Makina Blog
Déboguer des triggers SQL en cascade – Approche Matplotlib
La maintenance des triggers SQL devient un véritable défi technique lorsque la base de données évolue et que les interactions entre tables se multiplient.
Le défi : des triggers complexes en cascade
Les triggers SQL (ou déclencheurs) sont des procédures stockées qui s’exécutent automatiquement en réponse à certains événements (comme l’insertion, la modification ou la suppression de données). Ils permettent d’implémenter des règles métier et d’assurer l’intégrité des données directement au niveau de la base de données. Lorsque vous travaillez avec une base relationnelle comportant une grande quantité de triggers SQL, leur déclenchement en cascade peut engendrer des cycles de mises à jour qui, bien que logiques individuellement, deviennent rapidement difficiles à retracer dans leur ensemble.
Par exemple, une mise à jour sur une table peut provoquer des modifications sur plusieurs autres tables, enclenchant elles-mêmes des modifications sur la première table, rendant le suivi du flot d’exécution très complexe. Dans mon cas, j’ai besoin d’identifier la source d’une erreur apparaissant au sein d’un test unitaire en échec environ une exécution sur cinq, dans une application Django connectée à une base de données PostgreSQL.
L’Approche graphique : visualiser pour Comprendre
Collecte des données
La première étape consiste à capturer les informations sur l’exécution des différents triggers. J’ai créé une table dédiée à la collecte des dates d’exécution de chaque trigger, en renseignant également leur niveau de profondeur (la méthode pg_trigger_depth permettant de déterminer combien de triggers successifs ont déclenché l’exécution du trigger courant).
Création de la table :
CREATE TABLE IF NOT EXISTS trigger_timeline(
id SERIAL PRIMARY KEY,
trigger_name VARCHAR(100),
trigger_depth INTEGER,
created_at TIMESTAMP
);
Insertion du logging, à ajouter au début de chacun des triggers (en changeant la valeur 'trigger_name') sur toutes les tables impliquées dans le traitement :
INSERT INTO trigger_timeline (trigger_name, trigger_depth, created_at) VALUES ('trigger_name', pg_trigger_depth(), clock_timestamp());
Du côté du test unitaire à déboguer, il est désormais possible de récupérer les informations ainsi logguées juste après la ligne de code qui déclenche toute la cascade :
# Connect to database
from django.db import connection
cursor = connection.cursor()
# Remove database logging entries from last execution
cursor.execute("TRUNCATE trigger_timeline")
# This is the line I need to debug : this insertion launches all the triggers
PathFactory.create(geom=LineString(Point(700070, 6600000),
Point(700020, 6600050),
Point(700060, 6600090),
Point(700100, 6600050),
srid=settings.SRID))
# Extract logging information to a Python list, ensure it is sorted by timestamp
cursor.execute("SELECT * FROM trigger_timeline")
data = cursor.fetchall()
trigger_timeline = []
for _, trigger_name, trigger_depth, trigger_timestamp in data:
trigger_timeline.append(trigger_name, trigger_depth, trigger_timestamp)
sorted_trigger_timeline = sorted(trigger_timeline, key=lambda x: x[2])
print(f"{sorted_trigger_timeline=}")
J’obtiens en sortie une liste de la forme suivante, comprenant non moins de 160 valeurs :
sorted_trigger_timeline = [
('paths_snap_extremities', 1, datetime.datetime(2025, 1, 15, 9, 27, 0, 609516)),
('elevation_path_iu', 1, datetime.datetime(2025, 1, 15, 9, 27, 0, 611045)),
('paths_topology_intersect_split', 1, datetime.datetime(2025, 1, 15, 9, 27, 0, 611428)),
('paths_snap_extremities', 2, datetime.datetime(2025, 1, 15, 9, 27, 0, 612682)),
('elevation_path_iu', 2, datetime.datetime(2025, 1, 15, 9, 27, 0, 613426)),
('paths_topology_intersect_split', 2, datetime.datetime(2025, 1, 15, 9, 27, 0, 613676)),
('paths_snap_extremities', 3, datetime.datetime(2025, 1, 15, 9, 27, 0, 614584)),
('elevation_path_iu', 3, datetime.datetime(2025, 1, 15, 9, 27, 0, 615308)),
('paths_topology_intersect_split', 3, datetime.datetime(2025, 1, 15, 9, 27, 0, 615541)),
('update_topology_geom_when_path_changes', 3, datetime.datetime(2025, 1, 15, 9, 27, 0, 616272)),
...
]
Visualisation du flot d’exécution
Avec Matplotlib, j’ai transforme ces données en un graphique qui représente visuellement la cascade des triggers :
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime
def plot_trigger_timeline(data):
trigger_names = list(set(name for name, _, _ in data))
trigger_names.sort()
# Create color map for triggers
colors = [plt.cm.tab20(i / (len(trigger_names) - 1)) for i in range(len(trigger_names))]
color_map = dict(zip(trigger_names, colors))
# Create figure and axis with larger size
plt.figure(figsize=(15, 10))
# Plot points for each trigger type
for trigger in trigger_names:
# Filter data for this trigger
trigger_data = [(name, depth, time) for name, depth, time in data if name == trigger]
# Extract x and y coordinates
times = [t for _, _, t in trigger_data]
depths = [depth for _, depth, _ in trigger_data]
# Plot scatter points
plt.scatter(times, depths, label=trigger, alpha=0.6, s=100, color=color_map[trigger])
# Customize the plot
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%H:%M:%S.%f'))
plt.gcf().autofmt_xdate() # Rotate and align the tick labels
# Add labels and title
plt.xlabel('Timestamp')
plt.ylabel('PG Depth')
plt.title('Trigger Events Timeline')
# Add legend to the right side of the plot
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
# Adjust layout to prevent label cutoff
plt.tight_layout()
return plt
# Create and display the plot
plt = plot_trigger_timeline(sorted_trigger_timeline)
plt.show()
Je relance mon tests unitaire, qui est en échec une fois sur 5, et trace le résultat dans le cas qui fonctionne, et dans le cas qui échoue, afin de les comparer :
Cas sans échec : exécution souhaitée
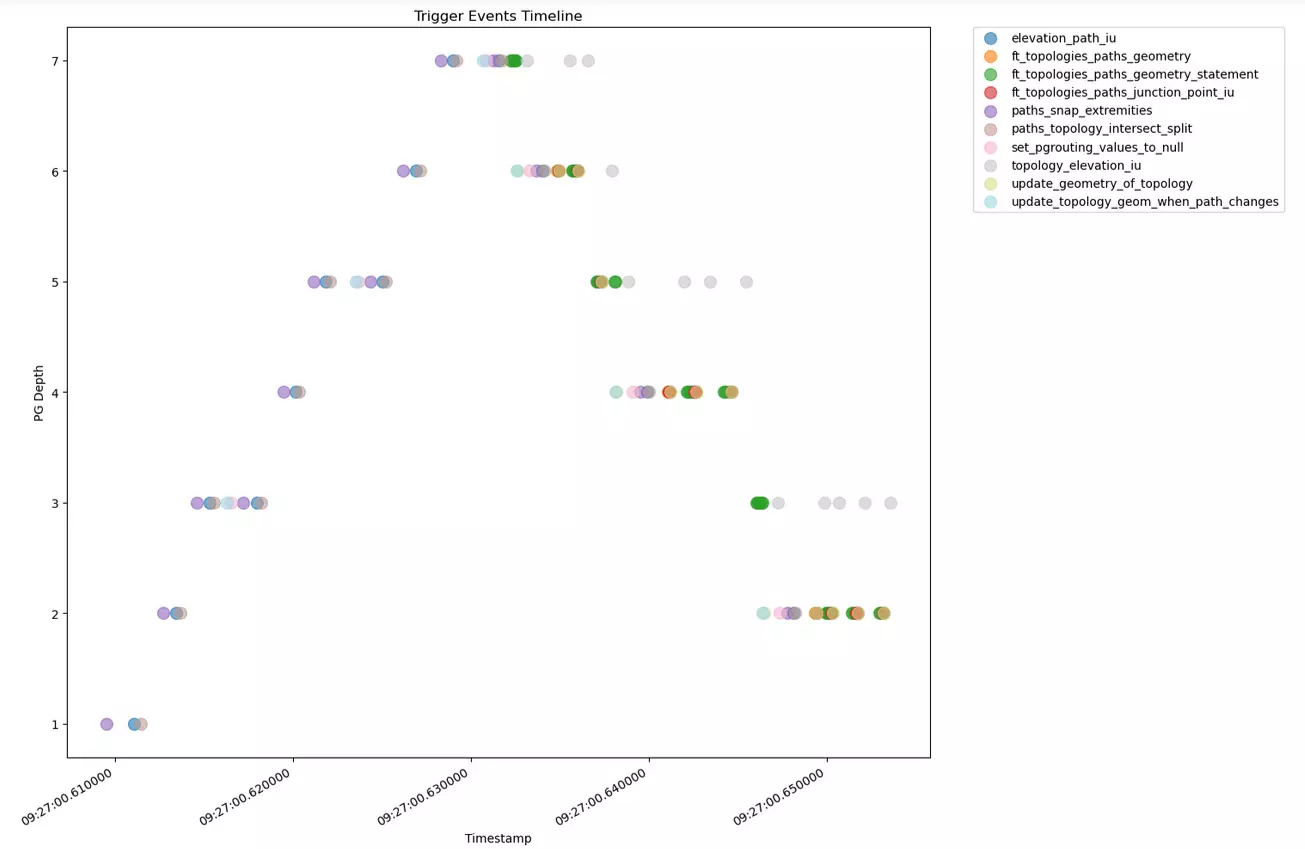
Cas en échec

À partir de ces représentations, je peux identifier deux choses :
Cette visualisation met en évidence la nature récursive des triggers que je suis en train d’explorer (forme pyramidale, avec des motifs qui se répètent, augmentant en profondeur jusqu’à atteindre la condition de sortie au sommet de la pyramide)
Je commence à identifier le point de départ de mon erreur finale, à l’endroit où la cascade commence à diverger de son exécution souhaitée.
Visualisation des insertions et mises à jour
Afin de corréler les exécutions de triggers avec les objets modifiés, je reproduis le même mécanisme pour logger les INSERT et UPDATE d’un objet dans la table concernée.
Je décide d’utiliser une seconde table de logging :
CREATE TABLE IF NOT EXISTS trigger_events(
id SERIAL PRIMARY KEY,
trigger_type VARCHAR(100),
path_id VARCHAR(100),
created_at TIMESTAMP,
tgr_depth INTEGER
);
Je crée 4 triggers destinés à logger uniquement le début « BEFORE » et la fin « AFTER » des évènements « INSERT » et « UPDATE » sur ma table de core_path :
CREATE FUNCTION public.log_after_trigger_update() RETURNS trigger SECURITY
DEFINER AS $$
DECLARE
BEGIN
insert into trigger_events (trigger_type, path_id, created_at, tgr_depth) VALUES('AFTER_UPDATE', NEW.id, clock_timestamp(), pg_trigger_depth());
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER log_after_trigger_tgr_update
AFTER UPDATE OF geom ON core_path
FOR EACH ROW EXECUTE PROCEDURE log_after_trigger_update();
CREATE FUNCTION public.log_before_trigger_update() RETURNS trigger SECURITY
DEFINER AS $$
DECLARE
BEGIN
insert into trigger_events (trigger_type, path_id, created_at, tgr_depth) VALUES('BEFORE_UPDATE', NEW.id, clock_timestamp(), pg_trigger_depth());
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER log_before_trigger_tgr_update
BEFORE UPDATE OF geom ON core_path
FOR EACH ROW EXECUTE PROCEDURE log_before_trigger_update();
CREATE FUNCTION public.log_after_trigger_insert() RETURNS trigger SECURITY
DEFINER AS $$
DECLARE
BEGIN
insert into trigger_events (trigger_type, path_id, created_at, tgr_depth) VALUES('AFTER_INSERT', NEW.id, clock_timestamp(), pg_trigger_depth());
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER log_after_trigger_tgr_insert
AFTER INSERT ON core_path
FOR EACH ROW EXECUTE PROCEDURE log_after_trigger_insert();
CREATE FUNCTION public.log_before_trigger_insert() RETURNS trigger SECURITY
DEFINER AS $$
DECLARE
BEGIN
insert into trigger_events (trigger_type, path_id, created_at, tgr_depth) VALUES('BEFORE_INSERT', NEW.id, clock_timestamp(), pg_trigger_depth());
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER log_before_trigger_tgr_insert
BEFORE INSERT ON core_path
FOR EACH ROW EXECUTE PROCEDURE log_before_trigger_insert();
Je reproduis le même principe du côté de mon test unitaire :
# Connect to database
from django.db import connection
cursor = connection.cursor()
# Remove database logging entries from last execution
cursor.execute("TRUNCATE trigger_events")
# This is the line I need to debug : this insertion launches all the triggers
PathFactory.create(geom=LineString(Point(700070, 6600000),
Point(700020, 6600050),
Point(700060, 6600090),
Point(700100, 6600050),
srid=settings.SRID))
# Extract logging information to 4 Python lists, ensure they are sorted by timestamp
cursor.execute("SELECT * FROM trigger_events")
data = cursor.fetchall()
before_update = []
after_update = []
before_insert = []
after_insert = []
for _, trg_type, pk, date, tgr_depth in data:
if trg_type == "BEFORE_INSERT":
before_insert.append((pk, tgr_depth, date))
elif trg_type == "AFTER_INSERT":
after_insert.append((pk, tgr_depth, date))
elif trg_type == "BEFORE_UPDATE":
before_update.append((pk, tgr_depth, date))
elif trg_type == "AFTER_UPDATE":
after_update.append((pk, tgr_depth, date))
sorted_before_update = sorted(before_update, key=lambda x: x[1])
sorted_after_update = sorted(after_update, key=lambda x: x[1])
sorted_before_insert = sorted(before_insert, key=lambda x: x[1])
sorted_after_insert = sorted(after_insert, key=lambda x: x[1])
J’obtiens en sortie des listes de la forme suivante, me permettant de retracer les objets impactés par la cascade de triggers :
before_update = [
('207', 2, datetime.datetime(2025, 1, 21, 13, 23, 42, 254063)),
('211', 3, datetime.datetime(2025, 1, 21, 13, 23, 42, 256176)),
...
]
after_update = [
('207', 2, datetime.datetime(2025, 1, 21, 13, 23, 42, 255288)),
('211', 3, datetime.datetime(2025, 1, 21, 13, 23, 42, 257131)),
...
]
before_insert = [
('211', 1, datetime.datetime(2025, 1, 21, 13, 23, 42, 250029)),
('217', 2, datetime.datetime(2025, 1, 21, 13, 23, 42, 284971)),
...
]
after_insert = [
('211', 1, datetime.datetime(2025, 1, 21, 13, 23, 42, 252373)),
('217', 2, datetime.datetime(2025, 1, 21, 13, 23, 42, 285437)),
...
]
Voici un second script Matplotlib, pour les représenter sur le même graphe :
import matplotlib.pyplot as plt
import datetime
def plot_trigger_timeline_paths(data, legend, ytext, color, create_new_figure=True):
# Extract data for plotting
identifiers = [item[0] for item in data]
depths = [item[1] for item in data]
timestamps = [item[2] for item in data]
# Create the plot only if it's the first dataset
if create_new_figure:
plt.figure(figsize=(10, 6))
# Plot points
plt.scatter(timestamps, depths, color=color, label=legend)
# Add labels for each point
for i, txt in enumerate(identifiers):
plt.annotate(txt, (timestamps[i], depths[i]),
xytext=(5, ytext), textcoords='offset points')
# Customize the plot (only needed once)
if create_new_figure:
plt.xlabel('Timestamp')
plt.ylabel('PG Depth')
plt.title('PG Depth vs Timestamp')
# Format x-axis to show time nicely
plt.gcf().autofmt_xdate()
# Add grid for better readability
plt.grid(True, linestyle='--', alpha=0.7)
return plt
# Plot the first dataset (creates the figure)
plt = plot_trigger_timeline_paths(before_update, 'before_update', 5, 'pink', create_new_figure=True)
# Plot the second dataset (adds to existing figure)
plt = plot_trigger_timeline_paths(before_insert, 'before_insert', 5, 'green', create_new_figure=False)
plt = plot_trigger_timeline_paths(after_insert, 'after_insert', -15, 'blue', create_new_figure=False)
plt = plot_trigger_timeline_paths(after_update, 'after_update', -15, 'red', create_new_figure=False)
# Add legend
plt.legend()
# Adjust layout to prevent label cutoff (do this only once at the end)
plt.tight_layout()
# Show the plot
plt.show()
Cas sans échec : exécution souhaitée
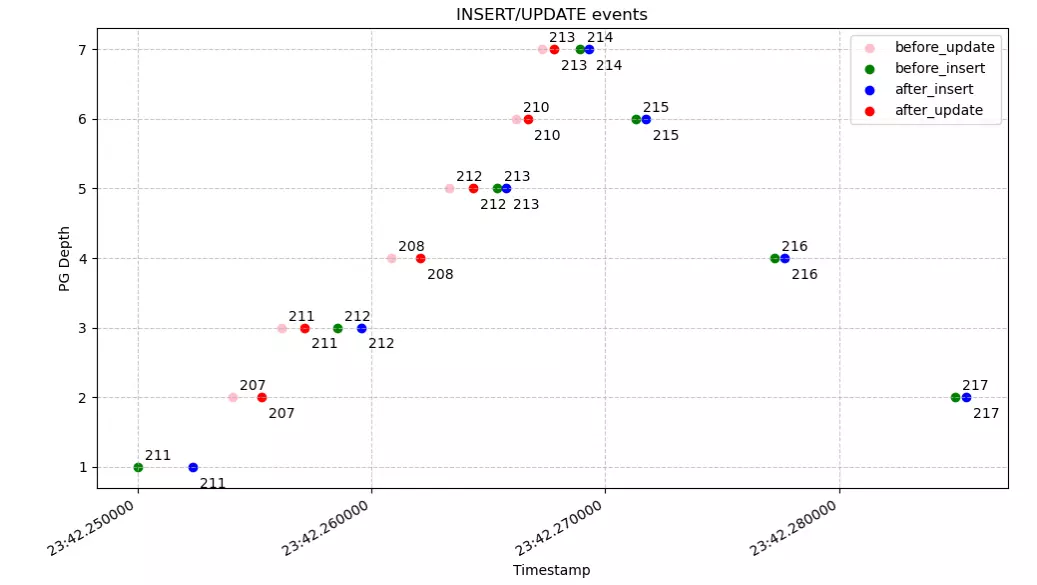
Cas en échec
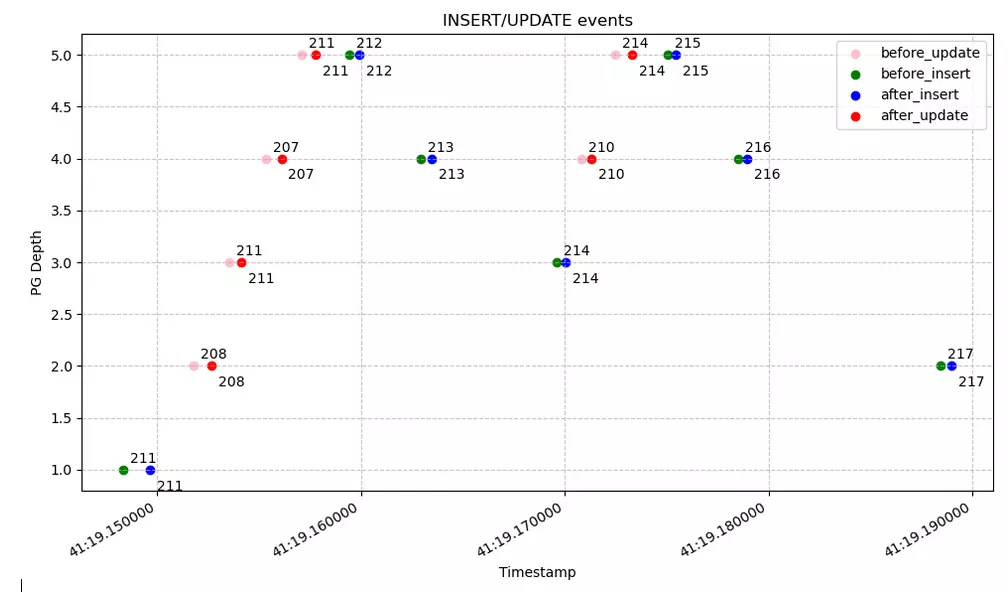
Ces représentations :
- Soulignent davantage le motif pyramidal de la récursion, ainsi que la divergence du flot d’exécution dans le cas qui échoue (pyramide brisée en deux)
- Me permettent d’identifier le point de départ de la divergence des exécutions (l’objet numéro 208 a été modifié avant l’objet numéro 207).
À partir de ces constats, et en réutilisant le même concept pour logger l’exécution de quelques lignes précises de SQL au sein des triggers, je réussis rapidement à retrouver la ligne responsable de l’erreur : le trigger paths_topology_intersect_split itère via une boucle FOR sur le résultat d’un SELECT dont la clause manquait d’un ORDER BY, ne garantissant donc pas l’ordre dans lequel on itère sur les objets. Ceci explique que le test unitaire était en erreur une fois sur cinq seulement.
Conclusion
En créant une représentation visuelle de l’exécution des triggers SQL, j’ai pu gagner en clarté et en compréhension. La visualisation m’a permis de :
- Prendre connaissance de l’ordre d’exécution des triggers
- M’orienter vers la source de l’erreur sans connaître l’intégralité du code SQL
- Affiner progressivement ma recherche en croisant différentes informations
J’ai pu produire un outil réutilisable par mon équipe pour explorer des problèmes similaires à l’avenir.
Cette expérience souligne un aspect fondamental des triggers SQL : leur nature événementielle et leur capacité à s’enchaîner peuvent faire de leur maintenance un casse-tête. Faire l’inventaire des opérations déclenchant les triggers est déjà un exercice chronophage, et garder la visibilité sur les opérations causées par ceux-ci est un véritable défi. Soulignons l’importance d’utiliser les triggers avec parcimonie, en privilégiant des opérations simples via des procédures courtes. Je recommande d’éviter la mise en place de triggers récursifs impactant eux-mêmes la colonne qui les déclenche en premier lieu. Attention également à la nature non-déterministe de la clause SELECT.

Python-Django-SSI
Formations associées
Formations Outils et bases de données
Formation PostgreSQL
Nantes Du 8 au 10 septembre 2026
Voir la Formation PostgreSQLFormations Python
Formation Python avancé
A distance (FOAD) Du 14 au 18 septembre 2026
Voir la Formation Python avancéActualités en lien
Utiliser des fonctions PostgreSQL dans des contraintes Django
Django
07/11/2023

Créer des vues SQL dans Django et les afficher dans un SIG
Django
06/09/2022
Nous allons décrire un processus via la mise en place de vues SQL qui permettent à l'utilisateur de lire de la donnée formatée, sans possibilité d'influer sur le contenu d'une base et tout en se connectant directement à celle-ci.

Améliorez votre SQL : utilisez des index filtrés
DevOps
29/08/2019
L'indexation d'une base de données est un vaste sujet, dans cet article nous examinerons une possibilité offerte par PostgreSQL dans les index et le filtrage de l'index pour qu'il ne s'applique pas à toute la table.
