Makina Blog
Le projet Agrégateur : fusionner des bases de données Geotrek
Des connecteurs génériques et personnalisables, appelés les parseurs, permettent d'importer dans une instance Geotrek des données en provenance d’autres plateformes grâce aux APIs exposées par ces dernières : Tourinsoft, Apidae, EspritParc, etc. Symétriquement, Geotrek Admin expose sa propre API pour apporter l’accès aux données à d’autres outils, dont Geotrek-Rando-v3. Continuité logique de cette problématique, la question du partage des données entre différentes instances Geotrek se pose depuis 2019.
Besoin
La gestion des données réalisée de manière indépendante par chaque structure territoriale, bien que favorisant la finesse et la qualité de l’information, pose question sur des territoires qui s’entrecoupent et se chevauchent. Par exemple, une même randonnée située à l’intersection d’un Parc National et d’un Département peut avoir intérêt à être répertoriée aussi bien dans l’instance Geotrek du premier que du second. Il peut alors y avoir une duplication du même travail de cartographie par les deux structures, ce qui n’est pas souhaitable.
C’est le constat fait par le Département des Hautes-Alpes en partenariat avec l’Agence Départementale de Développement Économique (ADDET05) et le Comité Départemental de la Randonnée Pédestre (CDRP05), qui se sont penchés depuis 2019 sur une solution de fusion des données. Ainsi, ces acteurs peuvent utiliser, en plus de leurs données propres, des contenus déjà référencés dans les instances Geotrek de la Communauté de Communes du Sisteronais-Buëch (CCSB), du Parc National des Ecrins (PNE) et des Parcs Naturels Régionaux de Provence-Alpes-Côte d'Azur (PNRPACA). La même question s'est également posée en 2021 entre le Conseil Département de Lozère, et les Parcs Naturels des Grandes Causses, d'Aubrac et des Cévennes.
Nous appelons “agrégateur” l’outil automatisé réalisant cette tâche de fusion des données en provenance de plusieurs instances Geotrek.
Contraintes techniques
La fusion des données en provenance de plusieurs Geotrek-Admin, nous met face à deux obstacles majeurs.
Contrainte des correspondances des catégories
Pour chaque type d’objet, plusieurs catégories existent. Les randonnées par exemple sont divisées en différentes pratiques sportives : “Pédestre”, “Équitation”, ”VTT”, etc. Les contenus touristiques eux sont catégorisés par des types tels que :“Logement”, “Restaurant”, “Musée”…
Ces catégories, bien que disponibles avec des valeurs par défaut, sont configurables et souvent personnalisées dans chaque Geotrek. En conséquence, nous pouvons avoir une catégorie “Pédestre” dans une instance source qui correspond à la catégorie “À pied” dans un autre Geotrek. Nous pouvons aussi imaginer que plusieurs catégories doivent fusionner en une seule. Par exemple, “Marche nordique” et “Pédestre” peuvent avoir besoin d’être regroupées dans la catégorie “À pied”.
Pour pouvoir fusionner les bons contenus dans les bonnes catégories, il est nécessaire de maintenir à jour un “mapping”, c’est-à-dire une correspondance qui définit comment fusionner les catégories sources vers les catégories de destination.
Contraintes de la segmentation dynamique
Geotrek-admin peut s’installer selon deux modes de fonctionnement appelés “avec segmentation dynamique” ou “sans segmentation dynamique”. La différence réside dans la manière dont sont stockées les données géographiques. Dans le premier mode, de nombreux liens sont créés pour représenter des relations entre les objets, en particulier avec les tronçons qui servent de “position de référence” pour les autres objets. Cela signifie qu'avant de pouvoir importer les autres données, il faut d'abord importer le réseau de tronçon A dans la base B. Or ces tronçons peuvent venir entrecouper des tronçons pré-existants dans la base B, ce qui déclenche des calculs automatiques incluant notamment une redécoupe des tronçons à chaque intersection. Il devient donc :
- Très difficile de comparer le réseau A avec le réseau B pour pouvoir le mettre à jour correctement et maintenir la synchronisation entre les deux réseaux
- Impossible de recréer la géométrie d'un linéaire (comme une randonnée) qui se référe à un tronçon dans la base A ayant été séparé en plusieurs tronçons dans la base B à cause d'une intersection
Ce problème de fusion des réseaux de tronçons a toujours empêché l'import des Itinéraires et des autres objets liés aux tronçons dans Geotrek Admin.
Avec le mode sans segmentation dynamique, les géométries sont stockées “telles quelles” sans lien relationnel avec les tronçons, ce qui simplifie grandement la structure de données et favorise donc l'import de ces dernières.
Première version
Le Département des Hautes-Alpes a financé le développement d’une première version de l’agrégateur en 2019. Cet outil etait spécifiquement adapté à l'architecture logicielle entre Geotrek Admin et Geotrek Rando dans sa version 2. Celui-ci permettait de fusionner uniquement les données à destination de Geotrek-Rando-v2. Des données en provenance des quatre structures impliquées purent être publiées sur le même site public. Ceci a permis de répondre au besoin de valorisation, mais pas au besoin de gestion puisque ces mêmes données ne sont pas rendues disponibles dans Geotrek Admin.
Cette solution nécessitait de répondre au premier obstacle technique, ci-dessus, en maintenant à jour une correspondance de catégories spécifiées dans un fichier de configuration. De plus, elle n’était pas concernée par le second obstacle technique puisque les objets n’étaient pas sauvés en base.
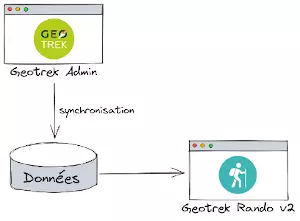
Architecture entre Geotrek-Admin et Geotrek-Rando-v2
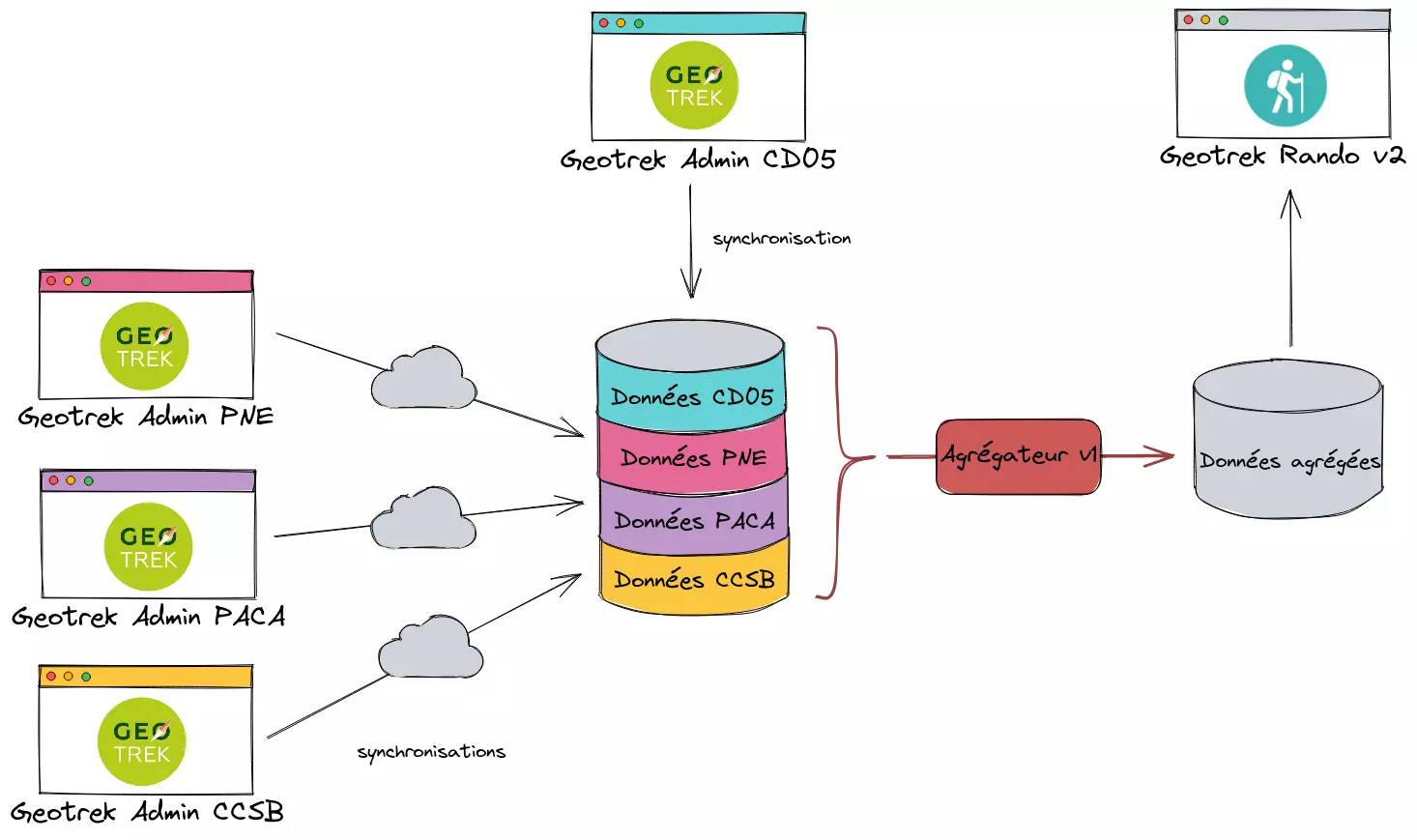
Architecture d'agrégation version 1
Seconde version
Développements
Suite à l’apparition de l’APIv2 dans Geotrek Admin exposant les données sur demande, à destination notamment de Randov3, une version plus complète de l'agrégateur a pu être conçue.
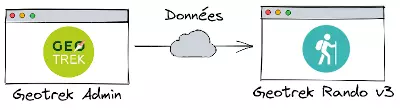
Architecture entre Geotrek-Admin et Geotrek-Rando-v3
Premièrement, le parc des Cévennes a effectué un travail de fond sur le modèle de données sous-jacent et les problématiques auxquelles l'agrégateur devait répondre. Suite à ces travaux la piste retenue fut la suivante :
- L’agrégateur sera une instance Geotrek Admin dédiée, fonctionnant sans segmentation dynamique. Il peut importer de manière indifférenciée des données exposées sur une API Geotrek qui fonctionne avec ou sans segmentation dynamique.
- La base de code existante pour les parseurs sera adaptée pour créer un parseur Geotrek capable d'importer un maximum de données selon les modalités décrites dans un fichier de configuration dédié.
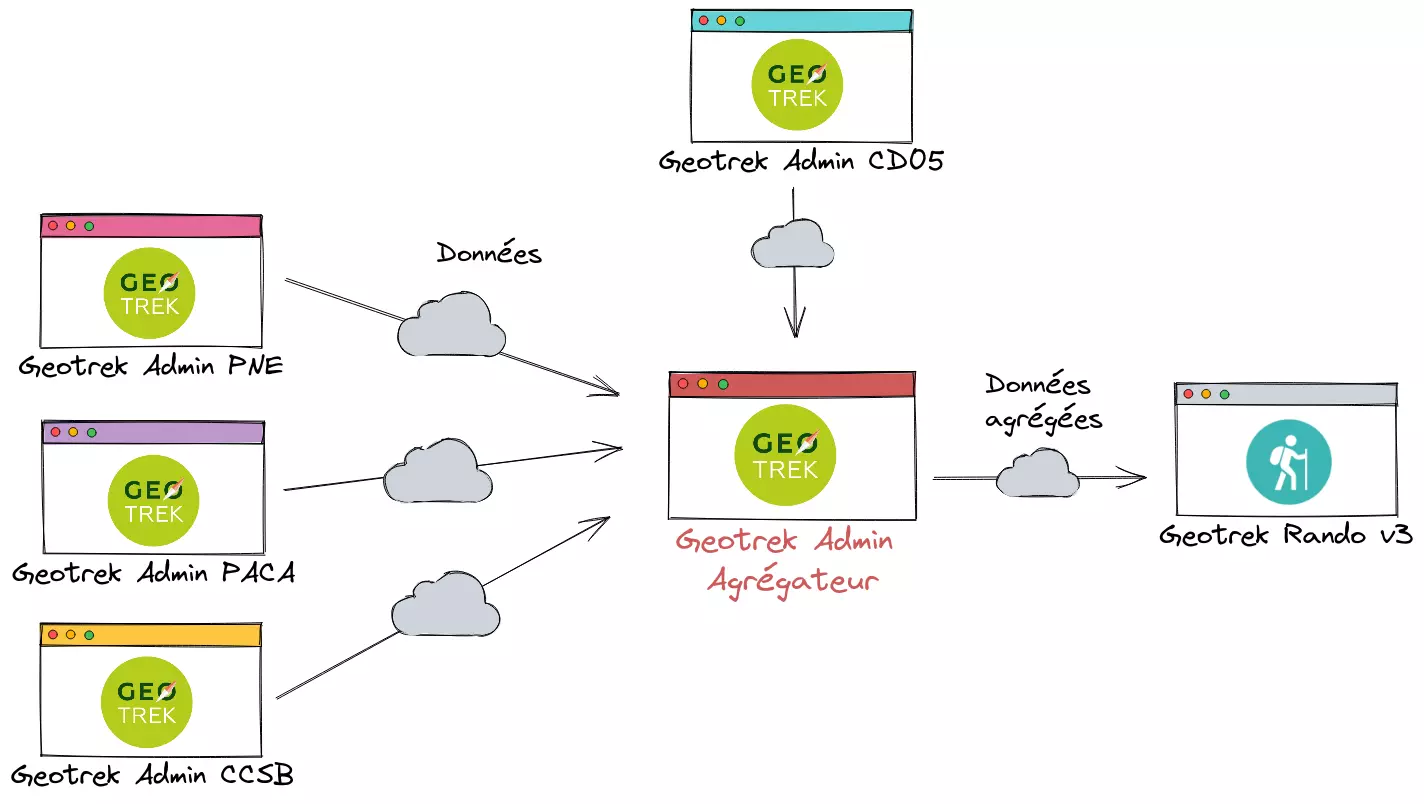
Architecture d'agrégation version 2
Makina Corpus s’est jointe à la réflexion pour concevoir l’implémentation de la version définitive. En anticipation de cette implémentation, deux développements préliminaires ont été réalisés :
- Chaque objet de la base de données Geotrek est désormais caractérisé par un identifiant unique (UUID), qui permet de repérer le même objet à travers les différentes bases.
- Un champ “provider” (fournisseur) est ajouté sur tous les objets agrégés afin de déterminer quelle est la plateforme source de ces objets. Ceci permet notamment à chaque connecteur de différencier les objets qu’il doit mettre à jour de ceux qu’il ne doit pas modifier.
Architecture logicielle détaillée
La classe Parser est la classe de base à tous les connecteurs existants : connecteurs entre Geotrek mais aussi connecteurs Tourinsoft, Apidae… Chaque parser se connecte à une API grâce à une URL fixe.
Une classe dédiée GeotrekParser implémente les spécificités de connexion vers une API Geotrek et la récupération des catégories pour chaque module.
Un parseur est ensuite créé pour chaque type de données (Signage, Trek, …) et ajoute quelques spécificités pour chaque modèle.
Par exemple, le parseur pour les itinéraires GeotrekTrekParser va d’abord s’assurer de télécharger les différentes pratiques sportives, les niveaux de difficulté, les thèmes, avant de récupérer chaque randonnée c'est-à-dire sa géométrie et ses attributs propres.
Finalement, un méta-parseur GeotrekAgregatorParser joue le rôle de chef d’orchestre et s’occupe de lancer chacun des parseurs définis précédemment, en respectant les instructions définies dans un fichier de configuration qui contient entre autres :
- Les URLs des instances Geotrek dont nous allons télécharger les données
- Le mapping des catégories entre chaque instance source et l’instance locale de destination
- Les paramètres à utiliser pour les appels d’API, permettant d’affiner la récupération de certaines données seulement
Une fois le premier import effectué, l’agrégateur va pouvoir maintenir les informations à jour en s’assurant de vérifier la date de modification de chaque objet pour ne pas re-télécharger les informations qui n’ont pas changé.
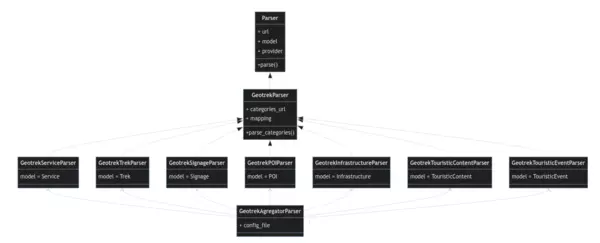
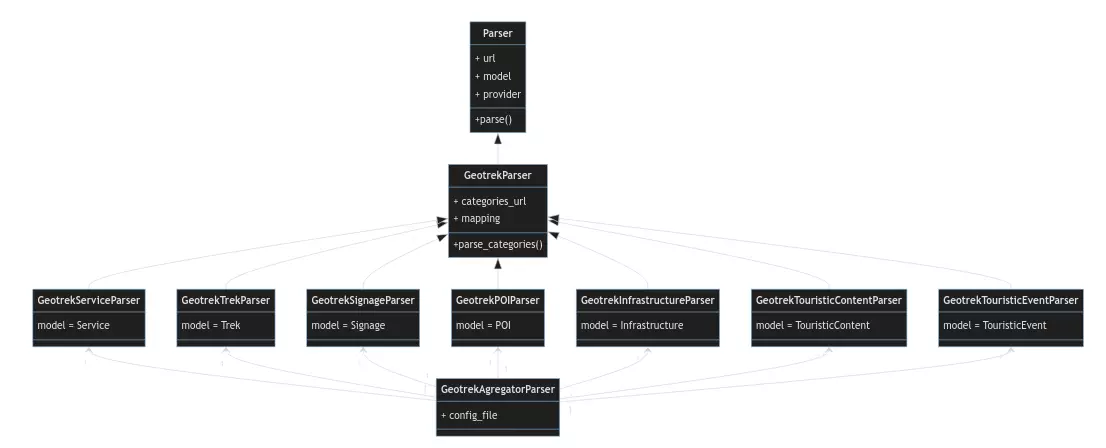
Diagramme de classes simplifié des parsers Geotrek
Résultats
Depuis fin 2022, le nouvel agrégateur est en fonctionnement et les données résultantes sont exposées sur le site dédié alpesrando.net. Ce projet est valorisé par l’Agence Départementale de Développement Économique et Touristique des Hautes-Alpes (ADDET) et animé par les équipes du Département des Hautes-Alpes.
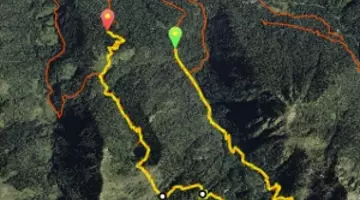
Voici une représentation des randonnées consultables sur cette instance selon les différentes sources agrégées.
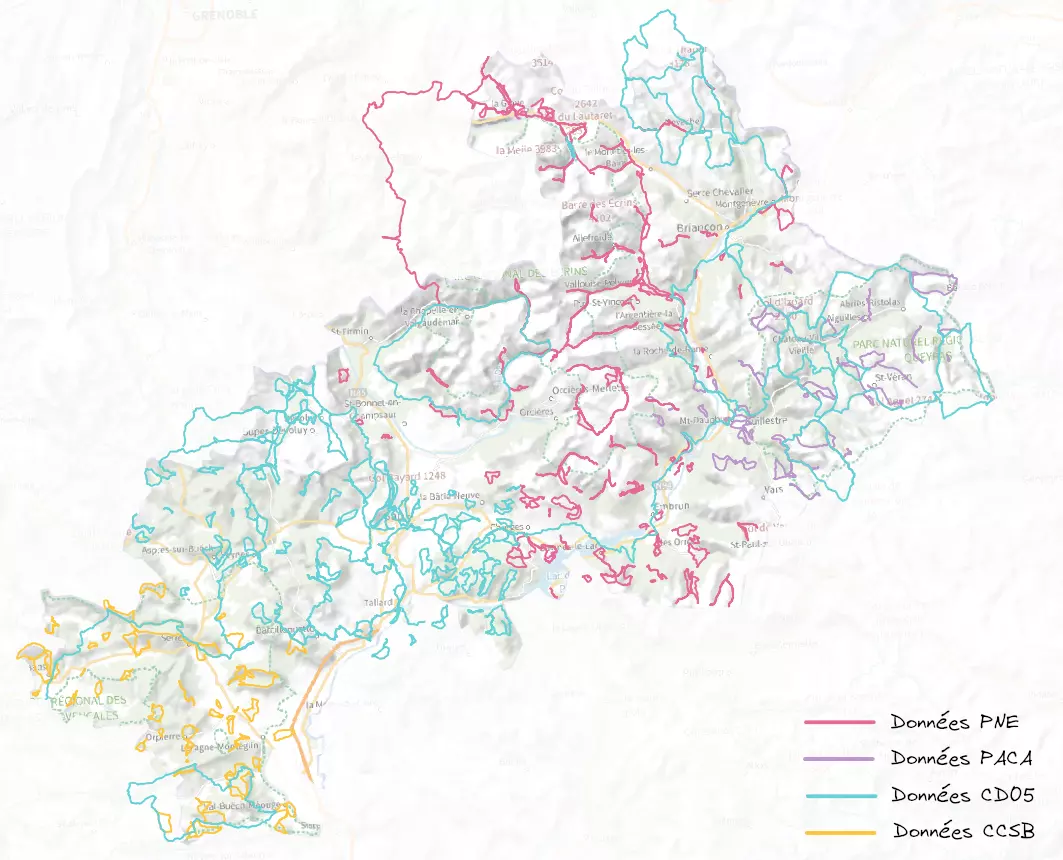
Randonnées agrégées en production
Améliorations futures
Des développements restent à effectuer pour finaliser les imports suivants :
- Importer les données du module Outdoor
- Importer les traductions des noms des catégories
- Importer automatiquement un pictogramme pour les catégories
- Importer les cotations et les bureaux d’informations dans le module Itinéraire
- Importer le champ Source transversal aux différents modules
Conclusion
Projet de long cours ayant mobilisé de nombreux acteurs, le développement de l'agrégateur Geotrek est une réponse au besoin de mutualisation des données entre différentes structures utilisatrices sur un même territoire. Il s'agit d'une solution répondant à de fortes contraintes techniques pré-existantes, apportant en contrepartie son propre lot de contraintes puisqu'il requiert notamment l'utilisation d'un Geotrek sans segmentation dynamique, en l'occurence pour les Hautes-Alpes via le déploiement d'une nouvelle instance dédiée à l'agrégation.

Python-Django-SSI
Formations associées
Formations Django
Formation Django initiation
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation Django initiationFormations Geotrek
Formation Administration et personnalisation de Geotrek
Toulouse ou distanciel A la demande
Voir la Formation Administration et personnalisation de GeotrekFormations Django
Formation Django avancé
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation Django avancéActualités en lien
Créer une application en tant que composant web avec Stencil
Application Web & Mobile
04/04/2023
Développement de Geotrek Widget financé par le Parc Naturel Régional du Haut-Jura
Logiciel libre
28/03/2023
La segmentation dynamique
SIG
17/02/2014
Introduction au référencement linéaire et ses applications