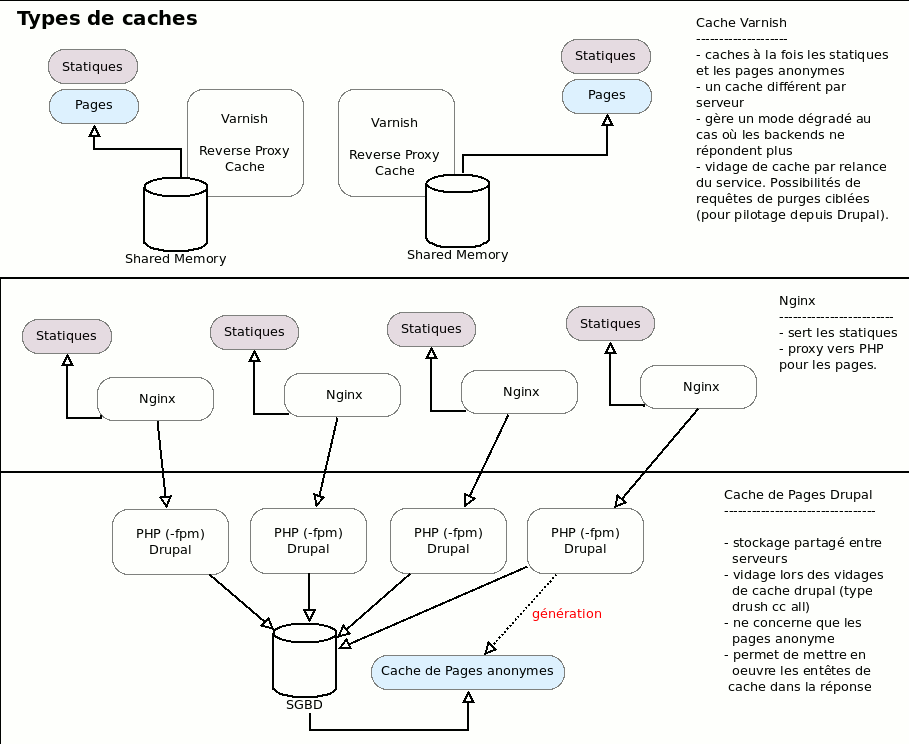
Le cache de pages de Drupal, si il est activé, stocke en base de données une copie des pages anonymes. Notez que le cache de page Drupal est requis. Sans lui les pages générées par Drupal présenteront des headers HTTP qui interdisent à ces pages le stockage en cache.
Pensez à activer le cache côté drupal. Pour les entêtes de cache, mais pas uniquement. Quand le page de cache est actif d'autres problèmes plus complexes sont pris en compte et gérés par Drupal, comme la gestion des identifiants de formulaire, le mode 'immutable' des formulaires anonymes, avec re-génération de clef de cache du formulaire à la volée pour les caches multi-steps. Bref, il est préférable que Drupal sache qu'un mode "anonyme + cache" existe.
Ce cache de page :
- peut être vidé facilement depuis Drupal (il l'est régulièrement d'ailleurs, souvent par les crons système Drupal)
- ne gère que des pages html (et pas les statiques du sites, images, js, css)
- est partagé entre toutes les instances des serveurs PHP du site (si vous mettez 15 serveurs d'application, ils partagent tous la même base SQL)
Les statiques du site sont eux-gérés par Nginx ou Apache, le serveur HTTP.
Notez que pour Nginx comme pour Apache il est possible de transformer ces serveurs HTTP en serveur Reverse Proxy Cache. Mais ces serveurs possèdent un nombre beaucoup plus limité d'options que des services dédiés comme Varnish. Vous le verrez avec les exemples de vcl en fin d'article. Bref, si jamais vous avez besoin de Reverse Proxy Caches mais que vous ne pouvez pas installer de briques de service supplémentaires retenez qu'il est possible de gérer cette tâche dans Nginx ou Apache, ainsi que la tâche de terminateur SSL.
Enfin les serveurs Varnish, devant les autres, cachent à la fois les statiques et les pages anonymes. Ils sont aussi capables de laisser transiter de façon transparente les requêtes authentifiées, qui ont besoin de pages non anonymes.
Pour ce cache Varnish :
- chaque instance possède son propre cache, géré par de la mémoire partagée -- shared memory -- (partagée avec l'OS, pas partagée avec d'autres instances)
- le cache contient des statiques et des pages
- le cache peut être utilisé en lieu et place du site quand le site est tombé (pour un temps réglable)
- il n'est pas, a priori, possible de contrôler le vidage complet du cache depuis Drupal. Certains modules proposent des solutions, que je ne conseille pas -- déjà parce que pour la plupart ils ont tendance à essayer de vider l'ensemble des caches de l'ensemble des instances de reverse proxy cache situées devant le site, beaucoup trop souvent, ce qui réduit fortement l'intérêt --. Par défaut on vide plutôt le cache en relançant le service. On peut aussi faire des requêtes de purges, ciblées ou générales, depuis les serveurs applicatifs, mais comme je le disais, il vaut mieux y réfléchir posément avant de se lancer dans ce type de fonctions.
Les deux caches sont donc assez différents, mais il y a de fortes chances qu'au tout début une page soit générée puis stockée à la fois dans le cache de page Drupal et dans le cache Varnish.
Mais ils vont être très liés, sauf à écrire une configuration très particulière pour Varnish, celui-ci utilisera les réglages que vous aurez défini dans le cache de pages pour la durée de rétention des pages (TTL ou Time To Live), ou pour différencier les pages qu'il accepte en cache des autres (en gros Cache-Control: public max-age=3000 => oui; Cache-Control: private => non).
Rentrons dans le vif du sujet, le cache
Cacher des pages devant un site est un métier plus complexe qu'il n'y paraît d'un premier abord. Mais commençons simplement avec un algorithme très simplifié du métier de cache web:
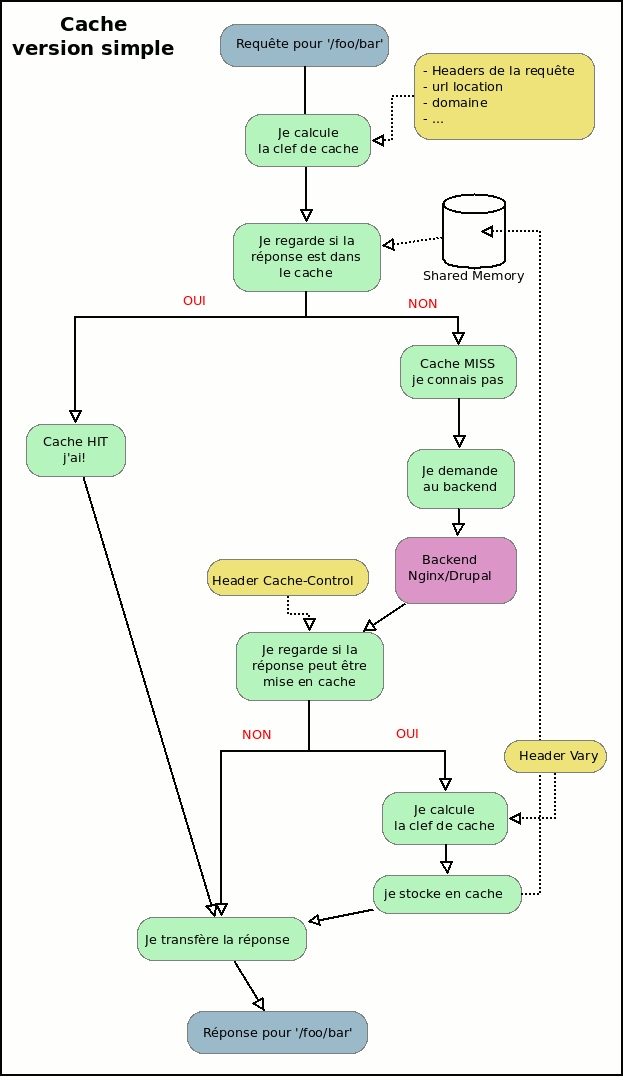
Globalement pour chaque requête qui arrive on va calculer une clef de cache. Celle-ci se base sur l'url demandée, le nom de domaine demandé, et possiblement quelques autres éléments (pour l'instant on reste simple).
Si on retrouve ces éléments dans le cache, on a un HIT, on charge le résultat.
Si nous ne les avons pas, il faut les demander au backend, dans le cas présent un serveur applicatif Drupal, de nous fournir ces éléments (qu'il s'agisse d'une ressource css, js, ou d'une page html).
On examine la réponse pour voir si elle mérite d'être stockée en cache et on la sert au navigateur client.
Un des points importants ici est que certaines réponses ne doivent pas être stockées en cache. Si le serveur d'application nous renvoie des headers HTTP dans la réponse indiquant qu'il s'agit d'une page non anonyme il ne faudrait pas qu'on stocke cette page dans la cache. Et ce principe peut s'étendre aussi aux requêtes, certaines requêtes ne devraient même pas être recherchées dans le cache. Et je vous donne un exemple simple, une requête avec une méthode POST est par définition une requête qui va modifier le système d'information. Par défaut une requête qui utilise de l'authentification HTTP ne serait pas non plus gérée par la partie cache, etc.
On peut donc imaginer que l'algorithme est un peu plus complexe.
On agrémente donc un peu ce premier schéma pour obtenir quelque chose qui est déjà plus proche de ce qu'on trouve habituellement dans une configuration Varnish :
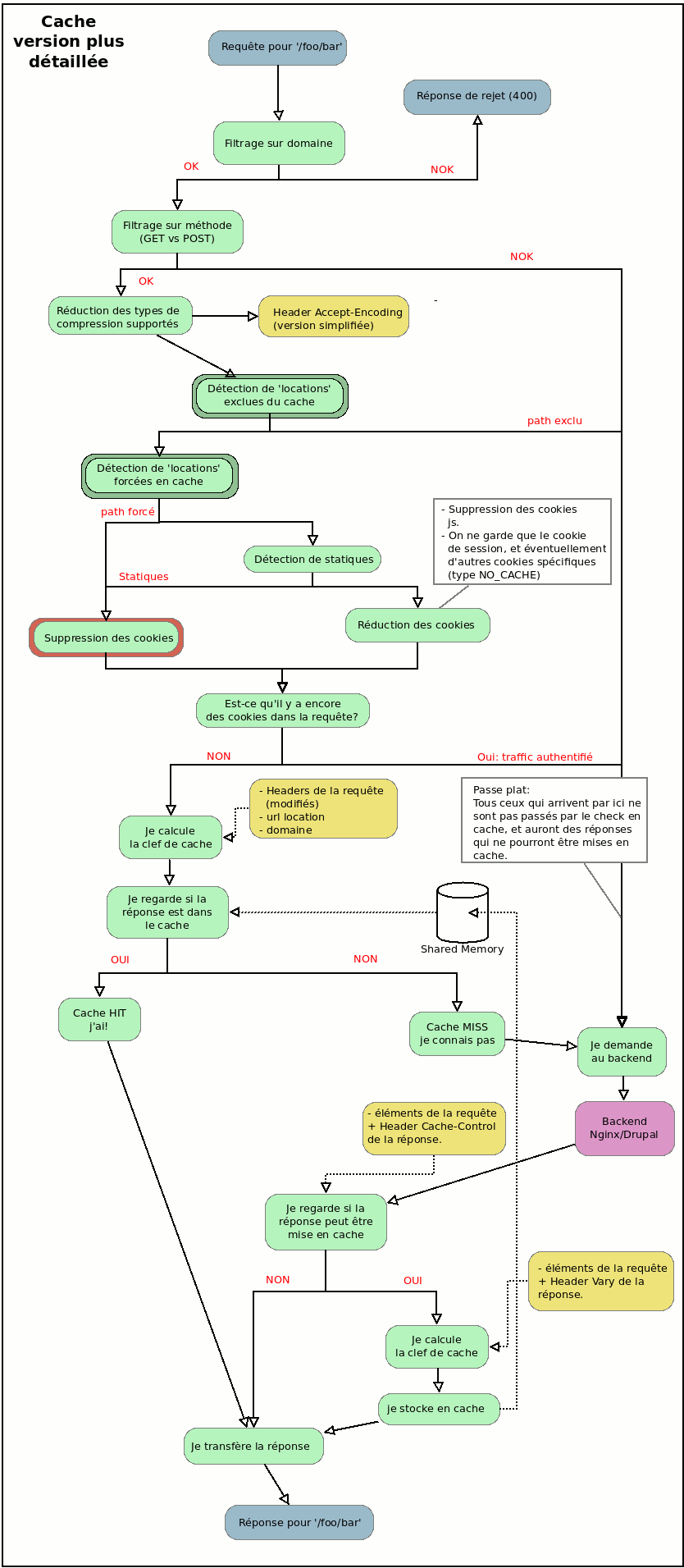
C'est à peu près le même algorithme, plus détaillé sur certains points à la fin, mais avec surtout des éléments de filtrage et de simplification/factorisation au départ.
Les points les plus importants sont :
- on identifie le trafic anonyme comme étant un trafic qui ne nécessite pas de cookies
- on va détruire les cookies présents dans les requêtes partout où il est possible de le faire
- on va essayer de ne garder qu'un nombre réduit de cookies, et uniquement sur des zones identifiées du site
- on va simplifier au niveau des requêtes les types de compressions supportés, pour ne pas stocker trop de versions d'une même page
Gardez l'image de côté (cliquez dessus), vous pourrez revenir dessus lors de l'examen du vcl (la configuration réelle). Mais juste avant de regarder ce vcl, je vais détailler les problèmes posés par les cookies et les types d'encoding, pour ceux qui ne les connaissent pas.
Pourquoi détruire des cookies
Au départ le premier problème du serveur de cache c'est de différencier le trafic anonyme du trafic connecté, puisque par définition il ne faut pas stocker en cache et servir à tout le monde des pages contenant des données propres à un utilisateur. Cette distinction va se baser sur la présence ou non de cookies. Si on pousse la réflexion un peu plus loin on peut se dire que c'est le cookie de session qui est normalement le point d'achoppement, s'il est présent c'est qu'on est sur une session utilisateur. Mais on pourrait avoir d'autres cookies fonctionnels en dehors du cookie de session, et on verra que le travail différencié et fin sur les cookies n'est pas chose facile.
Le plus simple est donc d'établir une règle simple et habituelle dans de nombreuses configurations :
il y a des cookies => pas anonyme => je ne cache pas
il n'y a pas de cookies => anonyme => je cache
C'est une règle qui marche bien, mais si vous l'appliquez sans traitements préalables vous obtenez un serveur de cache qui ne cache jamais rien.
Pourquoi ? Parce que toutes les applications modernes génèrent un grand nombre de cookies :
- des cookies js liés au tracking (type google analytics)
- des cookies js fonctionnels (le no_js de Drupal, un cookie "oui j'accepte les cookies", etc)
- des cookies ajoutés par des load balancer qui font du l7
- …
Et, pire encore, vous pourriez n'avoir qu'une seule page nécessitant une session utilisateur, comme par exemple un formulaire de jeu, ou un formulaire de contact, ou autre chose, sur cette page votre utilisateur passerait d'un statut anonyme à un statut identifié (ou pseudo-identifié, du genre un anonyme que l'on suit sur plusieurs étapes, avec une session anonyme). Pour cela un cookie de session serait généré. Il y a de très très grandes chances que ce cookie envoyé à l'utilisateur ****ne contienne pas de restriction de path**. Et donc par la suite, pour toute la durée de vie du cookie dans le navigateur client, celui-ci continue d'envoyer les cookies pour l'ensemble des pages du site. Votre utilisateur n'est plus anonyme, y compris lorsqu'il visite des ressources qu'on pourrait partager avec les anonymes.
Pour régler ce problème il va falloir que le Reverse Proxy Cache détruise les cookies quand il identifie les ressources anonymes. Les serveurs applicatifs ne recevront plus tous ces cookies.
Pensez à coder les fonctionnalités reposant sur des cookies js uniquement avec des technologies front. La présence d'un bandeau j'ai lu et j'accepte votre politique de cookies, si elle repose sur la présence d'un cookie js, ne doit se gérer que du côté front, car le serveur applicatif (Drupal) ne recevra jamais ce cookie js.
Le fait de supprimer les cookies va aussi permettre d'éviter des problèmes de sécurité en évitant les effets de bord des attaques Web Cache Deception.
Pour faire simple ce type d'attaque consiste à demander à un utilisateur connecté (par exemple l'admin), de cliquer sur un lien. Ce lien contient une url vers une page avec des informations secrètes (du genre admin/reports/status/php), mais l'url est un peu trafiquée à la fin pour que le reverse proxy cache pense qu'il s'agisse d'un statique (donc sans risque en terme de cache), du genre admin/reports/status/php/foo.css. Je donne cet exemple, je ne suis pas du tout certain que le routeur de Drupal se fasse avoir sur cette url, mais je suis certain qu'il existe des urls dans le routeur où une url dont la fin ressemble à un statique pourrait en fait faire fuire de l'information. Mais si j'ai détruit tous les cookies des requêtes que je veux mettre en cache, Drupal ne recevra pas de requête connectée, et donc ne m'affichera aucune info utile dans l'url utilisée lors de l'attaque. l'attaquant risque fort de n'avoir qu'une 403 à la place, ou bien une page anonyme.
Quand on dit à notre Reverse Proxy Cache :
"Sur ce type de chemins, c'est toujours du trafic anonyme, tu peux cacher sans risques."**
Il faut en fait lui dire :
"Sur ce type de chemins, c'est toujours du trafic anonyme, détruit tous les cookies dans la requête, si il y en a c'est par erreur ou par malveillance, on peut les virer, tu peux cacher sans risques, vas-y mec, je te dis c'est sans risques. Pas de cookies, pas de chocolat.".
On voit donc que la règle simple du début est très bien, pas de cookies, je cache. Et si je veux forcer quelque chose dans le cache, je vire les cookies, et comme ça je suis certain que j'ai pas de problèmes.
Pourquoi simplifier les types d'encoding (et des choses sur Vary)
Ici le problème se situe à la sauvegarde de la réponse dans le cache, mais se règle sur les requêtes.
Quand le Reverse Proxy Cache reçoit une réponse du backend, il examine certains des headers de la réponse, comme par exemple le header Vary. C'est un header très important qui indique la liste des headers qui ont un impact sur le format de la réponse.
Vary: Cookie par exemple signifie que le contenu du body de la réponse sera différent suivant que la requête contenait des cookies ou pas (vous l'avez par défaut sur Drupal sauf si vous avez mis le settings omit_vary_ccokie à True).
Si vous avez Vary: User-agent c'est mauvais, cela veut dire que le contenu du body est possiblement différent en fonction de la valeur du User-Agent de la requête, et donc cela signifie que le Reverse Proxy Cache devrait stocker un contenu différent en fonction du header User-Agent de la requête. Ce qui revient à ajouter la valeur de 'User-Agent' dans la clef de cache (et à faire exploser la taille du cache, ou mathématiquement équivalent, à ne stocker que très peu de pages dans votre cache à taille fixe, donc réduire votre taux de Hit). Là il vaut mieux éviter d'avoir cette valeur dans le vary, ou bien écrire des règles de simplification assez importantes sur les valeurs de ce header dans Varnish.
Et vous aurez aussi très souvent Vary: Accept-Encoding, qui signifie que le body est sans doute compressé, mais que le choix de l'algo de compression (ou de non compression) s'est fait sur la base du header Accept-Encoding de la requête. Hors celui-ci peut prendre un grand nombre de valeurs:
Accept-Encoding: none
Accept-Encoding: gzip, deflate
Accept-Encoding: gzip,deflate
Accept-Encoding: deflate, gzip
Accept-Encoding: deflate,gzip
Accept-Encoding: ...
Comme pour le User-Agent (en moins grave) vous aurez une explosion de combinaisons possibles dans votre clef de cache. Il est donc préférable de passer la valeur de ce header dans un filtre, au niveau de la requête, pour par exemple n'avoir que deux valeurs possibles :
Accept-Encoding: none
Accept-Encoding: gzip
Ce qui multiplie par deux, et uniquement par deux, le nombre de versions de la même page que le cache pourrait stocker. En même temps, les comportements de Varnish ont pas mal bougé en 4.0 et 4.1 autour du support de la compression, avec décompression à la volée de contenus de cache compressés pour les clients qui ne comprennent pas le cache, et simplification automatique du Accept-Encoding. Donc sur ces éléments on refait peut-être un travail que Varnish fait automatiquement. Je laisse aux courageux le soin de tester le comportement de Varnish (taille du cache et type de compression de la réponse) pour chaque valeur de Accept-Encoding lorsque les parties du vcl gérant cette simplification du Accept-Encoding sont retirées.
Le vcl pas à pas
Varnish se configure avec un fichier vcl, qui est compilé à la volée au démarrage du service (d'où une dépendance à gcc).
Pour trouver le vcl utilisé le mieux c'est une petite commande ps:
ps auxfwww|grep varnish
D'où vous pourrez voir, si Varnish tourne déjà, quel est le vcl utilisé. Je n'aborde pas dans cet article les réglages de Varnish, qui se trouvent parfois dans /etc/default/varnish, parfois dans la conf systemd, tout dépend de la distribution et de la version (et la présence d'un fichier n'implique pas qu'il est utilisé, la période de transition vers systemd sur ce package est pour le moins trouble et agitée). Mais vous devez savoir que des éléments de configuration importants comme le réglage de la taille de votre cache et son type (par exemple un fichier de shared memory de 3 ou 4Go) ainsi que le fichier vcl utilisé, ou le port d'écoute, se règlent dans les paramètres de démarrage du service Varnish. Je laisse tout cela de côté -- c'est déjà un peu long--, on passe directement au vcl.
Ce vcl contient plusieurs fonctions implicites qu'il n'est pas nécessaire de recoder, la pratique est de n'écrire dans son fichier vcl que les fonctions que l'on modifie.
Premier problème, il faut donc retrouver ce vcl par défaut, qui dépend très fortement de votre version de Varnish.
- https://www.varnish-software.com/wiki/content/tutorials/varnish/builtin_vcl.html
- https://github.com/varnishcache/varnish-cache/blob/master/bin/varnishd/builtin.vcl
- https://github.com/varnishcache/varnish-cache/blob/4.0/bin/varnishd/builtin.vcl
- https://github.com/varnishcache/varnish-cache/blob/4.1/bin/varnishd/builtin.vcl
- https://github.com/varnishcache/varnish-cache/blob/5.0/bin/varnishd/builtin.vcl
- https://github.com/varnishcache/varnish-cache/blob/5.1/bin/varnishd/builtin.vcl
- etc.
On remarque la présence de différents points d'entrée, vcl_fetch, vcl_recv, vcl_pipe, etc. Chacun se situe à un endroit précis de la chaîne.
Vous avez un joli schéma sur cette documentation par exemple.

Une des étapes de cet automate est très importante, le vcl_recv, qui va concerner le traitement de la requête entrante. Je citerai aussi le vcl_hash qui sert à calculer la clef de cache. enfin il est important de noter qu'il faut éviter à tout prix le vcl_pipe. Passer une requête en pipe est assez dangereux, quand varnish fait un pipe cela signifie qu'il devient complètement aveugle à ce qui se passe dans le tuyau, il connecte le navigateur avec le backend, et ne regarde plus la suite du trafic. Avec les fonctions de Keepalive, ou de pipelining de http, cela signifie que vous autorisez une connexion entrante à discuter directement avec le backend, sans aucun contrôle sur les noms de domaines, urls, ou autre pour toutes les requêtes qui suivent la première. Bref, le pipe c'est à réserver à des cas très précis et très exceptionnels sur lesquels vous maîtrisez les deux côté de la chaîne (donc aussi le client).
Le vcl peut changer en fonction de la version de Varnish, vérifiez votre version, ne faites pas un copier-coller aveugle, il y a par exemple des modification de chaînage d'éléments entre la 4.0 et la 4.1 (et le chaînage dans un automate c'est assez important).
- https://github.com/varnishcache/varnish-cache/blob/4.0/bin/varnishd/builtin.vcl#L112
- https://github.com/varnishcache/varnish-cache/blob/4.1/bin/varnishd/builtin.vcl#L112
Pour cet exemple je prends une version 4.1.
Au fait, évitez à tout prix de travailler sur une version 3.x, ces versions sont trop anciennes, et ne sont plus activement gérées en terme de sécurité.
Load balancer : définition des backends
Prenons un début de fichier vcl:
# Marker to tell the VCL compiler that this VCL has been adapted to the
# new 4.0 format.
vcl 4.0;
import directors;
import std;
# Default backend definition. Set this to point to your content server.
backend backend_drupal_1 {
.host = "10.0.2.42";
.port = "80";
.connect_timeout = 5s;
.first_byte_timeout = 10s;
.between_bytes_timeout = 10s;
.probe = {
.request =
"GET /my_status_probe.php HTTP/1.1"
"Host: mydomain.example.com"
"Connection: close"
"Accept-Encoding: gzip";
.interval = 2s;
.timeout = 8s;
.window = 5;
.threshold = 2;
}
}
backend backend_drupal_2 {
.host = "10.0.2.43";
.port = "80";
.connect_timeout = 5s;
.first_byte_timeout = 10s;
.between_bytes_timeout = 10s;
.probe = {
.request =
"GET /my_status_probe.php HTTP/1.1"
"Host: mydomain.example.com"
"Connection: close"
"Accept-Encoding: gzip";
.interval = 2s;
.timeout = 5s;
.window = 5;
.threshold = 2;
}
}
sub vcl_init {
# create round-robin director with all backends
new lb_default = directors.round_robin();
lb_default.add_backend(backend_drupal_1);
lb_default.add_backend(backend_drupal_2);
}
(...)
Nous avons ici défini deux backends, nous y avons ajouté des requêtes de probe, ou health check. Celles-ci tournent toutes les 2s, et le backend a 5s pour nous envoyer une réponse, sinon il est considéré défaillant. Ou plutôt si pour les 5 derniers checks deux étaient en erreurs, alors le backend est considéré comme défaillant. Plus aucune requête ne serait alors envoyée vers ce backend jusqu'à ce que 3 sondes sur 5 soient de nouveau OK. On voit qu'il est possible d'écrire à peu près ce qu'on veut pour cette requête de vérification, un nom de domaine, un script spécifique, etc. Il n'y a pas du tout obligation d'utiliser le même nom de domaine que celui qui servira réèllement pour les requêtes utilisateur.
Au niveau du vcl_init on créé alors un director qui fonctionne en round robin (tournant) sur ces deux backends, ce qui signifie que par défaut le trafic sera redirigé aléatoirement entre les deux backends.
Pour le moment ce director n'est branché nulle part, donc il n'est pas utilisé. Mais c'est un bon début.
Quelques acl
On continue le vcl, avec la déclaration de règles d'acl, qui doivent être remontées assez haut dans le fichier (un peu comme des variables, il faut les définir avant de les utiliser).
Je crée pour le moment un groupe d'IP, le nom est libre, là j'utilise restricted. Notez que vous pourriez ne même pas définir d'acl, pas d'obligations. Ou bien en définir plusieurs.
# some IP having special restricted access
acl restricted {
"localhost";
"127.0.0.1";
"192.168.1.12";
"192.168.2.40";
}
(...)
vcl_recv : traitement des entrées
Arrive ensuite la définition d'un point important du vcl, le traitement des requêtes entrantes.
(...)
sub vcl_recv {
# Happens before we check if we have this in cache already.
#
# Typically you clean up the request here, removing cookies you don't need,
# rewriting the request, etc.
# RETURN ACTIONS ########################
# pipe: never do that
# pass: transfer to backend, almost transparent mode
# hash: check internal cache (or pass to backend)
# lookup: only used in vcl_hash, in vcl_recv it's hash
# fetch: used in vcl_pass, to make a pass
# purge : purge cache
# synth : error case
# ...
# NORMALIZATION OF ACCEPT-ENCODING HEADER
# either gzip, then deflate, then none
if (req.http.Accept-Encoding) {
if (req.url ~ "\.(jpeg|jpg|png|gif|ico|gz|tgz|bz2|tbz|mp3|ogg|woff|swf)(\?.*)?$") {
# No point in compressing these
unset req.http.Accept-Encoding;
} elsif (req.http.Accept-Encoding ~ "gzip") {
set req.http.Accept-Encoding = "gzip";
} elsif (req.http.Accept-Encoding ~ "deflate" && req.http.user-agent !~ "MSIE") {
set req.http.Accept-Encoding = "deflate";
} else {
# unkown algorithm
unset req.http.Accept-Encoding;
}
}
(...)
On vient de faire notre premier traitement de filtrage, sur l'entête Accept-Encoding, et on repère aussi que pour certains types de fichier on préfère éviter de se poser des questions, on vire carrément l'entête, pas de compression (statiques déjà compressés).
Ajoutons un filtrage sur les méthodes utilisées dans la requête.
(...)
if (req.method != "GET" &&
req.method != "HEAD" &&
req.method != "PUT" &&
req.method != "POST" &&
req.method != "OPTIONS" &&
req.method != "DELETE") {
# Non-RFC2616 or CONNECT which is weird, we remove TRACE also.
return(synth(501, "Not Implemented"));
}
(...)
On continue dans ce vcl_recv. Avec le retour du load balancing, le director créé dans vcl_init est branché sur la requête entrante. C'est à cet endroit que l'on pourrait choisir entre différents backends en fonction du nom de domaine (voir rejeter les domaines inconnus). En l'occurence on ne fait pas de restrictions, toutes les requêtes sont envoyées au backend.
(...)
# BACKEND CHOICE
# Here no filters on if (req.http.host ~ "foo.example.com$")
# As we have only one backend
# CATCH ALL
set req.backend_hint = lb_default.backend();
(...)
J'ajoute une petite règle, si la requête ne contient pas de Host je la rejette (en HTTP/1.1 le host est obligatoire, mais il existe aussi HTTP/1.0 (pour lequel c'est optionnel) et HTTP/0.9. Personnellement j'ai un peu de mal avec les vieilles versions de HTTP, surtout pour des raisons de sécurité, donc je jette.
(...)
if (! req.http.host) {
return(synth(400, "No host header, common, HTTP/1.1"));
}
(...)
Vous remarquerez que pour renvoyer une réponse d'erreur il faut simplement utiliser
cette syntaxe return(synth(400, "message"));. On a vu plus haut aussi un return(synth(501, "Not Implemented")); qui renvoit une 501. Pour savoir quel code renvoyer retenez que les erreurs en 40x sont des erreurs de requêtes et les erreurs 50x des erreurs côté serveur, mais dans le doute, face à quelque chose de bizarre n'hésitez pas à renvoyer du 400.
Regardons d'ailleurs comment tester certains chemins et rejeter les gens qui ne font pas partie d'un groupe d'acl. L'acl restricted me donnait des ip locales, ou bien des IP de monitoring. Je peux donc par exemple lister des chemins en rapport avec le monitoring (et les health_check) et restreindre les accès à ces chemins:
(...)
# Do not cache these paths and restrict access
if (req.url ~ "^/monitoring_fpm_status" ||
req.url ~ "^/monitoring_nginx_status") {
if (!client.ip ~ restricted) {
return(synth(405, "Not Allowed"));
} else {
return (pass);
}
}
if (req.url ~ "^/my_status_probe\.php" ) {
if (! (std.ip(regsub(req.http.X-Forwarded-For, "[, ].*$", ""), client.ip)~ restricted)) {
return(synth(405, "Not Allowed"));
}
}
(...)
Plusieurs points à bien regarder:
- le '.' dans l'url devait être échappé (".").
- le
return (pass)mets fin au traitement vcl_recv, c'est un return, et indique qu'on doit faire un pass. Le pass signifie qu'on re regarde pas dans le cache, on renvoit directement vers un backend. - sur la première règle on regarde l'IP du client qui nous fait une connexion HTTP (qui n'est peut-être pas l'IP d'origine de la requête, c'est peut-être juste l'agent qui est devant nous, comme un terminateur ssl, ou un autre load balancer. Sur la deuxième règle on cherche l'IP dans la chaîne de serveurs qui ont retransmis le message, grâce au header X-Forwarded-For.
Commençons à nettoyer les cookies, avec unset req.http.cookie; (soit: la destruction de l'entête Cookie dans la requête entrante). On peut par exemple identifier des fichiers statiques :
(...)
if (
req.url ~ "\.(css|js|jpeg|jpg|png|gif|ico|gz|tgz|bz2|tbz|mp3|ogg|woff|eot|ttf|svg|otf|swf|html|htm|htc|map|json)(\?.*)?$"
) {
unset req.http.cookie;
}
# clean static files from cookies, so that we can cache them all
if (req.url ~ "^(/(en|fr|nl))?/sites/([^/]*)/files") {
unset req.http.cookie;
}
(...)
On peut aussi, à l'inverse, gérer un ensemble de chemins qui ne sont jamais anonymes, sur lesquels il ne faudrait surtout pas enlever les cookies, et encore moins essayer de chercher une réponse dans le cache (en utilisant un return (pass) on sait que l'on va éviter de regarder dans le cache).
Je vais par exemple faire une exception dès maintenant sur les paths du back office.. Je donne ci-dessous un exemple pour un Drupal, avec 3 langues gérées, et une exclusion basée sur les chemins et non un nom de domaine. Il pourrait y avoir d'autres url à gérer, en fonction des modules utilisés, mais ceci donne un bon point de départ sur les urls de backoffice Drupal (qui renverront presque toutes des 403 si vous êtes anonyme). N'oubliez pas de gérer/tester les urls qui permettent de se connecter au site.
Il y a d'autres moyens de gérer le backoffice, avec un sous domaine spécifique par exemple. Ici on décide de lister certains chemins pour lesquels, sans se poser trop de questions, on évite de faire travailler le Reverse Proxy cache (on file directement à l'étape pass, passe-plat transparent).
(...)
# Do not cache these paths.
if (
(req.url ~ "^(/(en|fr|nl))?/admin")
|| (req.url ~ "^(/(en|fr|nl))?/admin/.*")
|| (req.url ~ "^(/(en|fr|nl))?/batch")
|| (req.url ~ "^(/(en|fr|nl))?/entityreference/autocomplete/.*")
|| (req.url ~ "^(/(en|fr|nl))?/file/[^/]+/delete")
|| (req.url ~ "^(/(en|fr|nl))?/file/[^/]+/edit")
|| (req.url ~ "^(/(en|fr|nl))?/file/[^/]+/edit/[^/]+")
|| (req.url ~ "^(/(en|fr|nl))?/file/[^/]+/edit/add/[^/]+/[^/]+")
|| (req.url ~ "^(/(en|fr|nl))?/file/[^/]+/translate")
|| (req.url ~ "^(/(en|fr|nl))?/file/[^/]+/translate/delete/[^/]+")
|| (req.url ~ "^(/(en|fr|nl))?/file/add")
|| (req.url ~ "^(/(en|fr|nl))?/file/add/.*")
|| (req.url ~ "^(/(en|fr|nl))?/media/[^/]+/edit/.*")
|| (req.url ~ "^(/(en|fr|nl))?/media/[^/]+/format-form")
|| (req.url ~ "^(/(en|fr|nl))?/media/browser")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/delete")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/edit")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/edit/[^/]+")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/edit/add/[^/]+/[^/]+")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/revisions")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/revisions/[^/]+/delete")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/revisions/[^/]+/revert")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/translate")
|| (req.url ~ "^(/(en|fr|nl))?/node/[^/]+/translate/delete/[^/]+")
|| (req.url ~ "^(/(en|fr|nl))?/node/add")
|| (req.url ~ "^(/(en|fr|nl))?/node/add/.*")
|| (req.url ~ "^(/(en|fr|nl))?/taxonomy/term/[^/]+/edit")
|| (req.url ~ "^(/(en|fr|nl))?/taxonomy/term/[^/]+/edit/.*")
|| (req.url ~ "^(/(en|fr|nl))?/taxonomy/term/[^/]+/translate")
|| (req.url ~ "^(/(en|fr|nl))?/taxonomy/term/[^/]+/translate/.*")
|| (req.url ~ "^(/(en|fr|nl))?/user/[^/]+/cancel")
|| (req.url ~ "^(/(en|fr|nl))?/user/[^/]+/edit")
|| (req.url ~ "^(/(en|fr|nl))?/user/[^/]+/edit/account")
) {
return (pass);
}
(...)
Et passons à une étape souvent importante, la dernière simplification/destruction de cookies.
Lors de cette étape on enlève tous les cookies js et on ne garde des cookies que si on veut laisser des accès non anonymes aux pages du front.
On peut intégrer des patterns de cookies à garder, par exemple je vais garder les cookies nommés NOCACHE ou TOTO. Votre algorithme peut être différent de celui de l'exemple. Pour cet exemple les sessions PHP ne seront gardées que si l'utilisateur possède un cookie NOCACHE ou un cookie TOTO. Le premier cookie serait typiquement un cookie à durée de vie très courte posé par le site après certaines opérations en POST, et le deuxième un cookie généré pour certains utilisateurs du backoffice (rôle contributeur avancé) leur permettant de naviguer sur la partie front du site tout en étant connecté. le nom TOTO est un exemple, je vous conseille de trouver un nom plus parlant.
(...)
# Remove all cookies that Drupal doesn't need to know about. ANY remaining
# cookie will cause the request to pass-through to Nginx. For the most part
# we always set the NO_CACHE cookie after any POST request, disabling the
# Varnish cache temporarily. Same goes for power users, for whom the
# TOTO cookie is set as long as they are connected (it has the same purpose).
if (req.http.Cookie) {
# If we have SESS* but not any NOCACHE/TOTO we will destroy it.
# If we do not see NOCACHE/TOTO in the cookies, then simply destroy
# all cookies
if (! req.http.Cookie ~ "NOCACHE=Y" && ! req.http.Cookie ~ "TOTO=Y") {
# no NOCACHE cookie, destroy everything, even php sessions
unset req.http.Cookie;
}
}
(...)
On trouve très souvent d'autres règles, comme celle indiquée ci-dessous, permettant un nettoyage en finesse de la chaîne de cookies. On liste les 3 valeurs autorisée (pour notre exemple NOCACHE/TOTO et PHPSESSID). On applique une série de transformations/nettoyages à base de regsuball. Et si à la fin la chaîne de cookie est vide, alors on vire tous les cookies. Si la chaîne de cookies n'est pas vide on n'utilisera pas le cache, et en plus on aura viré tous les cookies js.
Ici je n'utilise pas cette règle. Elle signifie que la présence d'au moins l'un des trois cookies permettrait de ne pas utiliser de cache. Donc si j'avais un cookie de session, possiblement une session anonyme créée pour afficher un message, je ne bénéficierais plus du cache, jamais. Et là mon but est justement d'éviter ce cas.
(...)
# Successive operations clean cookies, as illustrated in the example below.
# a=b; SESS4564645=123; c=d; NOCACHE=Y;TOTO=Y; x=y
# ;a=b; SESS4564645=123; c=d; NOCACHE=Y;TOTO=Y; x=y
# ;a=b;SESS4564645=123;c=d;NOCACHE=Y;TOTO=Y;x=y
# ;a=b; SESS4564645=123;c=d; NOCACHE=Y; TOTO=Y;x=y
# SESS4564645=123; NOCACHE=Y; TOTO=Y
#
# Add a semi-colon as prefix to make regexps easier.
set req.http.Cookie = ";" + req.http.Cookie;
# Remove spaces before cookie names.
set req.http.Cookie = regsuball(req.http.Cookie, "; +", ";");
# Add spaces before cookies we want to keep.
set req.http.Cookie = regsuball(req.http.Cookie, ";(SSESS[a-z0-9]+|SESS[a-z0-9]+|NO_CACHE|TOTO)=", "; \1=");
# And remove cookies without spaces before them.
set req.http.Cookie = regsuball(req.http.Cookie, ";[^ ][^;]*", "");
# Trim remaining spaces and semi-colons.
set req.http.Cookie = regsuball(req.http.Cookie, "^[; ]+|[; ]+$", "");
if (req.http.Cookie == "") {
# If there are no remaining cookies, remove the cookie header. If there
# aren't any cookie headers, Varnish's default behavior will be to cache
# the page.
unset req.http.Cookie;
}
(...)
Pour finir ce vcl_recv nous ajoutons une dernier filtre, si de l'authentification HTTP est en place on évite le cache (après pour tester de l'authent HTTP avec du cache, si vous avez un login/password très simple et destiné uniquement à bloquer l'indexation, il est possible d'utiliser Varnish pour tester cette authentification et de gérer un mode cache avec ces headers, mais ce serait le sujet d'un autre article).
(...)
# if (req.http.Authorization || req.http.Cookie) {
if (req.http.Cookie) {
# Not cacheable, by definition
return(pass);
}
# else we do an internal cache check
# was lookup in previous versions of varnish
return(hash);
}
(...)
Voilà pour le recv. On voit que pour toutes les requêtes qui sont arrivées au bout de la méthode sans avoir de return (pass) demandant de ne pas aller voir le cache ou de synth() générant une erreur, on redirige vers le point suivant de l'automate qui est hash. Le traitement suivant consitera donc à établir une clef de cache avec vcl_hash.
Beaucoup de requêtes ont été modifiées et ne possèdent plus de cookies. D'autres sont déjà parties en pass, vers le backoffice par exemple. Il nous reste cependant des requêtes avec des cookies, pour les utilisateurs qui avaient les bons cookies (comme TOTO) et qui visitent le front. Varnish ne mettra pas en cache ces requêtes, à cause des cookies, mais vous pourriez ajouter un else { return(pass); } au if qui détectait la présence des cookies TOTO et NOCACHE, cela reviendrait au même.
Tant que j'en suis aux appartées, il existe pass et pipe, et comme je le disais beaucoup plus haut pipe est assez dangereux, car il n'examine que la première requête puis laisse le client et le backend discuter entre eux dans la communication tcp/ip. En ajoutant cette version de vcl_pipe vous pouvez réduire le problème, en rendant inutile le pipe au passage. J'ajoute l'entête 'Connection: close' dans toutes les réponses, un client HTTP normalement constitué devrait alors fermer la connexion TCP/IP après avoir reçu la réponse à la première requête.
sub vcl_pipe {
# Avoid pipes like plague
set req.http.connection = "close";
return(pipe);
}
Hash: la clef de cache
Ici je vous donne un exemple de vcl_hash, l'idée est d'ajouter des paramètres variables de votre clef de cache. Vous pourriez ajouter la valeur d'un entête particulier. Attention cependant à ne pas rendre votre cache trop spécifique, si chaque requête génère une clef différente il n'y a plus de cache hits.
sub vcl_hash {
hash_data(req.url);
hash_data(req.http.host);
# BUG: vary accept-encoding seems to be wiped out
# on some js response, enforce it!
if (req.http.Accept-Encoding) {
hash_data(req.http.Accept-Encoding);
}
# Include the X-Forward-Proto header, since we want to treat HTTPS
# requests differently, and make sure this header is always passed
# properly to the backend server.
if (req.http.X-Forwarded-Proto) {
hash_data(req.http.X-Forwarded-Proto);
}
return(lookup);
}
Backend response: traitement de la réponse
Voici vcl_backend_response, une autre étape importante, nous traitons ici toutes les requêtes en provenance du backend (avant de les envoyer vers deliver qui les enverra au client).
Normalement le backend est celui qui pilote la durée de cache des pages. Varnish peut s'appuyer sur de nombreux headers renvoyés par le backend pour décider la durée de rétention des réponses reçues (s-maxage, max-age, expires, etc.). Avec un Drupal possédant le cache de page actif les headers seront présents. Mais il est possible de changer ce comportement en forçant dans le vcl certains réglages. Je donne ci-dessous quelques exemples de valeurs forcées.
L'objet beresp est une backend-response. C'est donc la réponse HTTP que l'on a reçue du serveur. Lorsque l'on fait un set beresp.uncacheable = true et un return (deliver) on empêche la mise en cache de la réponse.
sub vcl_backend_response {
# Happens after we have read the response headers from the backend.
#
# Here you clean the response headers, removing silly Set-Cookie headers
# and other mistakes your backend does.
if (beresp.http.X-No-Cache) {
set beresp.uncacheable = true;
return (deliver);
}
Ici on va traiter l'information fournie par le backend comme quoi la page fournie n'est pas cacheable, mais on se réserve le droit de revérifier plus tard.
# HTTP/1.0 Pragma: nocache support
if (beresp.http.Pragma ~ "nocache") {
set beresp.uncacheable = true;
set beresp.ttl = 120s; # how long not to cache this url.
}
Ici pour tous les statiques reçus on fait un peu de nettoyage (certains statiques peuvent être générés dynamiquement par du PHP, il ne faudrait pas qu'un set-cookie soit présent dans la réponse). Et on décide nous même de la durée de cache (on aurait pu configurer cela dans la gestion des expires de Nginx). Remarquez que l'on modifie l'entête Cache-Control pour y mettre une autre valeur que la durée de cache que Varnish va utiliser. Ceci permet de définir une durée de cache par les navigateurs, différente de celle utilisée par Varnish.

Remarquez aussi un traitement différencié sur quelques chemins, qui nous permet d'appliquer un temps de cache beaucoup plus court sur certaines ressources dont nous savons qu'elles nécessitent un rafraîchissement plus régulier. On force un temps différent (plus court) pour Varnish et pour le navigateur client par rapport à ce que l'applicatif aurait pu nous envoyer par défaut.
if (bereq.url ~ "\.(css|js|jpeg|jpg|png|gif|ico|gz|tgz|bz2|tbz|mp3|ogg|woff|eot|ttf|svg|otf|swf|html|htm|htc|map|json)") {
# Don't allow static files to set cookies.
unset beresp.http.set-cookie;
# Enforce varnish TTL of static files
set beresp.ttl = 1h;
# will make vcl_deliver reset the Age: header
set beresp.http.magic_age_marker = "1";
# Enforce Browser cache control policy
unset beresp.http.Cache-Control;
unset beresp.http.expires;
set beresp.http.Cache-Control = "public, max-age=900";
# Specific TTL for some resources are defined below.
if (bereq.url ~ "foobar\.json(\?.*)?$") {
# Cache the "foobar" for 5 minutes only
set beresp.ttl = 300s;
set beresp.http.Cache-Control = "public, max-age=300";
}
if (bereq.url ~ "^(/(en|fr|nl))?/zorg/.*") {
# Microcache for theses ones (dynamic data sources from drupal)
# we do not need more than 1 minute
set beresp.ttl = 60s;
set beresp.http.Cache-Control = "public, max-age=60";
}
}
On peut même décider de cacher certaines erreurs (qui n'ont sans doute pas les entêtes de cache adaptées au départ), j'ajoute un entête cache-control dans la requête pour que Varnish puisse s'en servir lors des tests suivants (vu que je ne fais pas un return).
# cache 404 for 60s
if (beresp.status == 404) {
set beresp.ttl = 60s;
set beresp.http.Cache-Control = "max-age=60";
}
Ici j'ajoute certains entêtes de debug, si une page me renvoie un set-cookie, je ne cacherai pas et j'ajouterai un entête explicatif.
if (beresp.http.Set-Cookie) {
set beresp.http.X-Varnish-Cacheable = "NO:Not Cacheable setting cookie";
set beresp.uncacheable = true;
return(deliver);
}
Même chose, j'ajoute un entête pour indiquer que Varnish n'a pas trouvé d'entête dans cette réponse lui donnant un temps de cache possible.
if (beresp.ttl <= 0s) {
set beresp.http.X-Varnish-Cacheable = "NO:Not Cacheable";
set beresp.uncacheable = true;
return(deliver);
} else {
# varnish TTL will be the one set by the application
# set beresp.ttl = ;
# will make vcl_deliver reset the Age: header
set beresp.http.magic_age_marker = "1";
# Enforce Browser cache control policy
# this should be shorter than the real ttl managed by Varnish
unset beresp.http.Cache-Control;
unset beresp.http.expires;
set beresp.http.Cache-Control = "public, max-age=300";
}
Toujours un peu de debug. Et on termine vcl_backend_response.
if (beresp.uncacheable) {
set beresp.http.X-Varnish-Cacheable = "No, in fact.";
} else {
set beresp.http.X-Varnish-Cacheable = "YES";
}
set beresp.http.X-Varnish-TTL = beresp.ttl;
return(deliver);
}
Deliver: la réponse est prête
L'étape suivante consiste donc à renvoyer cette réponse au client (navigateur).
Vous avez peut-être repéré le marqueur magic_age_marker ajouté au paragraphe précédent, on s'en sert pour l'effacer à cette étape après avoir appliqué un traitement de nettoyage de l'âge affiché de la réponse. On n'a pas directement effacé l'information d'âge dans vcl_backend_response pour que Varnish puisse utiliser cette information d'âge en interne, on ne l'efface que maintenant, juste avant l'envoi.
sub vcl_deliver {
# Happens when we have all the pieces we need, and are about to send the
# response to the client.
#
# You can do accounting or modifying the final object here.
set resp.http.X-Varnish-Cache-Hits = obj.hits;
# magic marker use to avoid giving real age of object to browsers
if (resp.http.magic_age_marker) {
unset resp.http.magic_age_marker;
set resp.http.age = "0";
}
# hide Cache Tagging
unset resp.http.X-Cache-Tags;
}
Hits, et période de grâce
Si vous avez eu le courage d'arriver à ce point on va pouvoir ajouter une petite fonction en extra, une période de grâce.
Nous avons un cache devant le site, si le site est tombé il ne sera pas en mesure de rafraîchir les données du cache, et lorsque les pages atteindrons la fin de validité dans le cache, elles ne serons plus disponible, le site affichera des erreurs. Ce n'est pas super. La période de grâce c'est le temps pendant lequel on s'autorise à servir des pages qui ne devraient plus être valides, parce que le site ne répond plus.
Première chose à faire, il faut ajouter quelques éléments dans le traitement de la réponse (en haut du vcl_backend_response que nous avions).
Ici j'ajoute 3 jours de période de grâce à toutes les réponses que je reçois:
sub vcl_backend_response {
# Happens after we have read the response headers from the backend.
#
# Here you clean the response headers, removing silly Set-Cookie headers
# and other mistakes your backend does.
# Allow the backend to serve up stale content if it is responding slowly.
set beresp.grace = 3d;
Et ensuite je capture les réponses 50x du site, par exemple les 503 de la page de maintenance de Drupal. Et je regarde si un marqueur do_not_use_50x_responses est en place (on va voir juste après d'où il vient). Si c'est le cas je ne traite pas cette réponse (abandon). Donc je ne l'enverrai pas au client, et je n'essayerai pas non plus de la stocker dans le cache.
if (beresp.status >= 500 && beresp.status < 600 && bereq.http.do_not_use_50x_responses) {
# we have an error from the backend (or a maintenance mode)
# but the do_not_use_50x_responses means this page came after a vcl_hit.
# we do not want to replace the stale-grace cached object with an error or
# maintenance page, this was a background check, we can abandon it
return (abandon);
}
Regardons vcl_hit, c'est le point d'entrée pour toutes les pages qui sont regardées dans le cache et qui y sont retrouvées (un hit, quoi).
sub vcl_hit {
if (obj.ttl>0s) {
// classical hit with an object having a ttl
return(deliver);
}
Le début était classique, j'ai un hit dans le cache, et la page avait une durée de validité (ttl) supérieure à 0, je passe directement au deliver.
Maintenant le ttl est peut-être inférieur à 0, ce qui veut dire que cette page n'est plus valide en cache. Nous allons donc faire intervenir le temps de grâce qui a été stocké dans cette page grâce au vcl_backend_response précédent :
if (obj.ttl + obj.grace > 0s) {
// --- GRACE MODE ---
// object is in grace period
// backend seems to be quite in a bad mood
// if a code 50x is triggered, like maintenance page
// or an error, this marker will prevent the result
// from overriding the cache with this error
set req.http.do_not_use_50x_responses = true;
// we will deliver it but this will trigger a background fetch
return (deliver);
}
// Synchronously refresh the object from the backend despite the
// cache hit. Control will eventually pass to vcl_miss
// this should be return(miss) in 4.1 and return(fetch) in 4.0
return(miss);
//return(fetch);
}
Ce qui se passe est un peu complexe. Et n'hésitez pas à tester ce mode avec d'autres réglages. Ici j'applique la grâce en forçant l'envoi vers deliver alors que le ttl est inférieur à zéro, mais en même temps j'ajoute un petit marqueur dans la requête http (le do_not_use_50x_responses). Quand une requête touche un objet qui entre en période de grâce Varnish va quand même faire une requête vers le backend pour le rafraîchir, on fait un deliver mais celui-ci n'empêche pas la demande de rafraîchissement en tâche de fond (en asynchrone). En ajoutant le marqueur spécial je signale à mon vcl_backend_response que toute réponse du backend arrivant avec un 50x (comme la page de maintenance) n'est pas une réponse valide pour le rafraîchissement du cache.
Si vous testez la période de grâce pensez à tester le comportement avec des serveurs de backend complètement down (éteints), ou des serveurs qui renvoient des pages de maintenance, c'est différent.
Si vous êtes arrivés jusqu'ici vous voyez sûrement à quel point on peut définir des comportements variés pour Varnish, il n'y a pas de solutions qui marchent dans tous les cas, il faut tester le comportement. Et surtout bien adapter la configuration à la version de varnish utilisée.
Actualités en lien
Bibliothèque d’authentification OpenID Connect Django
Django
08/04/2025
DbToolsBundle, sortie de la version 2
Symfony
18/03/2025
Drupal SEO Recipe
Drupal
14/01/2025
