Makina Blog
SEO et indexation de site : théorie et pratique
Transcription de ma conférence donnée à la conférence Codeurs en Seine à Rouen en novembre 2016.
Tout le monde connaît le fameux "tryptique du SEO" : technique, contenu et popularité. L'objectif de la partie technique est de permettre la meilleure indexation possible du contenu du site. Nous allons voir dans cet article les différents enjeux de cette indexation de site.
Un peu d'histoire
Plusieurs millions de pages web sont publiées chaque jour. Google doit nécessairement prioriser certaines indexations par rapport à d'autres. Notre travail est de l'y aider…
Il y a 15 ans, il fallait essayer de se référencer. Depuis, les systèmes de gestion de contenu (comme Drupal ou Plone) sont apparus, et ont pris en charge une partie de la charge technique du référenceur (en bien ou en mal, d'ailleurs). On constate cependant qu'il est aujourd'hui souvent plus facile de faire indexer un site.
D'ailleurs, il n'est pas rare de voir indexées les plate-formes de pré-production, les pages de test, les pages inutiles de ces sites construits avec des CMS, parce que les pré-requis techniques de base sont remplis.
L'objectif aujourd'hui est plutôt de se différencier en guidant et canalisant le parcours des robots d'indexation sur le site.
Les bases de la technique
La principale façon de contrôler le parcours des robots sur le site est d'utiliser 2 fichiers bien connus même par les débutants en référencement :
Le fichier robots.txt
Ce fichier permet d'interdire aux robots de visiter des pages de votre site, en utilisant la syntaxe suivante (qui interdira tout votre site aux robots) :
User-agent: * Disallow: /
Vous pouvez consulter une syntaxe plus complète sur http://www.robotstxt.org/robotstxt.html. Certaines syntaxes sont propres à Googlebot, d'autres comprises par tous les robots.
Attention, ce fichier NE contrôle PAS directement l'indexation : si de nombreux liens pointent vers une page de votre site que le robot ne peut pas visiter, il est tout de même possible que Google l'indexe en se basant sur les informations du lien (notamment le texte du lien). Vous aurez alors le message suivant dans les résultats de recherche :
La description de ce résultat n'est pas disponible en raison du fichier robots.txt de ce site.
Note : on trouve la mention de l'utilisation de la directive NOINDEX directement dans le robots.txt, mais ce n'est clairement pas la solution la plus utilisée pour gérer l'indexation.
Le fichier sitemap.xml
Ce fichier constitue un plan du site et permet d'indiquer aux moteurs les pages que vous souhaitez voir crawler. Une fois ce fichier constitué correctement, il est possible de le soumettre dans les outils pour webmestre des différents moteurs (Google Search Console, Bing Webmaster Tools, …).
Je ne suis pas forcément très enthousiaste sur ce fichiers, dont l'importance pour des petits sites ne se justifie pas spécialement ou uniquement si votre site est mal construit, ce qui vous posera de toute façon d'autres problèmes ;-). Les robots (notamment celui de Google) sont plutôt efficaces sur ces petits sites.
Par contre, le fichier sitemap.xml se justifie pleinement pour les gros sites ou indiquer les pages que l'on souhaite voir crawler en priorité peut prendre une toute autre importance.
Un autre cas où se fichier est très important est pour les sites réalisés avec des frameworks Javascript et où Google est parfois incapable de parcourir seul la liste intégrale des URLs importantes du site. Le fichier sitemap.xml permettra alors de lui indiquer une liste d'URLs à parcourir, et d'augmenter ainsi considérablement les possibilités de voir votre site indexé.
Il est fondamental d'éviter à tout prix une sitemap incorrecte (doublons, urls non-existantes, …) pour ne surtout pas donner de mauvais signaux aux robots d'indexation.
Le fonctionnement du crawl (la théorie)
Le crawl est le terme par lequel on désigne le parcours des robots sur le site. Son fonctionnement est plutôt simple : le robot récupère par un moyen ou un autre une URL (un lien sur un autre site, l'ouverture de la page dans Chrome, …), il visite cette page, parcours son code HTML, détecte tous les liens (ou potentiellement tout ce qui ressemble à une URL), les met dans une liste… et continue alors avec la prochaine page de sa liste.
Simulation d'un crawl
La première étape d'audit technique [LIEN] d'un site est donc de simuler le passage du robot sur le site. De nombreux logiciels permettent de faire ça :
- ScreamingFrog SEO Spider, qui n'est pas un logiciel libre (gratuit pour les crawls de moins de 500 pages), mais a l'avantage de tourner sous Linux. C'est probablement le plus utilisé dans le monde du référencement aujourd'hui ;
- BeamUsUp, gratuit ;
- Botify (Saas), la startup (française) qui monte ;
- Oncrawl (Saas), qui couvre le même domaine que Botify ;
- Cocon.Se (Saas), français et prometteur ;
- Ou vous pouvez développer le vôtre, en Python, par exemple, les bibliothèques ou produits Open Source sont nombreux.
Vous constatez que beaucoup de sociétés se développement dans ce domaine, c'est l'ère de l'exploitation massive de données pour le référencement. Les plateformes en Saas deviennent incontournables dès que les sites augmentent en taille, catégorie de référenceurs qu'on appelle les "SEO Enterprise".
Résultats du crawl
On obtient alors la liste des URLs du site (qui peut parfois nous surprendre, car au bout d'un certain temps, on oublie des pages, on connaît finalement assez mal son site). On obtient de plus des statistiques sur les balises TITLE, META description, H1, H2, canonical, … ainsi que la liste des liens internes de notre site.
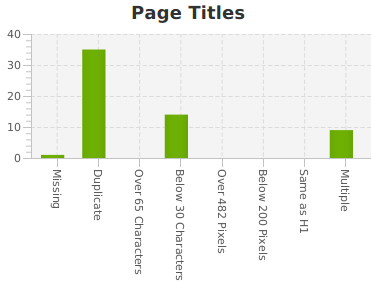
Ici, on constate que certaines pages ont plusieurs balises TITLE, et surtout que de nombreuses pages ont un titre identique : c'est parce que le site a une édition annuelle, et que l'année ne figure pas dans le TITLE des pages (lors d'un audit, nous pourrions suggérer de corriger ça).
Nous obtenons également d'autres informations comme la profondeur moyenne du site, la performance, …
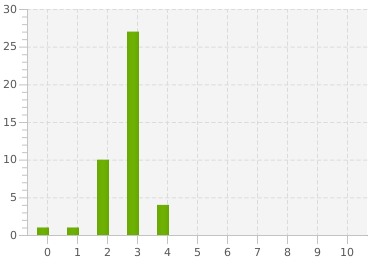 Profondeur des pages du site "Codeurs en Seine"
Profondeur des pages du site "Codeurs en Seine"
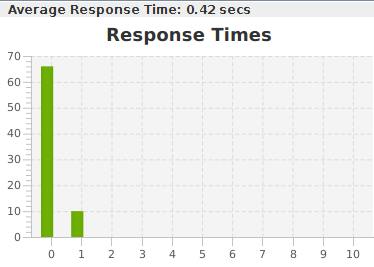 Performance des pages du site "Codeurs en Seine"
Performance des pages du site "Codeurs en Seine"
Exploitation des résultats
Pour mieux comprendre la structure interne du site, nous utilisons le logiciel open-source Gephi qui représente graphiquement les relations d'un réseau d'éléments. Ici, les éléments sont les pages de votre site, et nous cherchons à mettre en valeur les liens internes entre ces pages.
De plus, Gephi permet d'utiliser des algorithmes mathématiques, comme le Page Rank pour évaluer l'importance relative des pages ou la modularité pour évaluer leur proximité.
Analyse de structure
Nous avons déjà parlé dans un article précédent de l'analyse de structure d'un site avec Gephi. Nous expliquons également la méthodologie pour réaliser ce genre de graphe dans un autre article.
Voici le rendu pour le site de Codeurs en Seine :
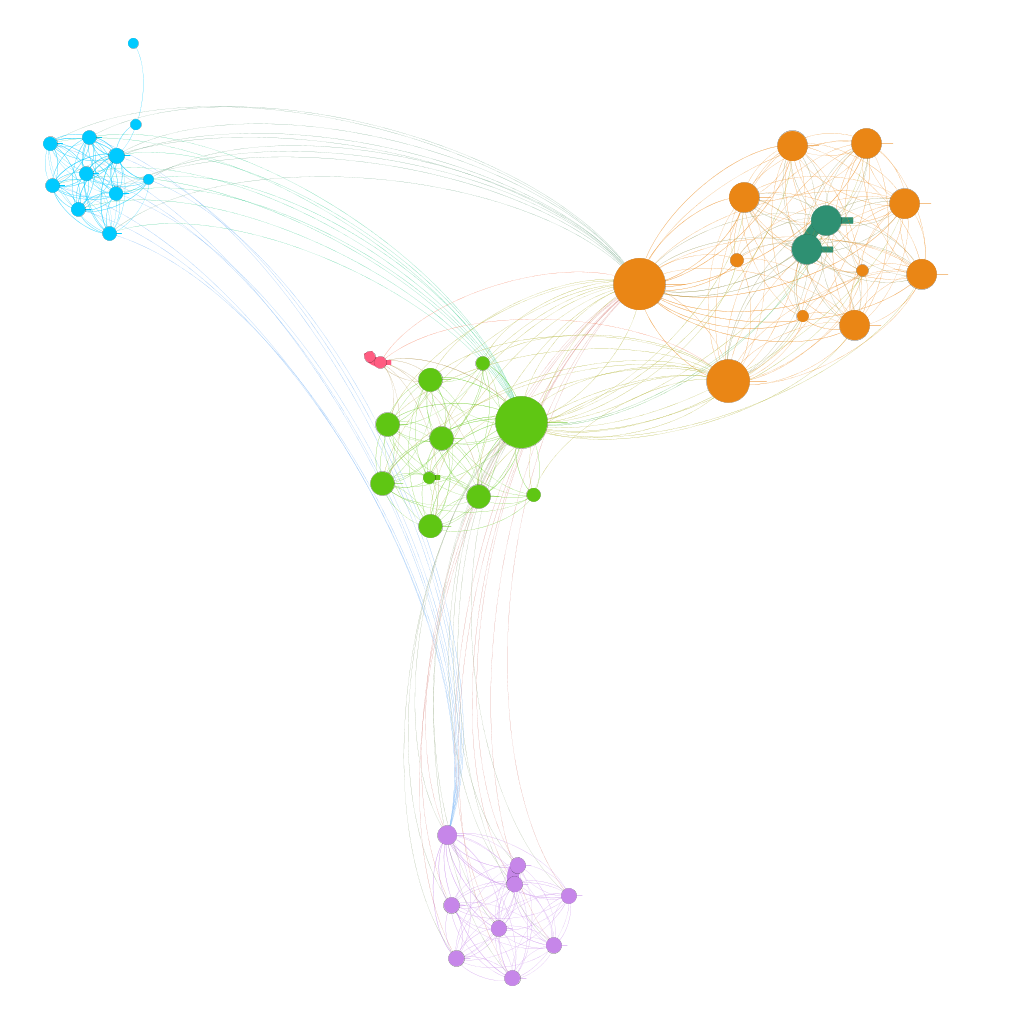
On distingue bien les silos (chaque "grappe" colorée) formés par chaque année, plutôt indépendants les uns des autres (bien séparés géographiquement, les couleurs étant elle-mêmes bien isolées). C'est ce résultat que l'on visera pour une identification optimale de nos silos par les moteurs.
Détection d'anomalies
Mais nous pouvons également nous en servir pour détecter des anomalies plus rapidement qu'en passant sur chaque URL du site une par une (surtout sur les gros sites).
Par exemple, sur le site d'un de mes clients, j'ai observé le rendu graphique suivant (la taille du point indique le Page Rank interne de la page, la couleur son coefficient de modularité) :
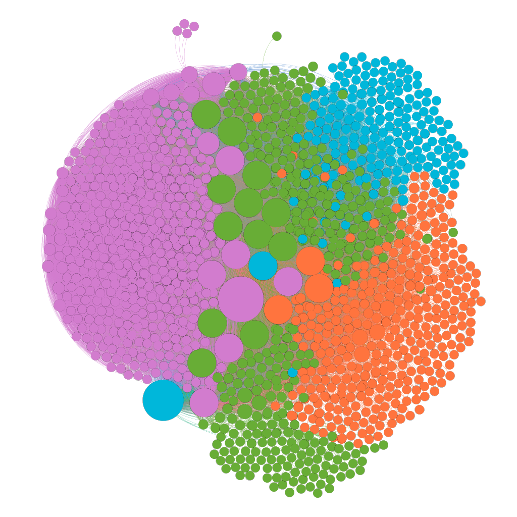
On observe directement que le site semble comporter 4 parties… alors qu'il n'en comporte réellement que 3. Intrigué par cette anomalie, j'ai constaté que l'ensemble des URLs de la partie violette (la "tumeur" sur la partie gauche de l'image) provenait du calendrier de la page d'accueil :

Sur ce calendrier, on peut en effet remonter ou avancer de mois en mois, d'année en année, sans limite de date… C'est ce qu'on appelle un spider trap (un piège à robots de moteurs de recherche). Vous rencontrerez le même problème avec les paginations infinies, les filtres à facettes multiples dont l'ordre des paramètres n'est pas toujours le même, …
Dans la mesure où ce calendrier était sur la page d'accueil, page ici la plus importante du site, Google parcourt consciencieusement les liens les uns après les autres. Je constatai d'ailleurs dans mon analyse qu'il était remonté jusqu'en 1356 et est allé jusqu'en 2300… Sacré Google, rien ne l'arrête !
Alors que tout ce temps de parcours du site aurait avantageusement pu être consacré à de "vraies" pages du site, plus intéressantes pour les visiteurs… et d'ailleurs :
Le budget de crawl
Combien de pages Google peut crawler par jour SUR VOTRE SITE ? Google se fixe une limite de pages à parcourir chaque jour sur votre site. Bien sûr, cela dépend de la popularité des pages et plus globalement de celles de votre site, mais celà dépend aussi tout simplement de la performance de votre site : c'est ce que google appelle le Host load : à quel point peut-il charger votre site ?
On essaiera donc d'améliorer au maximum la performance du site, pas pour être mieux placé dans les résultats de recherche, mais pour que Google puisse parcourir chaque jour plus de pages, et prendre en compte toutes les modifications que vous faites sur votre site.
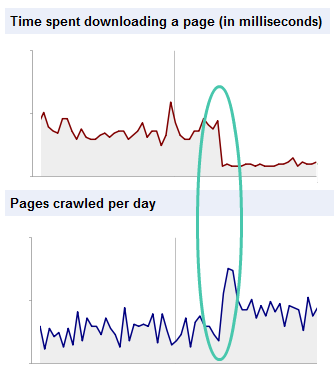
Dans mes tests, il faut viser 400ms, voir moins, de temps de réponse pour l'HTML du site. Cela provoquera une forte hausse du nombre de pages visitées par les robots (voir ce graphique issu d'un article de Botify) :
Comment contrôler ?
Vous pouvez vérifier un peu ce que fait Google en utilisant la Search Console et son rapport Crawl stats :
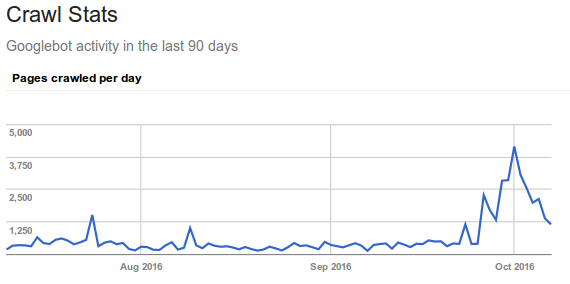
Attention, ce nombre contient tous les fichiers de votre site (y compris CSS, JS, PDF, …) et représente le parcours de l'ensemble des robots de Google : GoogleBot, GoogleNews, Google Mobile, ainsi que tous les codes retours (301, 200, 404, …). Il faut donc aller plus loin !
Analyse de logs (la pratique)
Un des aspects techniques qui se développement énormément depuis 2014 est l'analyse des logs de votre site. On utilise là encore souvent des outils existants :
- Screaming Frog Log File Analyser ;
- Botify et Oncrawl (Saas) à nouveau ;
- Loggly (Saas) ;
- Ou tout simplement la Watussi Box que les français connaissent bien ;
- Et probablement d'autres encore (dont notamment depuis novembre 2016 un analyseur de logs Open Source, basé sur Elasticsearch - Logstash - Kibana et issu de la Toolbox Oncrawl).
On obtient alors la liste des URLs parcourues par les robots, en fonction des dates :
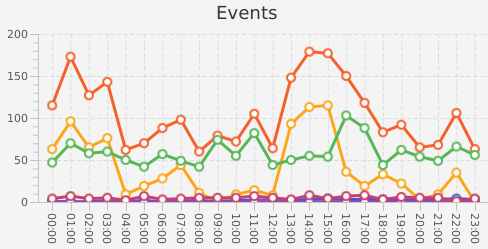
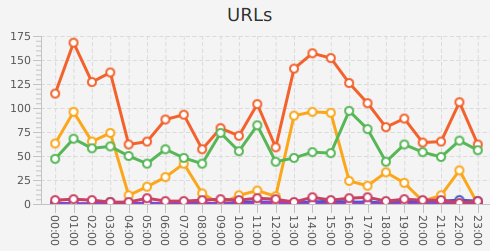
Ici, les events représentent le nombre de visites des robots, les urls le nombre d'URLs parcourues, on constate que les robots parcourent certaines URLs plusieurs fois par jour, les events étant supérieurs aux urls. Les couleurs indiquent les différents robots (GoogleBot, BingBot, GoogleNews, GoogleMobile, Baidu, …).
Détection d'anomalies
Il est alors possible de croiser les données avec le crawl pour détecter les URLs non parcourues, les URLs parcourues alors qu'elles n'existent pas, … (pages 404 crawlées souvent parce qu'elles ont beaucoup de popularité en tant qu'urls d'un ancien site non redirigées). Bien sûr, on s'attachera à corriger ces problèmes techniques.
Fréquences de crawl
Mais on peut également utiliser ces logs pour identifier à quelle "couche" de votre site chaque page appartient. En gros, Google distingue essentiellement 3 couches :
- "Temps réel" (il crawle la page plusieurs fois par jour) ;
- "Quotidien" (il parcourt la page 1 fois par jour) ;
- et le reste… découpé également en plusieurs sous-segments (à commencer par les pages "actives" et les pages "inactives", les pages "actives" représentant les pages qui occasionnent des visites en provenance des résultats de recherche).
Les pages de votre site bougent entre ces couches au gré de vos changements sur ces pages.
Le travail commence
À partir de ces logs, il est possible d'identifier dans quelle couche sont les URLs de votre site, c'est-à-dire l'importance relative que Google accorde à ces URLs.
À vous de nettoyer ce qui traîne, également (par exemple les 404s crawlées régulièrement, à rediriger si possible vers une page équivalente).
Plutôt pour les gros sites
"I have never seen and never worked with a large site where improving crawl bandwidth didn’t mean significant increases in organic search traffic" (dans un article de Rand Fishkin).
Le gain sera plus important / visible sur les gros sites, même si tout site devrait pouvoir bénéficier de ces techniques.
L'indexation
Nous avons vu les mécanismes liés au crawl, mais quid de l'indexation ?
La théorie
Tout ce qui est crawlé est indexé.
La pratique
Déjà… tout N'est PAS crawlé… et au niveau de l'indexation, Google choisit les pages qu'il estime mériter d'être dans son index.
Par exemple (en prenant un autre site que les sites mentionnés précédemment), on peut consulter le nombre de pages indexées dans la Search Console de Google ("Index status") :

Ou directement sur Google, avec la commande site:domain :

Note : les 2 captures ont été prises à des moments différents de la vie du site).
Mais… Google sépare les pages en 2 indexes : le "primaire" et le "secondaire". Il est possible d'en avoir un aperçu rapide en essayant d'aller le plus loin possible dans les pages de résultats de la commande précédente. Au bout d'un moment, Google affiche un message similaire à celui-ci :

Ici, sur 2050 pages, Google considère que 500 seulement sont dignes d'intérêt, les autres comprenant trop de contenu similaire, ou du moins pas assez de contenu permettant de les différencier les unes des autres. La question qui se pose alors est directement : "est-ce que vos visiteurs font la différence, eux ?" Parce qu'avec 1/4 des pages du site seulement intéressantes… Il est temps de faire quelque chose, non ?
Alors, comment contrôle-t-on l'indexation ?
On ne peut pas décider d'être dans l'index primaire ou secondaire, seule la qualité et la popularité de nos pages décident de ça. Par contre, on peut empêcher Google d'indexer des pages que l'on juge "inutiles" (parce qu'avec un contenu non destiné à se positionner dans les moteurs de recherche, uniquement pour les visiteurs). Dans ce cas, on utilise la balise META robots sur la page en question : <META name="robots" value="NOINDEX">.
Conclusion
On dispose de nombreux outils pour nous fournir quantité de données sur l'indexation de notre site. Toutes ces données peuvent déboucher sur des analyses différentes, selon les sites, leur structure, leur contenu, leur support technique, … Mais dans tous les cas, vous trouverez des choses à améliorer sur votre site ;-)
Pour aller plus loin
Voici les articles qui ont inspiré cette conférence et vous permettront de développer un peu les sujets abordés ici :
Vérifiez si votre site est correctement indexable et indexé par les moteurs
N'hésitez plus, demandez-nous un audit !

Drupal - SEO
Formations associées
Formation Matomo
Formation Matomo : migration Google Analytics vers Matomo
Toulouse ou distanciel A la demande
Voir la Formation Matomo : migration Google Analytics vers MatomoActualités en lien
Matomo, l'alternative open source à Google Analytics
Logiciel libre
16/02/2022
Le 10 février 2022, la CNIL a mis en demeure un gestionnaire de sites web qui utilise Google Analytics. Nous vous proposons ici des alternatives Open Source parmis lesquelles Matomo, l'outil de mesure d'audience que nous utilisons sur notre site makina-corpus.com !

Démystifions le référencement
Data Science
15/06/2016
Une présentation du SEO pour les développeurs qui n'y croient pas.

SEO : introduction technique au référencement
Data Science
30/11/2015
Le référencement (ou Search Engine Optimization) est un (très) vaste sujet. Voici une introduction à sa partie technique.
