Makina Blog
Hackaviz 2018, recette d'une visualisation de données
Retour sur notre participation à un concours toulousain.
En mars 2018, nous avons participé au Hackaviz organisé par l'association Toulouse Dataviz.
Phase exploratoire
L'idée, avant de construire notre visualisation finale, est déjà de "comprendre" les différentes données fournies pour le concours. Ici, chaque membre de notre équipe utilise un logiciel différent, en fonction de son parcours, ses affinités, ses technologies de prédilection.
Outils utilisés
QGis
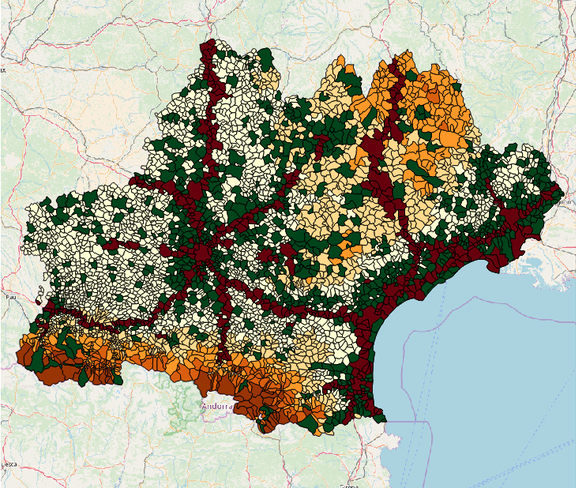
Utilisé par notre équipe SIG, QGis est LE logiciel libre par défaut pour manipuler des données géographiques. Extrêmement riche en fonctionnalités, ce logiciel permet de superposer très rapidement différentes sources de données pour réaliser des visualisations sommaires et observer des premières corrélations ou pistes :
Matplotlib
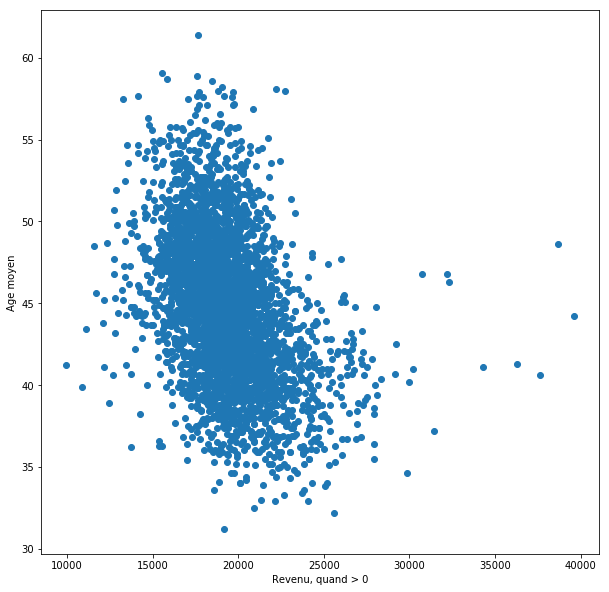
Utilisé par notre équipe Python, Matploblib permet de rapidement réaliser des visualisations statistiques, géographiques :

ou non (ici, la corrélation (ou plutôt l'absence de) entre le revenu et l'espérance de vie :
Dataiku
Dataiku est une plateforme (non libre, mais disposant d'une version gratuite) de datascience qui permet plusieurs choses, une fois les données importées en "dataset". D'abord, il est possible d'obtenir une analyse rapide de la distribution des données, mais surtout, il est possible de lancer sur les données des modèles de machine learning.
Dans la mesure où on ne sait pas ce que l'on cherche, on peut notamment lancer des algorithmes non-supervisés, et notamment des détections d'anomalies ou des algorithmes de clusterisation, que l'on peut paramétrer et lancer avec ou sans phase préparation de réduction des données (par PCA).
Lancé sur nos données, les anomalies identifiées sont caractérisées par une proportion anormalement élevée de stations services, grands magasins de bricolages, magasins d'articles de sport… en somme, l'outil détecte une très forte opposition entre les (très) grandes villes, et le plus grand ensemble des villes petites ou moyennes… Pas très exploitable pour le moment !
Cela dit, de nombreuses colonnes ne sont pas tellement exploitables ou adaptées à ce type de clusterisation (la forme géographique des communes, les nombreuses colonnes vides, …). Il faut donc commencer par nettoyer ce dataset.
ObservableHQ
Utilisé par notre équipe front-end, ObservableHQ est une nouvelle application web, reprenant la recette des "notebook" Junyper, et permettant de rapidement prototyper des applications javascript, avec le code disponible à tous, permettant de copier / modifier / …
D3.js
D3.js est une librairie Javascript pour manipuler des documents basés sur des données. D3 donne vie aux données en utilisant HTML, SVG et CSS. et permet l'affichage de données numériques sous une forme graphique et dynamique avec un vaste choix pour le rendu visuel.
Recherches d'idées
Absurdité, biais des données, fausse corrélation… C'est par cet angle que nous avons abordé les données mises à notre disposition. Nous avons donc tenté de démontrer que les corrélations un peu rapides, les données imprécises, l'inversion de la cause et de la conséquence permettent de faire dire aux chiffres ce que l'on veut. À nous d'aiguiser notre sens critique !
Visualisation des données
Biais n°1
Le crash de 2008 : mythe ou réalité ? La preuve par les chiffres.
Nous avons voulu faire parler les chiffres pour contredire une réalité économique à savoir que l'année 2008 a été particulièrement mauvaise en terme de création d'entreprise. Or les chiffres visualisés ne nous mènent pas du tout vers cette cette interprétation.
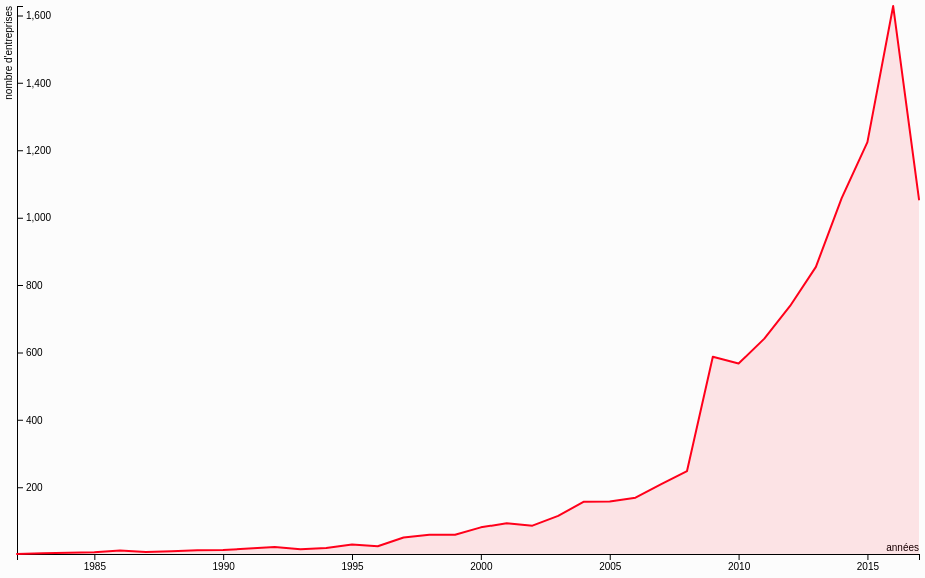
En réalité cette courbe témoigne surtout du fait qu'à partir de 2010 les chiffres concernant le nombre de création d'entreprises sont plus fiables.
Biais n°2
Ces communes en dessous du seuil de pauvreté !
Nous avons analysé les données des populations ainsi que des revenus et il nous est apparu que les populations vivant à des altitudes élevées n'étaient pas celles qui avaient les revenus les plus bas.
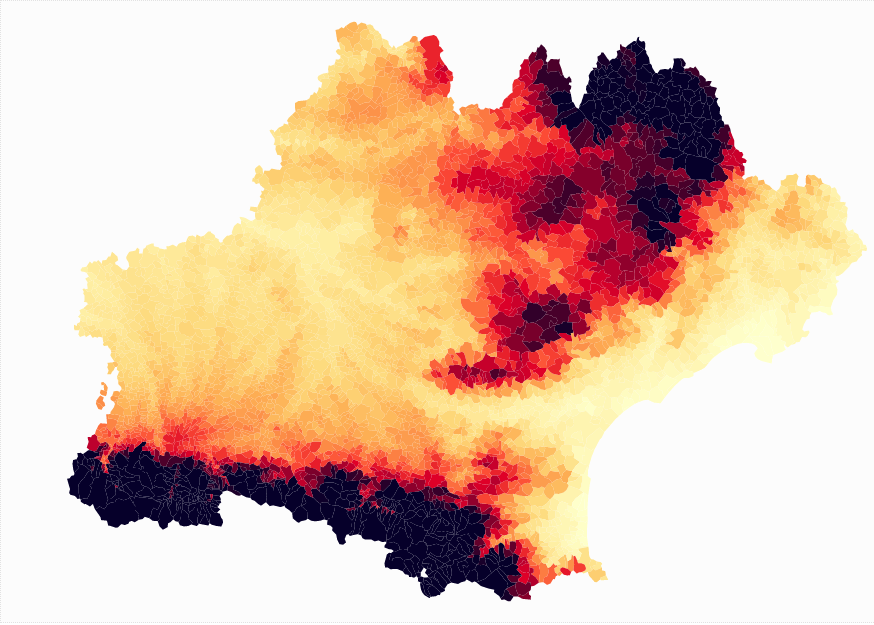
Ce graphique se contente d'établir une corrélation entre deux données arbitraires.
Biais n°3
L'exode des petits commerces vers les grandes villes !
Nous avons voulu démonter le cliché selon lequel les "grandes villes = grands centres commerciaux". En effet, les les petits commerces sont concentrés autour des grandes villes d'Occitanie.
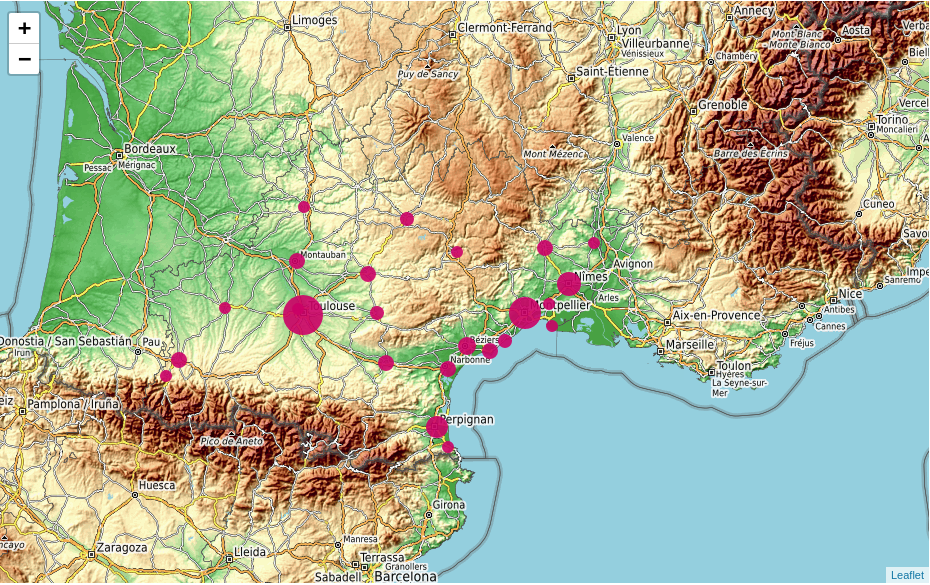
En réalité comme les grandes villes regroupent davantage de commerces, elles ont mécaniquement davantage de petits commerces (boulangeries, charcuteries, etc.) que les communes rurales. Pour obtenir un graphique plus véridique il faudrait diviser le nombre de petits commerces par la superficie de la commune ou par son nombre d'habitants.
Conclusion
Nous nous sommes arrêtés à ces trois biais alors que nous avions en tête bien plus ! Le manque de temps n'a pas joué en notre faveur mais nous en avons retenu une belle dynamique d'équipe. Les échanges sur les compétences de chacun sont certainement bénéfiques pour le groupe de travail.
Nous vous invitons à regarder les résultats de ce hackaviz 2018 et apprécier le travail fourni par les participants.
Nous remercions au passage l'association Toulouse Dataviz pour avoir organisé ce hackaviz !

Drupal - SEO
Formations associées
Formations IA / Data Science
Formation Passer de Matlab à Python
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Passer de Matlab à PythonFormations SIG / Cartographie
Formation QGIS
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation QGISFormations IA / Data Science
Formation Python scientifique
Toulouse Du 21 au 25 septembre 2025
Voir la Formation Python scientifiqueActualités en lien
Notre expertise en Data science
Data Science
27/03/2019
L'IA est un domaine vaste et nos différents projets nous ont permis de monter en compétences sur plusieurs sujets. Cet article vous présente les thématiques pour lesquelles nous pouvons vous offrir notre expertise.
Prédiction du taux de monoxyde de carbone à Madrid - intérêt d'une approche Deep Learning
Data Science
27/11/2018
Dans cet article nous montrons comme utiliser les bibliothèques stars de l'éco-système scientifique en Python pour analyser des données publiques sur la qualité de l'air à Madrid. Nous verrons comment identifier les problèmes liés à ces données. Puis nous comparerons deux approches en Machine Learning : AutoSklearn et les réseaux de neurones de type LSTM.

Superset, l'outil de DataViz de AirBnB
Python
23/02/2018
Superset est un outil développé par AirBnB. Son objectif consiste à faciliter la prise de décision au sein d'une entreprise, en simplifiant l'accès à ses données. Superset permet notamment de regrouper les informations fournies par différentes sources, de créer des graphiques interactifs et de les partager sous forme de tableaux de bord.