Makina Blog
Initiation au Machine Learning avec Python - La théorie
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette première partie se veut non technique et présente les concepts du Machine Learning, les différents types d'apprentissage et leurs principaux algorithmes. Il situe enfin Python dans cet univers en présentant les nombreuses librairies à votre disposition pour aborder cette discipline.
Introduction
Cet article est la première partie d'un cours sur l'apprentissage automatique avec Python.
Dans cette première partie tente de vous offrir une vision des différents domaines de l'intelligence artificielle et comment Python s'y distingue.
Elle poursuit sur une présentation détaillée de l'apprentissage automatique qui représente aujourd'hui très certainement la branche la plus active de cette discipline au point d'être sur les lèvres de toutes les grandes entreprises.
Nous allons essayer d'en poser les fondations pour vous aider à en saisir la vue globale, la fameuse « big picture », ce qui vous aidera à choisir au mieux vos algorithmes et librairies.
Nous présenterons :
- En quoi Python est bien disposé pour faire de l'IA
- Un rapide historique de l'IA
- L'apprentissage automatique, ses domaines et principaux algorithmes
Quelles sont les qualités d'un langage pour l'IA et pourquoi utiliser Python ?
Python, en tant que langage seul, n'est pas spécialement plus adapté que les autres langages pour faire de l'IA.
Wikipédia, dans sa version anglaise, présente une page décrivant les langages les plus utilisés pour l'IA. On y retrouve Python, mais pas pour ses qualités internes.
Pour l'IA il est surtout utile que le langage permette :
- La « récursivité »
Aujourd'hui quasiment tous les langages le permettent, seuls les langages non procéduraux, comme les vieux BASIC des TO8 n'offrant pas la notion de fonction sont dépourvus de cette capacité.
Toutefois, les optimisations de type tail call ne sont pas disponibles en Python. - La programmation orientée objets
Là encore, la plupart des langages modernes couramment utilisés en disposent. Python offre toute la mécanique requise: héritage, surcharge, méthodes virtuelles ; même s'il est moins rigoureux que d'autres (pas de visibilité private/public/protected). - Le paradigme fonctionnel
Python permet ce paradigme de programmation même s'il est moins "naturel" que dans d'autres langages comme Haskell, Lisp ou Erlang. - Des fonctionnalités de programmation logique, telle la logique des prédicats utilisée par PROLOG.
Python n'offre rien de tel en natif.
Clairement, Python n'est pas vraiment au dessus des autres langages pour l'intelligence artificielle. Mais il s'y prête bien et sa syntaxe concise et facile permet d'y progresser très certainement plus aisément que dans d'autres langages.
Il dispose aussi de quelques librairies spécialisées en IA qui lui permettent de s'initier à cette discipline.
En outre, concernant le machine learning, la problématique la plus difficile est souvent de disposer de bons jeux de données - et cela va parfois bien au delà du besoin de savoir implémenter ou utiliser correctement un algorithme d'apprentissage automatique. Sur ce plan, Python est particulièrement bien outillé avec des librairies comme Numpy ou Pandas, par exemple.
Enfin, concernant le domaine de l'apprentissage automatique Python se distingue tout particulièrement en offrant une pléthore de librairies de très grande qualité, couvrant tous les types d'apprentissages disponibles sur le marché ; le tout, accompagné d'une grande et dynamique communauté.
Par exemple, le projet Scikit-Learn qui est un des plus réputés pour cette discipline compte près de 800 contributeurs.
C'est énorme !
Imaginez une équipe de 800 développeurs. Peu de sociétés et de projets informatiques peuvent se comparer à ce nombre. Mais il faut relativiser, ils sont loin de tous y travailler à plein temps.
Intelligence Artificielle
Le site Wikipédia propose un excellent article sur l'histoire de l'intelligence artificielle relatant les grandes dates, sociétés et mouvements de pensées ayant contribué à son développement.

L'intelligence artificielle a trouvé son nom à la conférence de Dartmouth en 1956. Mais elle a débuté dès le début des années 1950 avec, notamment, les travaux d'Alan Turing qui s'est posé la question de savoir si l'on pouvait faire penser un ordinateur.
Il proposa pour cela un test, dit, test de Turing, dans lequel une personne discute au travers d'un ordinateur et doit deviner si son interlocuteur est une machine ou un être humain.
Si elle n'y arrive pas, l'on pourra conclure qu'il est possible de faire fonctionner un ordinateur avec des algorithmes de logique semblables à notre manière de penser, voire la dépassant.
Vous trouverez ci-dessous des exemples de programmes de ce genre :
- ELIZA et son implémentation en Python
- A.L.I.C.E bot
S'il y a encore quelques années il était très facile de deviner qu'une machine nous parlait, aujourd'hui nous arrivons au niveau du dernier point, voire au delà. En effet, dans plusieurs activités nécessitant beaucoup de rélexion, l'ordinateur s'est montré plus fort que l'être humain, comme avec:
- La victoire en 1997 aux échecs du programme Deep Blue d’IBM contre le champion du monde Garry Kasparov
- Le jeu de Go, où le programme AlphaGo de Google a battu le champion du monde Lee SeDol en 2016
- Le passage, contesté toutefois, du test de Turing par le programme Eugene Goostman
- La conduite automobile où les voitures sans chauffeur semblent plus sûres que celles conduites par des humains
- Et quelques autres…
L'intelligence artificielle a suscité et continue toujours de susciter de nombreux espoirs pour l'amélioration de notre condition humaine, mais le fait qu'elle arrive aujourd'hui dans certains domaines à nous égaler, voire à nous dépasser, suscite de nombreuses inquiétudes notamment auprès des plus grands dirigeants informatique de cette planète.
La page de Wikipédia consacrée à la discipline résume très bien ces craintes et espoirs à propos de l'IA.
Mais ceci reste un autre débat.
Algorithmes et techniques
L'IA a connu ses débuts en informatique avec les systèmes automates, la récursivé et des langages comme Lisp et Prolog.
Dans ses premiers jours l'on parlait surtout de règles logiques, de récursivité, d'analyse syntaxique, de graphes, et systèmes experts
Aujourd'hui les techniques mises en oeuvre pour faire réfléchir nos machines sont multiples:
- Logique floue
- Algorithme génétiques
- Data mining
- Inférence bayésienne
- Agents intelligents
- Réseaux de neuronnes
- Apprentissage automatique
Mais actuellement, en 2017, ce sont l'apprentissage automatique et plus particulièrement les réseaux de neurones et le deep learning qui tirent ce domaine vers le haut.
En effet, l'IA a végété plusieurs années à plusieurs reprises notamment dans les années 1970 et 1990 ; car elle a été longtemps limitée par les coûts et performances des machines (vitesse, capacité mémoire, capacité de stockage) qui ont miné les espérances qui y avaient été placées, engendrant frustrations et reculs des investissements par les industriels.
Aujourd'hui les superordinateurs et le cloud ont aboli ces limites et nous assistons à une explosion de ses possibilités qui semblent inarrêtables.
Les grappes de serveurs OVH, Amazon AWS et Google cloud accessibles avec le budget d'un particulier en sont un très bon exemple.
Nous pouvons de nos jours lancer des calculs complexes et analyser des milliards de données pour des coût dérisoires. Cela dope la recherche et donne son envol à l'intelligence artificielle.
Cela ouvre les voies au Machine learning qui prend toute sa dimension avec des très grands volumes de données. L'arrivée du Big Data a ainsi propulsé un nouveau domaine de l'IA : l'apprentissage automatique.
Et celui-ci, donne déjà de fabuleux résultats qui dopent tous les investissements du secteur !
Centres de recherches, banques, assurances, finance, aérospatiale, automobile, pharmacie… Toute l'industrie s'en empare.
"Google’s self-driving cars and robots get a lot of press, but the company’s real future is in machine learning, the technology that enables computers to get smarter and more personal." - Eric Schmidt (Google Chairman)
Des disciplines extrêmement compliquées et coûteuses comme la reconnaissance vocale, la reconnaissance visuelle/faciale, autrefois réservées à des industriels et l'armée, sont devenues des éléments de notre quotidien:
- Reconnaissance d'amis dans les albums photos ou via les moteurs de recherche
- Reconnaissance vocale (lors d'un appel téléphonique), pour dicter un SMS à votre smartphone ou encore pour reconnaître une chanson à la radio (applications Shazam, SoundHound, …)
- Pilotage automatique de nos automobiles
- L'art aussi n'y échappe pas : Musique, Poésie, ou encore la Peinture en immitant Rembrant
On commence même à voir rêver les ordinateurs…

Ou Machine Learning
Définition
L'apprentissage automatique peut-être vu comme l’ensemble des techniques permettant à une machine d’apprendre à réaliser une tâche sans avoir à la programmer explicitement pour cela.
Arthur Samuel.
Définition reprise d'un article d'Antoine GaudelasL'apprentissage automatique ou apprentissage statistique est un domaine de l'intelligence artificielle qui concerne la conception, l'analyse, le développement et l'implémentation de méthodes permettant à un ordinateur d'évoluer par un processus systématique, et ainsi de remplir des tâches difficiles ou problématiques à remplir par des moyens algorithmiques plus classiques.
Définition adaptée de Wikipédia
En d'autres termes, l'apprentissage automatique est un des domaines de l'intelligence artificielle visant à permettre à un ordinateur d'apprendre des connaissances puis de les appliquer pour réaliser des tâches que nous sous-traitions jusque là à notre raisonnement.
Le type de tâches traitées consiste généralement en des problèmes de classification de données:
- Voici 50 photos de ma fille, voici maintenant toutes les photos de mon album, retrouve celles ou se trouve ma fille
- Voici 10000 personnes avec leurs caractéristiques (âge, localisation, taille, profession…), rassemble-les en 12 groupes cohérents partageant les mêmes points communs
- Voici les paramètres de vol des avions de ma flotte avec les pannes survenues à chaque vol, quand il s'en produit. Maintenant voici les derniers vols réalisés par cet avion, indique-moi quand arrivera la prochaine panne et sur quel élément elle se produira.
- Voici les livres écrits par Victor Hugo, voici une nouvelle dont nous recherchons l'auteur, est-elle de lui ?
- Voici des mesures scientifiques réalisées sur un échantillon de données, elles semblent répondre à une loi Mathématique, essaye de l'approximer par des fonctions Mathématiques puis prédit les valeurs des prochaines données
Les possibilités sont très grandes et l'on retrouve l'apprentissage automatique dans de nombreux domaines de la vie réelle comme:
- La vision par ordinateur
- La conduite automobile sans chauffeur
- La prédiction de pannes
- L'identification des personnes indécises susceptibles de se laisser convaincre par un candidat à l'élection présidentielle américaine
- L'optimisation de consommation électrique chez Google
- La surveillance de la pêche illégale ou de la déforestation
- La traduction linguistique
Présentation de l'apprentissage automatique
Quand on parle d'apprentissage automatique, on parle de types d'apprentissages, parmi les plus répandus on citera:
Yann Le Cun qui est considéré comme l'un des inventeurs du Deep Learning résume ainsi ces différentes classes:
La majorité des types d'apprentissages chez l'homme et l'animal sont non supervisés. Si l'apprentissage automatique était un gâteau, l'apprentissage non supervisé serait ce gâteau, l'apprentissage supervisé serait le nappage du gâteau et l'apprentissage par "renforcement" serait la cerise sur le gâteau. Nous savons faire le nappage et la cerise, mais nous ne savons pas faire le gâteau.
L'image est bonne, même si certains ont des avis plus nuancés.
Chaque type d'apprentissage peut s'appuyer sur différents algorithmes :
- Linear Regression (régression linéaire),
- Logistic Regression (régression logistique),
- Decision Tree (arbre de décision),
- Random forest (forêts d'abres/arbes aléatoires)
- SVM (machines à vecteur de support),
- Naive Bayes (classification naïve bayésienne),
- KNN (Plus proches voisins),
- Gradient Boost & Adaboost,
- Dimensionality reduction
- Q-Learning
- Réseaux de neurones
- …
Apprentissage supervisé
L'apprentissage supervisé permet de répondre à des problématiques de classification et de régression.

L'idée consiste à associer un label à des données sur lesquelles vous possédez des mesures.
- Si les labels sont discrets (des libellés ou valeurs finies) on parlera de classification.
- Si au contraire les labels sont continus (comme l'ensemble des nombres réels), on parlera de régression.
Classification
La classification consiste à donner des étiquettes à ses données:
- Vous disposez d'un ensemble de données connues que vous avez déjà classé (photos, plantes, individus…)
- Vous souhaitez, à partir de cette première classification, dite connaissance, classer de nouveaux éléments
Certains logiciels d'albums photos utilisent ce type d'apprentissage pour classer vos images:
- Ils vous permettent de désigner un ensemble de photos contenant votre enfant et d'indiquer où se trouve ce dernier dans ces images.
C'est la phase d'apprentissage - Puis vous lui dites, voici ma collection de 15000 photos, retrouve toutes celles qui contiennent mon enfant
Le logiciel analyse alors votre collection et tente de retrouver celles qui présentent une similitude avec le jeu de données que vous lui avez enseigné. Certains logiciels vous indiquent même où se situe votre enfant dans l'image
C'est la phase de prédiction
Un autre exemple très parlant est la détection automatique de Spams:
- Vous disposez d'un grand nombre d'emails déjà classés avec une étiquette Spam/Valide
- Vous souhaitez classer les nouveaux emails entrant sur la connaissance des emails déjà classés
Les résultats sont généralement très bons, vous trouverez facilement de nombreux exemples sur Internet, notamment en Python, comme celui-ci utilisant un réseau de neurones.
Ce type de classification permet de répondre à de nombreux problèmes d'identification : reconnaissance de plantes, de personnes, de produits, reconstitution de valeurs manquantes (en remplacement d'une interpolation), etc…
Il peut utiliser différents types d'algorithmes, comme les plus proches voisins, les machines à vecteurs de supports, les arbres décisionnels, …
Régression
Imaginez un ensemble de points sur une image en 2 ou 3 dimensions, ayant une intensité lumineuse différente.
Par exemple une image satellite des étoiles lointaines ou encore une photo de nuit des feux des véhicules en circulation.

Cette intensité lumineuse est mesurable et peut être considérée comme un label, mais il est différent pour chaque étoile. C'est un label continu qui peut prendre toute valeur au dessus de 0.
Les régressions vont nous permettre de s'approcher d'une équation idéale permettant de déterminer la luminosité de chacune de nos étoiles en fonction de leur position ou inversement la distance des véhicules en fonction de la luminosité de leurs phares.
En astronomie ce procédé est utilisé pour identifier la distance des galaxies à partir de multiples observations comme les mesures de l'intensité lumineuse de chacune d'elles dans les différentes longueurs d'ondes. Cela s'appelle le décalage vers le rouge photométrique
Les algorithmes tels les régressions linéaires, machines à vecteur de support ou encore les forêts d'arbres de décision sont taillés pour ce type de traitement.
Apprentissage non supervisé
L'apprentissage non supervisé répond au même besoin de classification de données. Mais contrairement à l'apprentissage supervisé, vous ne possédez pas de données déjà classées/connues servant de base à la prédiction.

Vous utilisez ce type d'algorithme pour répondre à 2 types de tâches:
- La classification de données, mais comme vous n'avez pas encore les labels, on parle alors de clustering c'est à dire de regroupement.
- L'autre tâche consiste à réduire le nombre de dimensions de vos données tout en conservant une variation/un regroupement semblable aux données d'origine, on parle alors de dimensionality reduction
Clustering
Avec ce type d'apprentissage il n'y a qu'une phase de prédiction.
Vous alimentez l'algorithme de toutes vos données et lui demandez de les répartir en N groupes. L'algorithme tentera alors de créer des groupes pour lesquels les paramètres de chaque donnée sont les plus similaires.
Quelques exemples d'applications:
- Classer les cultures d'une région:
Vous disposez des métriques sur les parcelles agricoles d'une région (teneur en nitrates, phosphates, salinité, surface, haies, …) et vous savez qu'il y a 12 cultures différentes.
Vous allez demander à votre classifieur de créer 12 groupes en les classant selon des critères de ressemblance. - Vous possédez des statistiques sur une population (salaire, localité, âge, profession, nombre d'enfants), vous souhaitez les regrouper en différentes catégories sociales.
Les algorithmes des plus proches voisins, arbres de décision, les réseaux de neurones, la propagation par affinité sont généralement utilisés pour ce type de traitement.
Réduction de dimension
Ici vous avez un problème un peu différent : chaque information/donnée que vous souhaitez traiter possède trop de paramètres, soit pour être visualisée, soit pour être traitée dans des temps raisonnables et sur des machines limitées en ressources.
Vous devez donc diminuer le nombre de ces paramètres tout en conservant une cohérence sur leurs variations globale. De sorte que si vous regroupiez vos données en utilisant tous les paramètres vous obtiendriez sensiblement le même regroupement qu'avec les paramètres réduits.
Un usage type consiste à visualiser les groupes des données dans un espace en 2D ou 3D.
Un algorithme fréquemment utilisé est l'analyse en composantes principales (PCA), mais il en existe d'autres comme la factorisation en matrices non-négatives
Apprentissage par renforcement
« L’intelligence, c’est la faculté d’adaptation »
André Gide
Ce type d'apprentissage s'applique plus à des problèmes d'optimisations. L'idée étant de faire prendre des décisions à un système pour obtenir un résultat qui soit le meilleur possible.
Ce type d'algorithme est très inspiré d'études du comportement en biologie animale ou psychologie. Il est d'ailleurs étroitement lié à ces disciplines.
Pour cela l'algorithme va appliquer des règles sur son environnement pour arriver au résultat attendu. Il dispose de la faculté de mesurer l'impact de la règle sur l'environnement : on se rapproche du but ou on s'en écarte.
A partir de là, il peut donc se constituer une base de connaissances des gains réalisés par chaque action qui l'aidera à améliorer ses décisions et ainsi trouver les meilleures manières d'atteindre son but.
Les algorithmes ne garantissent pas forcément d'obtenir le meilleur résultat, mais de s'en approcher. Là où ils commencent à se complexifier c'est que l'obtention de petits gains immédiats ne doit pas empêcher de chercher des gains plus forts qui ne s'obtiennent qu'après plusieurs actions ayant entraîné une suite de pertes.
Différents algorithmes sont disponibles pour ce type d'apprentissage, comme le Q-Learning ou Monte-Carlo, SARSA, mais ce sont les réseaux de neurones qui semblent être les plus pratiqués lorsque l'on regarde la littérature sur Internet.
Des exemples d'utilisation sont:
- La robotique: faire se déplacer un robot dans des conditions mouvantes
- Optimiser le déplacement des ascenseurs
- Router des paquets réseau
- Jeux de stratégie
- Chemin parcouru par les fourmis pour acheminer leur nourriture à la fourmilière
Pour creuser le sujet:
- Apprentissage par renforcement – de la théorie à la pratique
- Un cours de l'INRIA et quelques autres
- Des vidéos de robots réalisant diverses tâches grâce à l'apprentissage par renforcement
Apprentissage par transfert
L'apprentissage par transfert vise à utiliser les connaissances d'un jeu de tâches sources pour non seulement influencer l'apprentissage mais aussi améliorer les performances sur une autre tâche cible.
Il consiste en quelque sorte à utiliser les connaissances acquises pour les ré-appliquer dans un autre environnement. Pour être efficace l'environnement cible ne doit pas être trop différent de celui des tâches sources, sinon des transferts négatifs seront réalisés menant au contraire du résultat recherché.
Un exemple d'utilisation consisterait à transférer des tâches d'un réseau de neurones utilisé pour la reconnaissance manuscrite de l'écriture dans une langue pour l'appliquer à une autre langue, même très différente (français/japonais).
Les différents types d'algorithmes
La régression linéaire
La régression linéaire consiste à déterminer une équation de droite/plan qui se rapproche au plus près de l'ensemble des points étudiés.
L'idée étant de déterminer les coefficients a et b de l'équation
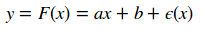
- y est la variable que l'on cherche à calculer, prédire, elle est dite endogène (dépendante).
- x est la variable prédictive, elle est dite exogène (indépendante).
- a et b sont les paramètres (les coefficients) du modèle.
Dans le cas de la régression simple, a est appelée la pente et b est appelée la constante. $\epsilon$ est le bruit généré lors de la mesure et perturbant la bonne identification de la relation.
On utilise ensuite cette équation pour prédire de nouvelles données.
Ce système n'est efficace que si les relations entre vos données sont simples. Dans le cas de courbes plus complexes qu'une droite ou qu'un plan on se tournera vers des solutions polynomiales et gaussiennes. Les algorithmes de type SVM sont très adaptés pour ces cas plus avancés.
La régression logistique
Les régressions logistiques, aussi appelées modèle logit, sont un cas particulier des régressions linéaires.
Cela consiste à modéliser l'effet d'un vecteur de données/paramètres aléatoires sur une variable binomiale, c'est à dire pouvant avoir seulement 2 états, Vrai/Faux (0/1), d'où le terme logistique.
y est la variable expliquée et les vecteurs (x1, x2, …, xn) les variables prédictives/explicatives.
Le site Wikipédia fournit une description complète du modèle probabiliste associé. Il s'agit bien d'une régression linéaire même si le fait de n'avoir que 2 valeurs possibles pour 'y' fait penser à un problème de classification.
Elle est utilisée dans de multiples cas, dont voici des exemples issus de Wikipédia:
- En médecine, elle permet par exemple de trouver les facteurs qui caractérisent un groupe de sujets malades par rapport à des sujets sains.
- Dans le domaine des assurances, elle permet de cibler une fraction de la clientèle qui sera sensible à une police d’assurance sur tel ou tel risque particulier.
- Dans le domaine bancaire, pour détecter les groupes à risque lors de la souscription d’un crédit.
- En économétrie, pour expliquer une variable discrète. Par exemple, les intentions de vote aux élections.
Les arbres de décision
Les naturalistes qui sont parmi vous auront probablement connu le logiciel "Mais quel est donc cet oiseau?"

Il permettait en quelques questions et en affichant des silhouettes d'oiseaux de vous aider à identifier un oiseau que vous aviez vu dans la nature. Même si vous ne connaissez rien à l'ornithologie.
Plus récemment l'application Akinator vous amuse en devinant un personnage auquel vous pensez.

Ces 2 applications sont basées sur le principe des arbres de décision:
- A chaque noeud une question est posée permettant de limiter l'ensemble des solutions restantes en 2 parties disjointes et les plus importantes possibles. Dans le principe de la dichotomie, calcul de la médiane.
- Puis au noeud suivant une autre question est posée pour limiter de la même manière l'ensemble des solutions restantes
- Jusqu'à ce qu'il n'en reste plus qu'une seule.
Dans le cas de l'apprentissage automatique les arbres de décision sont construits par l'algorithme pour essayer de diviser ainsi les données sur les paramètres des vecteurs:
- Chaque nœud interne décrit un test sur un paramètre d'apprentissage
- Chaque branche représente un résultat du test
- Chaque feuille contient la valeur de la variable cible
- une étiquette de classe pour les arbres de classification
- une valeur numérique pour les arbres de régression
La pertinence de l'algorithme construisant l'arbre se mesurera à sa capacité de trouver les paramètres qui permettent de maximiser le partage à chaque noeud.
Les arbres de décision s'utilisent en apprentissage supervisé.
L'article Wikipédia fourni en lien décrit bien les contraintes techniques de construction de ces arbres et les difficultés de prédire un label unique ainsi que différents inconvénients, comme:
- L'influence de l'ordre des paramètres prédicteurs dans le graphe
- La difficulté de représenter des règles comme le Ou Exclusif
Ils sont toutefois très utiles pour essayer de comprendre le cheminement des paramètres de l'information et peuvent être un bon complément aux régressions logistiques.
Random forest
Les forêts d'arbres décisionnels/aléatoires sont basées sur le concept de bagging/inférence statistique et d'arbres décisionnels.
L'idée étant d'apprendre sur de multiples arbres de décision travaillant sur des sous-ensembles de données les plus indépendants possible.
Cela permet de régler plusieurs problèmes inhérents aux arbres de décision uniques comme l'altération du résultat selon l'ordre des paramètres prédicteurs dans les noeuds, ou encore de réduire leur compléxité.
SVM
Les machines à vecteur de support sont très utilisées dans les problèmes de régression et offrent une extension aux régressions linéaires lorsque les données présentes des niveaux de séparation plus tordus !

Elles permettent de calculer des données quand leurs labels ne sont pas séparables par une équation linéaire. Elles proposent de séparer les données avec des équations plus riches comme des polynomes, gaussiennes, etc…
Elles connaissent un très grand succès, pour de multiples raisons:
- Elles peuvent travailler avec des données disposant d'un très grand nombre de paramètres
- Elles utilisent peu d'hyperparamètres
- Elles garantissent de bons résultats théoriques
- Elles peuvent égaler ou dépasser en performance les réseaux de neurones ou modèles gaussiens
Naive Bayes
La classification naïve bayésienne est basée sur le théorème de Bayes permettant de déterminer la distribution d'une loi binomiale.
Il s'agit d'une équation décrivant la relation entre des probabilités conditionnelles de quantités statistiques.
Elle s'inscrit dans le groupe des classifieurs linéaires.
Nous souhaitons ici trouver la probabilité d'un label à partir de paramètres observés, noté P(L|params)
Le théorème de Bayes permet de calculer cette information:
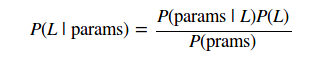
La génération d'un modèle sur cette loi se fait pour chaque label et peut être ardue. Le modèle est dit naïf car il simplifie grandement cette tâche en procédant à plusieurs approximations naïves.
Il est de ce fait très rapide et c'est un bon modèle pour commencer une classification.
KNN
L'algorithme des plus proches voisins est relativement simple.
Une de ses forces est de ne calculer aucune information dans le processus d'apprentissage.
Il recherche les N plus proches voisins (par un calcul de distance) entre la donnée à prédire et les données connues. Il retourne alors la classe de la majorité des voisins.
Assez simple à mettre en oeuvre il peut générer beaucoup de calculs et ne pas être adapté à de fortes volumétries ; notamment si le nombre de paramètres est très grand.
Gradient Boost & Adaboost,
Le gradient boosting est un algorithme s'appliquant aux problèmes de classification et régression.
L'idée est d'améliorer la prédiction et la vitesse en combinant un ensemble d'algorithmes d'apprentissages plus simples au travers d'un arbre de décision.
Le travail revient alors à identifier la fonction permettant de maximiser le choix des différents algorithmes.
AdaBoost est une variante du gradient boost. Il combine via une somme pondérée le résultat de différents algorithmes d'apprentissage plus simples. Il est adaptatif dans le sens ou il peut jouer sur le poids des différents algorithmes simples en fonction de la qualité de leurs résultats.
Réseaux de neurones et deep learning
Les réseaux de neurones tentent de reproduire le fonctionnement des neurones biologiques.
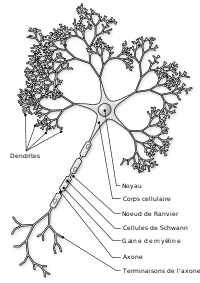
Pour vulgariser leur fonctionnement:
- il s'agit d'un graphe ou chaque nœud représente un neurone
- chaque neurone reçoit une information quand il est stimulé
- il ne la transmet (généralement en la modifiant ou complétant) aux neurones auxquels il est connecté que si celle-ci dépasse un certain seuil
Ils sont généralement très rapides et permettent des mécanismes perceptifs indépendants du concepteur de l'algorithme. Ils ouvrent la voie au raisonnement de la machine.
L'algorithme porte sur la construction d'un automate dont les états peuvent évoluer:
- Les valeurs seuils peuvent être adaptées au fil des informations traitées en utilisant des systèmes correctifs de récompense/blâme par exemple
- Les paramètres synaptiques peuvent aussi varier
- Tout comme les connexions entre neurones
Dans ces réseaux la phase d'apprentissage vise à faire converger les paramètres des données vers une classification optimale.
Ils nécessitent énormément de données d'apprentissage et ne sont pas adaptés à tous les problèmes notamment si le nombre de paramètres en entrée est trop faible.
Le terme Deep learning désignes des réseaux de neuronnes juxtaposés, ou encore constitués de plusieurs couches.
Il s'inspire, entre autres, des dernières avancées en neuroscience et des modèles de communication de notre système nerveux.
Certains l'associent aussi à une modélisation offrant un plus haut niveau d'abstraction des données pour offrir de meilleures prédictions.
Le deep learning est particulièrement efficace sur le traitement de l'image, du son et de la vidéo. On le retrouve dans les domaines de la santé, robotique, vision par ordinateur, …
Un projet particulièrement réputé est le projet Horus développé par NVidia qui permet à des personnes souffrant de déficience visuelle de s'orienter et reconnaître des objets.
Du fait de leur grand besoin en données d'apprentissage ils sont très coûteux en ressources matérielles.
Choisir son type d'apprentissage et son algorithme
Il est nécessaire de réunir plusieurs ingrédients qui doivent être savamment mélangés pour réussir une IA:
- La qualité des données
- La puissance de calcul (le matériel)
- Les algorithmes
- Et le talent
Quand on demande à un expert en apprentissage automatique quel algorithme est le mieux pour tel problème, il vous répond en général :
ça dépend, il faut en essayer plusieurs et voir celui qui fonctionne le mieux sur ce cas
Et en effet cela dépend:
- De la qualité des données dont vous disposez pour l'apprentissage et pour la classification
- Des paramètres que vous utilisez avec vos données
- De la quantité des données sources et à classer
- Du temps d'exécution requis
- Des paramètres disponibles pour influencer le comportement de l'algorithme
- …
En général, vous devez en essayer plusieurs pour vous faire une idée.
Parfois vous en utiliserez vraiment plusieurs, selon la précision souhaitée, si celui qui est généralement le meilleur donne un résultat insatisfaisant sur un jeu de données précis, un autre s'en sortira peut-être mieux sur ce cas là.
Voici déjà quelques liens, faute de mieux pour le moment, pour vous aider à choisir vos algorithmes selon vos besoins de classification:
Heureusement il existe des techniques permettant de mesurer la qualité d'un algorithme sur un jeu de données. Nous vous présenterons quelques outils pour y parvenir.
Nous verrons alors que sur certains domaines, certains algorithmes semblent d'office destinés à répondre avec le plus de pertinence.
Machine Learning et Python
Python a su s’installer/s'imposer dans l'univers scientifique et industriel.
Le domaine du machine learning n'est pas resté à l'écart, bien au contraire…
Les formidables possibilités de calcul du langage ont permis de percer ce secteur et de multiples librairies ont vu le jour.
- Annoy, librairie extrêmement rapide implémentant la recherche des plus proches voisins
- Caffe, Deep learning framework
- Chainer, Framework intuitif pour les réseaux de neurones
- neon, Deep Learning framework extrêmement performant
- NuPIC, Plateforme d'IA implémentant les algorithmes d'apprentissage HTM
- Shogun, Large Scale Machine Learning Toolbox
- TensorFlow, Réseau de neurones disposant d'une API de haut niveau
- Torch, Framework d'algorithmes d'apprentissage très performant disposant de binding Python
- Theanets, deep learning
- …
Le plus épatant est qu'elles sont toutes généralement d'une grande qualité et utilisées dans des environnements professionnels.
Toutefois, Scikit-Learn est probablement la plus populaire des librairies disponibles pour ce langage.
Elle possède un grand nombre de fonctionnalités spécialisées dans l'analyse de données et le data Mining qui en font un outil de choix pour les chercheurs et développeurs.
Pour aller plus loin
- Le site Wikipédia renferme de très bonnes références sur l'intelligence artificielle
- Le site O'Reilly tient un excellent blog sur l'IA et propose quelques livres gratuits très intéressants
AFIA, l'Association Française pour l'Intelligence Artificielle
L'Association OpenAI fondée par Elon Musk propose de développer une Intelligence Artificielle ouverte fonctionnant pour le bien de l'humanité
Elle fournit de nombreuses ressources et notamment pour tester vos algorithmes d'apprentissage automatique.- Le livre Python Data Science Handbook entièrement en notebooks
A lire absolument par tout Data Scientist !
Références
Les images utilisées dans ce document sont sous des licences libres et proviennent des sites:
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Initiation au Python scientifique
A distance (FOAD) Du 15 au 19 juin 2026
Voir la Formation Initiation au Python scientifiqueActualités en lien
Initiation au Machine Learning avec Python - La pratique
Data Science
30/05/2017
Dans ce tutoriel en 2 parties nous vous proposons de découvrir les bases de l'apprentissage automatique et de vous y initier avec le langage Python. Cette seconde partie vous permet de passer enfin à la pratique avec le langage Python et la librairie Scikit-Learn !

Python : Bien configurer son environnement de développement
Python
27/11/2015
Comment utiliser les bonnes pratiques de développement Python.
Optimiser ses tests unitaires Django avec setUpTestData
Django
22/06/2015
Découvrez comment gagner en efficacité sur les tests unitaires et sa méthode d'initialisation des tests : setUpTestData.