Makina Blog
Extraction d'objets pour la cartographie par deep-learning : choix du modèle
Deuxième article de la série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires.
Dans l'article précédent sur la création de la vérité terrain, l’acquisition et la préparation des données nécessaires au développement d'un modèle de segmentation sémantique permettant l'extraction d'objets dans le cadre de problématiques liées à la cartographie ont été décrites. L'étape suivante est donc de définir quel modèle utiliser, comment l’entraîner sur le jeu de données constitué, et comment l'utiliser pour extraire les objets recherchés.
Notre modèle va donc pouvoir apprendre à identifier les objets recherchés à partir de nos données de vérité terrain : il s'agit d'apprentissage supervisé. Le modèle s'ajuste à partir d'exemples, c'est-à-dire à partir de données pour lesquelles le résultat attendu est connu. En effet, à partir d'images, qui correspondent à ce qu'attend le modèle en entrée, le modèle va définir un ensemble de règles permettant d'aboutir à la prédiction, et donc à la détection de l'objet ciblé en s'appuyant sur les labels et/ou annotations de notre jeu de données.
Lorsqu'il s'agit de traitement d'images, ce sont généralement des algorithmes d'intelligence artificielle appelés Réseaux de Neurones Convolutifs (Convolutional Neural Networks, CNN) qui sont utilisés. Dans cet article, nous allons revenir sur les différents modèles existants avant de vous expliquer notre choix et de détailler notre protocole de travail avec celui-ci.
Deep-learning et traitement d’images
Les modèles de deep-learning permettant le traitement des images sont fondés sur le principe des réseaux de neurones convolutifs (CNN). Les différentes évolutions et perfectionnements ajoutés à ce concept de base ont permis d'élargir les tâches que ces modèles peuvent effectuer, mais aussi d'optimiser leur fonctionnement. Mask R-CNN, le modèle que nous avons choisi d'utiliser peut permettre à la fois la classification et la segmentation d'objets : il est issu de plusieurs améliorations et combinaisons d'algorithmes sur lesquelles nous allons revenir ici.
Ce modèle fait partie de la famille des modèles R-CNN dont l'objectif est la localisation d'objets dans les images. Mask R-CNN est donc une extension de ce type de modèle de détection d'objets : comment ces algorithmes de deep-learning ont-il été améliorés pour aboutir à la création du modèle Mask R-CNN ?
CNN : Réseau de Neurones convolutifs
Revenons aux concepts de base. Les réseaux de neurones sont des algorithmes d'intelligence artificielle inspirés du fonctionnement des réseaux de neurones du cerveau humain. Parmi ces algorithmes, les réseaux de neurones convolutifs (CNN) permettent l'analyse des images. Ils constituent à ce jour l'une des tentatives les plus abouties de doter une IA de capacités s'approchant de la vision humaine.
Ils sont constitués de plusieurs couches, elles-mêmes constituées de plusieurs neurones. Chaque couche reçoit les informations de la couche précédente, traite ces informations et les renvoie à la couche suivante. Chaque neurone d'une couche est donc relié aux neurones de la couche suivante. Ces liens sont pondérés par des poids et, à l'image du signal électrique émis par les neurones biologiques, vont influencer la propagation de l'information à travers le réseau de neurones convolutifs.
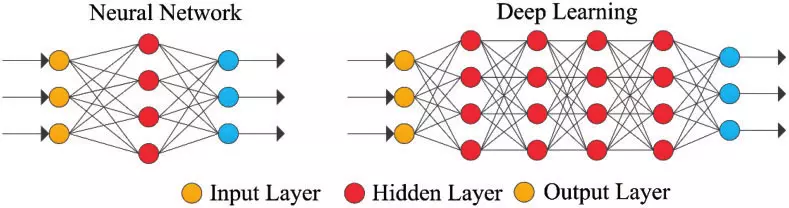
source: Xing, Wanli & Du, Dongping. (2018). Dropout Prediction in MOOCs: Using Deep Learning for Personalized Intervention. Journal of Educational Computing Research.
Ces modèles neuronaux sont composés de différents types de couches neuronales, correspondant à plusieurs étapes de l'analyse :
1. Couche de convolution :
Ces modèles traitent les images “fragments par fragments”, ils comparent ces “fragments” à des caractéristiques spécifiques. Ces images sont ainsi “filtrées” par une méthode mathématique appelée convolution : des filtres *Feature Detector*, permettant la détection de caractéristiques spécifiques, sont appliqués sur l’image et aboutissent à la création de plusieurs *Feature Map* ou "cartes des caractéristiques" correspondant à ces différents filtres. L’image de départ est donc transformée en plusieurs matrices selon les différentes caractéristiques avec lesquelles on l’a filtrée.
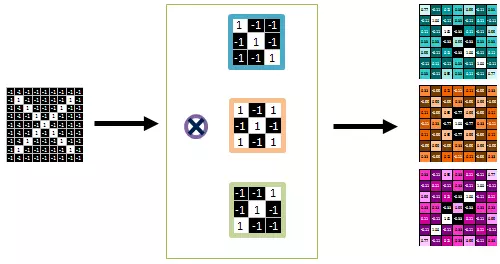
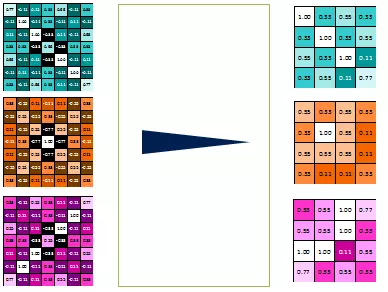
2. Couche de mise en commun (pooling) :
Le pooling est une étape qui permet de réduire le nombre de paramètres descriptifs de l'image et d’éviter le sur-apprentissage. C’est l’étape qui consiste à diminuer la taille d'une image tout en conservant le maximum d’information en passant une petite “fenêtre”, généralement de 2X2 pixels sur les Feature Map obtenues par convolution. Ici le pixel avec la valeur maximale est conservé et donc les caractéristiques les plus importantes.
3. Couche d'aplanissement (flattering) :
Il s’agit de l’étape d’aplanissement : notre matrice à N dimensions est transformée en un vecteur. Cela permet d’avoir un format de données correspondant aux entrées attendues par un réseau de neurones.
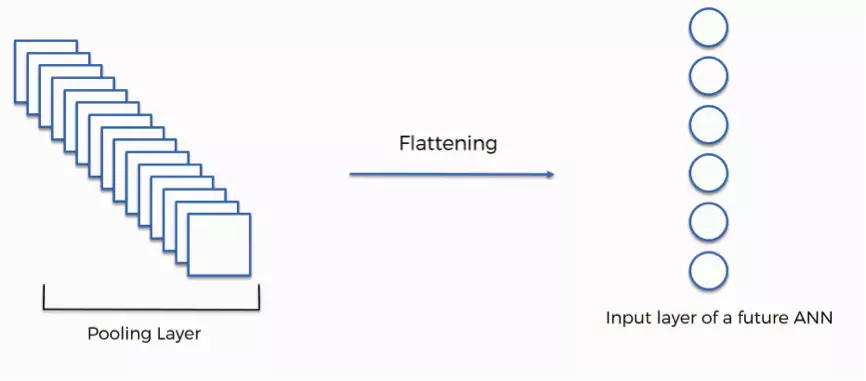
source : article de blog superdatascience
4. Couche dense (full connection):
C’est une couche de neurones connectée à tous les neurones de la couche suivante. Elle prend en données d’entrée (inputs) le résultat de l’étape de flattering. Du nombre de neurones en sortie va dépendre le type de réponse : il est possible de faire des classifications binaires (exemple : chien ou chat), multiclasses (exemple : chien, chat, oiseau - comme nous l'avons présenté dans un précédent article sur la détection d'émotions) ou bien de donner un résultat (exemple : l’âge du chien).
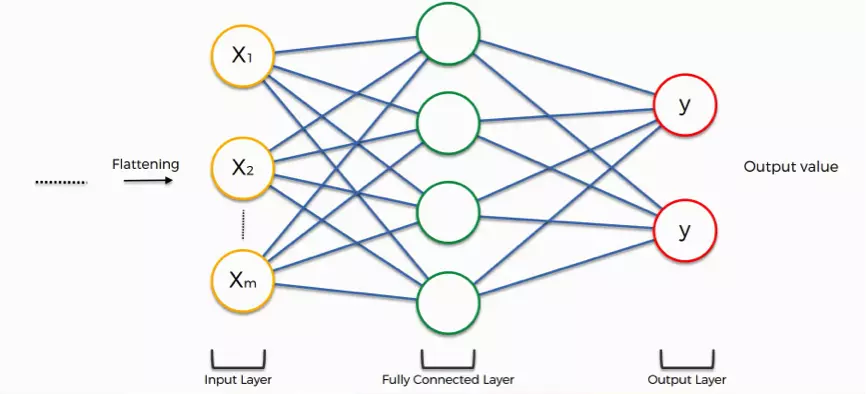
source : article de blog superdatascience
Pour compléter cette présentation, cette définition interactive des CNN permet de voir plus en profondeur leur fonctionnement.
R-CNN (Regional Convolutional Neural Network )
Les modèles R-CNN sont une famille de réseaux de neurones convolutifs conçus pour la détection d’objets, développés par Ross Girshick, et al.
A partir d’une image donnée en entrée, le modèle va extraire de l’image les régions les plus susceptibles de contenir un objet. On parle de zones d'intérêts. Pour chacune de ces zones d’intérêts, un ensemble de boîtes englobantes (bounding box) va être généré. Ces boîtes sont classifiées et sélectionnées en fonction de leur probabilité à contenir l'objet. 2000 propositions de régions sont ainsi extraites. Ces régions sont ensuite reçues en entrée par le CNN. Le modèle peut alors détecter dans une image un (ou plusieurs) objet(s), pouvant appartenir à des classes différentes.
Les avantages sont donc de traiter l’image par morceau et non pas toute l’image comme pour un CNN simple et de pouvoir localiser plusieurs objets dans une image. C'est un traitement plus rapide et moins coûteux en puissance-machine.
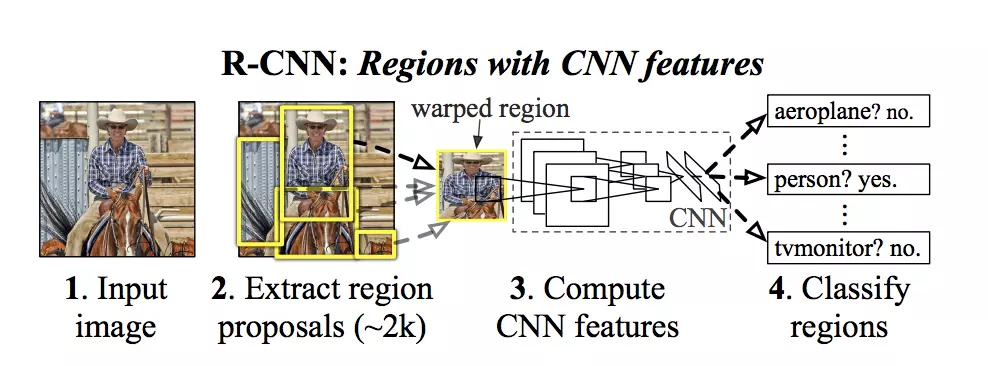
source: Ross Girshick, et al
Fast R-CNN
Avec un modèle R-CNN, chacune des zones d'intérêts proposées est reçue en entrée par le CNN, ainsi l’image de départ subit une convolution par zone proposée. En utilisant un modèle Fast R-CNN, c’est l’image de départ qui subit cette étape de convolution et c’est sur les features map générées que sont obtenues les propositions de régions susceptibles de contenir l'élément ciblé par le modèle. Cela constitue une amélioration en termes de temps d'exécution et de puissance requise.
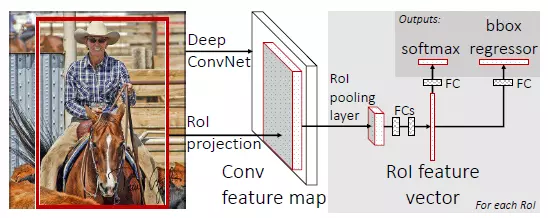
source Fast R-CNN, Ross Girshick
Faster R-CNN (Fast R-CNN + RPN)
Le temps de génération des zones d'intérêt est optimisé grâce à l'ajout d'un autre algorithme nommé Region Proposal Networks (RPN) : ce réseau de neurones convolutifs supplémentaire permet de générer directement les propositions de zones. En sortie, le modèle Faster R-CNN produit un label ainsi que les coordonnées de la zone de l'image contenant l'objet détecté (bounding box).
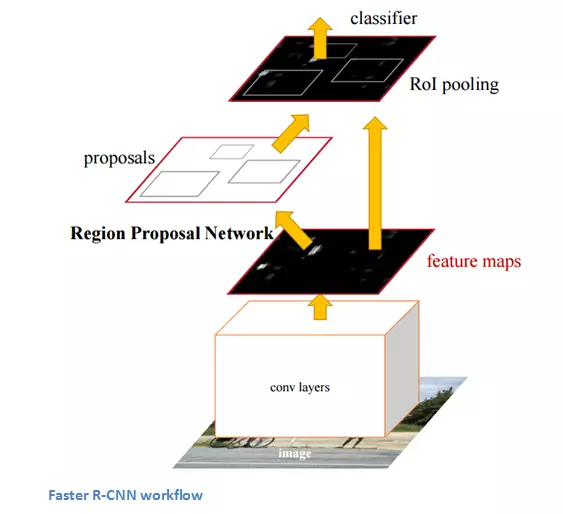
source : Faster R-CNN, Ren et al.
Mask R-CNN
Le modèle Mask R-CNN, comme les modèles précédents, permet de détecter des objets et de les classifier. Sa particularité est d’ajouter à cette tâche de détection la segmentation d’instance, c’est à dire que chaque pixel de l’image seront classés. Ainsi, cette double “compétence” représente un avantage par rapport à des modèles de détection, elle vient affiner le résultat proposé. De plus, contrairement à la segmentation sémantique, qui permet d'associer à chaque pixel un label, la segmentation d'instance associe un masque et un label à chaque objet, même si ces objets appartiennent à la même classe. Dans le cadre de notre étude où nous cherchons à extraire des toitures à partir d'images aériennes, chaque bâtiment est ainsi détecté indépendamment des autres et chacun a un masque qui lui est associé.
Mask R-CNN est une extension du modèle Faster R-CNN. Aux deux types de sorties générées par ce dernier, qui sont la classe de l'objet présent sur l'image et la boîte englobante associée, s'ajoute une troisième branche dont la sortie est le masque de l'objet.
Cet algorithme créé par Facebook est une combinaison de modèles déjà existants : le réseau convolutif ResNet101 ; un réseau de proposition de régions (regions proposal network, RPN) ; un classificateur binaire de masque.
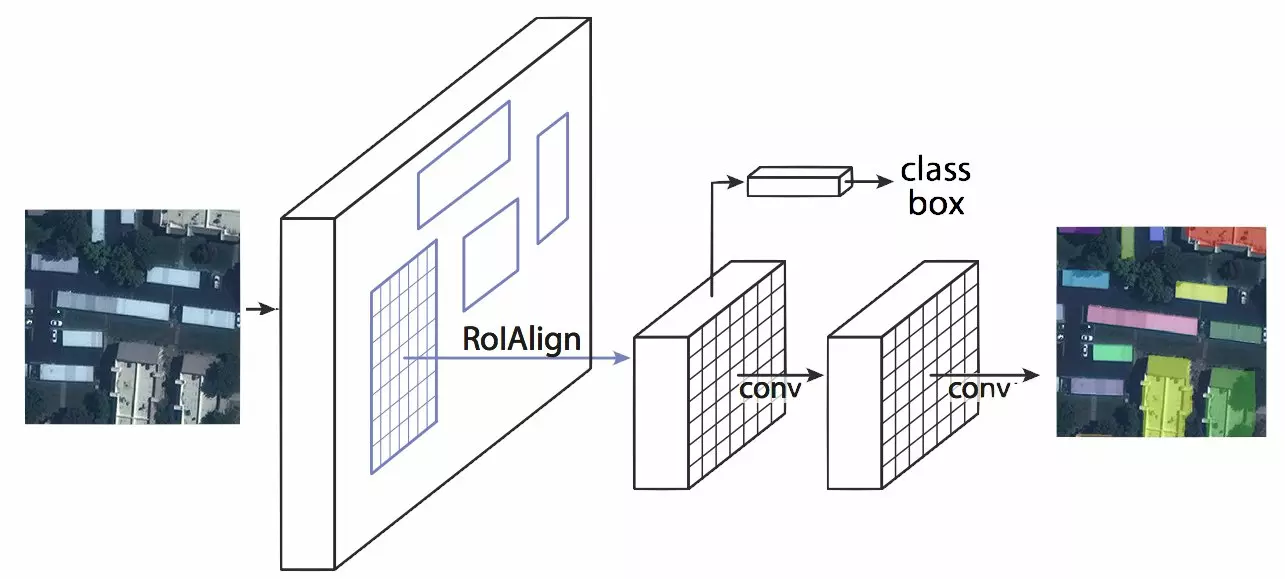
d'après K. He, G. Gkioxari, P. Doll ́ar, and R. Girshick. Mask R-CNN.arXiv:1703.06870, 2017, et Neptune ai open-solution-mapping-challenge
Il est rapide, relativement simple à implémenter et flexible quant aux tâches pouvant lui être incombées (il peut notamment permettre de qualifier la “posture” d’une personne par détection de keypoints). Il a aussi été utilisé dans beaucoup de challenges (comme le challenge CrowdAI Mapping Challenge) et de projets relatifs à la détection d’objets à partir d’images aériennes/satellites, ce qui a motivé notre choix de ce modèle.
Utilisation du modèle Mask R-CNN
Ce notebook Jupyter présente pas à pas l'utilisation du modèle Mask R-CNN : Utilisation_de_Mask-RCNN
Ce modèle, ainsi qu'un ensemble de fonctions facilitant son utilisation, est disponible sur github. Cette implémentation du modèle Mask R-CNN fonctionne avec les bibliothèques Tensorflow et Keras dans un environnement Python 3.
Entraînement
L'entraînement permet au modèle d'apprendre la tâche qui lui est incombée, à savoir détecter les bâtiments dans notre exemple. Le modèle est entraîné de façon supervisée : il va prendre comme exemple notre jeu de vérité terrain construite avec notre outil geolabel-maker, optimiser la marge d'erreur entre ses prédictions et le résultat attendu fourni par le fichier d'annotations associé à nos images.
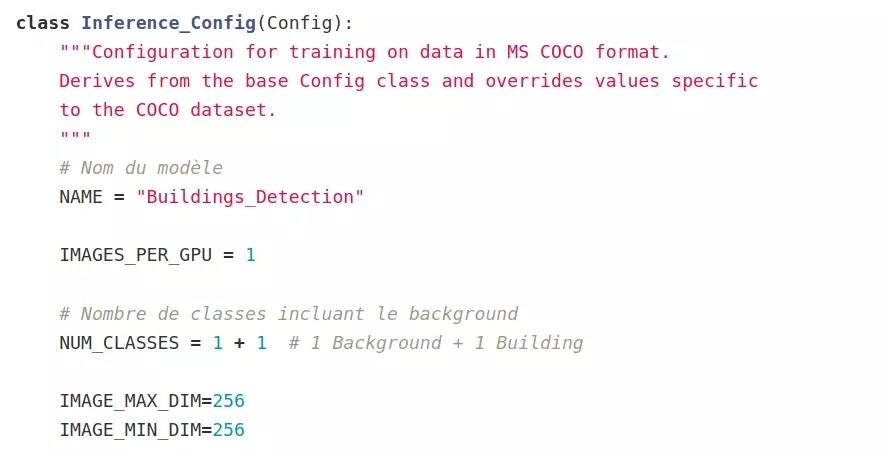
Configuration du modèle
La configuration du modèle va varier selon le mode de fonctionnement du modèle. L'implémentation disponible du modèle Mask R-CNN contient déjà une classe pour la configuration du modèle : la classe `Config`. Il suffit donc de créer une classe qui hérite de celle-ci pour configurer le modèle à notre utilisation.
Exemple :

Un des paramètres à ajuster est le nombre de catégories recherchées, la catégorie _background_ est la catégorie par défaut. Dans notre étude, nous avons donc 2 catégories d'objets : notre catégorie d'objet cible, les bâtiments et la catégorie _background_ pour le reste de l'image.
``` NUM_CLASSES = 1 + 1 # 1 Background + 1 Building ```
Dans le cas de l’entraînement, les autres paramètres importants sont :
- `IMAGES_PER_GPU` et `GPU_COUNT` qui permettent de définir la taille du lot (`BATCH_SIZE`). Celle-ci est calculée comme étant le produit de ces deux variables.
- `STEPS_PER_EPOCH` qui définit le nombre d'itérations par époques.
- `VALIDATION_STEPS` qui définit le nombre d'itérations pour la validation.
Pour une vision d'ensemble des différents paramètres à ajuster, vous pouvez regarder le fichier [config.py]() de l'implémentation du modèle Mask R-CNN.
Configuration du jeu de données
Pour que notre jeu de données puisse être utilisé par le modèle, il doit être fourni sous la forme d'images et annotations au format COCO, comme nous le détaillons dans notre précédent article dédié à la création de la vérité terrain. Les images correspondent à ce que le modèle attend en entrée et le fichier d'annotations contient les informations concernant la présence des objets ciblés par le modèle et leur catégorie. La configuration du jeu de données doit donc permettre d'extraire les images d'une part (données en entrée), et les informations de segmentation d'une autre part (réponses en sortie : masque et labellisation). Pour cela, il faut créer une classe adaptée à notre jeu de données qui hérite de la **classe `Dataset`** disponible dans les fichiers de Mask R-CNN.
Pour l’entraînement, nous avons besoin de deux jeux de données :
- un jeu d'entraînement sur lequel le modèle va apprendre ;
- et un jeu de test qui va permettre de valider le modèle sur des données sur lesquelles il n'a pas effectué son apprentissage.
Généralement, la vérité terrain est partagée aléatoirement selon ces ratios : 80% des données servent à l’entraînement et 20% à la validation.
Les commandes permettant d'initialiser les jeux de données sont les suivantes:
- pour le jeu d'entraînement :
``` data_train = BuildingDataset() ```
``` coco_data_train = data_train.load_dataset(annot_file_train,img_directory_train, return_coco=True) ```
``` data_train.prepare() ```
- pour le jeu de test :
``` data_val= BuildingDataset() ```
``` coco_data_val = data_val.load_dataset(annot_file_val,img_directory_val, return_coco=True) ```
``` data_val.prepare() ```
Initialisation du modèle et protocole d’entraînement
Pour réaliser l'entraînement, il faut initialiser le modèle en mode training.
La commande pour l'initialisation du modèle est la suivante :
``` model = modellib.MaskRCNN(mode="training",
config=config, model_dir=MODEL_DIR) ```
``` model_path = PRETRAINED_MODEL_PATH ```
``` model.load_weights(model_path, by_name=True) ```
La fonction `load_weights` permet de charger les poids d'un modèle pré-entraîné. Le chargement de ces poids permet de lancer des prédictions sur son propre jeu de données, mais aussi d’entraîner son modèle à partir d'un modèle pré-entraîné. Cette méthode est appelé apprentissage par transfert (ou transfert learning).
Le chargement des poids est optionnel : il est possible d'entraîner un modèle sans utiliser de poids de modèles déjà entraînés.
Pour initialiser notre modèle, nous avons téléchargé les poids d'un modèle entraîné sur les données du CrowdAI Mapping Challenge venant de cette solution open source.
La méthode d'entraînement proposée par Johnson (2018) dans le cadre de la segmentation de noyaux de cellules par Mask R-CNN a été suivie. Il s'agit d'un entraînement en trois étapes :
- entraînement des premières couches du réseau de neurones
- entraînement des couches supérieures du réseau de neurones
- entraînement de toutes les couches du réseau de neurones
Entraînement des premières couches :
L’entraînement des couches "heads" correspond à l’entraînement des premières couches du modèle. Ce sont elles qui permettent l’extraction des caractéristiques principales de l'image.
``` model.train(data_train, data_val, learning_rate=config.LEARNING_RATE, epochs=40, layers='heads') ```
Entraînement des couches supérieures :
L'option "4+" correspond à un entraînement de la quatrième couche et des suivantes. Les couches supérieures ne sont pas entraînées pendant cette phase.
``` model.train(data_train, data_val, learning_rate=config.LEARNING_RATE, epochs=120, layers='4+') ```
Entraînement de toutes les couches :
L'option "all" permet d’entraîner l'ensemble des couches du modèle.
``` model.train(data_train, data_val, learning_rate=config.LEARNING_RATE / 10, epochs=160, layers='all') ```
Afin d'obtenir un modèle performant, il est souvent nécessaire de réaliser plusieurs protocoles d'entraînement différents et ainsi conserver le meilleur résultat.
Prédiction sur nos données
Avec un modèle pré-entraîné, il est possible de lancer des prédictions : c'est-à-dire de fournir une image au modèle et d'obtenir en résultat la localisation des objets recherchés.
Configuration du modèle
La configuration du modèle est similaire à celle définie pour l'entraînement. Réduire le paramètre 'IMAGES_PER_GPU' à 1 permet de réaliser les prédictions image par image. Les autres paramètres restent inchangés par rapport à la configuration pour l'entraînement.
Initialisation du modèle et prédiction :
C'est le mode inférence qui est utilisé pour la prédiction et l'évaluation du modèle.
La commande pour initialiser le modèle est la suivante :
``` model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config) ```
``` model_path = PRETRAINED_MODEL_PATH ```
``` model.load_weights(model_path, by_name=True) #téléchargement des poids du modèle déja entrainé ```
``` class_names = ['BG', 'buildings'] # permet d'afficher le noms des catégories d'objets ```
Nous utilisons les poids obtenus après entraînement de notre modèle pour visualiser les prédictions dont il est désormais capable. Pour tester le modèle avant de l'entraîner, vous pouvez utiliser des poids qui ont été fournis dans le cadre du CrowdAI Mapping Challenge disponibles ici.
Il suffit d'appeler la fonction `detect()` pour utiliser le modèle :
``` results = model.detect([image], verbose=1) ```
Les résultats produits peuvent être visualisés avec la commande suivante :
``` visualize.display_instances(image, results[0]['rois'], results[0]['masks'], results[0]['class_ids'], class_names, results[0]['scores'], figsize=(12, 6)) ```
image originale donnée en entrée.

image avec le résultat de prédiction.

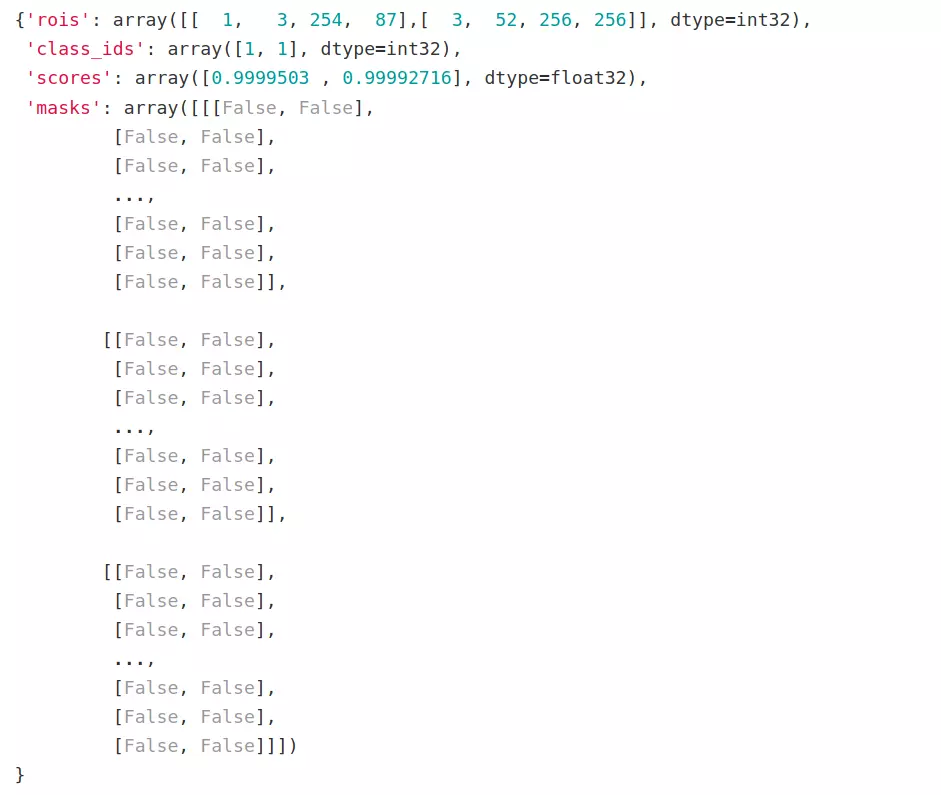
Les résultats de la prédiction sont donnés sous la forme d'un dictionnaire :
- la clé "rois" (regions-of-interest, roi) contient les coordonnées des "bbox" englobant les objets détectés par la prédiction du modèle.
- la clé "class_ids" contient les id des classes détectées. Dans le cadre de notre étude seul les bâtiments sont ciblés par le modèle : les id contenues dans la section "class_ids" sont donc toutes égales à 1.
- la clé "masks" contient des matrices de booléens True/False correspondant à l'image, True si le pixel appartient à l'objet et False si le pixel n'appartient pas à l'objet.
- la clé "scores" contient la probabilité qu'a l'objet détecté d'appartenir à la catégorie.
Nous pouvons observer que les deux bâtiments détectés, bien qu'appartenant tout deux à la même classe d'objet, sont chacun identifiés comme étant des objets indépendants : à chacun des deux bâtiments sont associés une classe, une boite englobante, un masque et un score qui leur sont propres. C'est la particularité de la segmentation d’instance.
Conclusion
Le modèle Mask R-CNN est donc un modèle de deep-learning permettant la segmentation d'instance : les objets ciblés seront détectés et classifiés indépendamment des uns des autres. Son utilisation est relativement simple, et beaucoup de ressources sont disponibles. Une fois les données prêtes et le modèle prêt à être utilisé, le choix des protocoles d’entraînement, c'est à dire quelle méthode adopter pour entraîner le modèle est une question importante. De même que la constitution des jeux de données sur lesquels l’entraîner : un jeu de données mixtes correspondant à des villes différentes, des types de photographies différentes et des niveaux de résolution différentes ou un jeu de données plus homogène correspondant à une seule région par exemple. En effet, il est difficile de connaître en amont ce à quoi le modèle sera sensible, et quelle méthodologie d'entraînement sera la plus efficace pour permettre de répondre à notre objectif : la détection d'objets, celle de toits dans notre cas. C'est donc en analysant les résultats de nos entraînements que nous pourrons définir la méthodologie qui semble la plus adéquate. Une fois le modèle entraîné, il faut donc pouvoir évaluer son efficacité. Nous verrons dans un prochain article sur quels indicateurs se baser pour évaluer les performances de notre modèle.
Si vous souhaitez prolonger ces travaux avec nous dans le cadre d'un stage ou si vous avez besoin d'aide dans le choix d'un modèle de deep-learning, n'hésitez pas à nous contacter!

Responsable Innovation
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningActualités en lien
Extraction d'objets pour la cartographie par deep-learning : évaluation du modèle
Data Science
08/06/2020
Voici le dernier article de notre série sur la cartographie par deep-learning. Après avoir expliqué comment choisir et utiliser un modèle d'extraction d'objets, nous allons maintenant en évaluer les performances. Que pouvons-nous attendre du modèle entraîné ? Quels sont ses limites et ses sensibilités ?

Extraction d'objets pour la cartographie par deep-learning : création d'une vérité terrain
SIG
18/05/2020
Cette série d'articles parle de cartographie par deep-learning à partir d'images aériennes ou satellitaires. Dans ce 1er article, l'étape préliminaire à toute utilisation d'un modèle d'apprentissage supervisé est abordée: la création du jeu de données d'apprentissage. Notre outil geolabel-maker est mis à votre disposition pour vous aider.

Deep Learning et détection d'émotions
Data Science
12/04/2018
Un premier pas dans le Deep Learning pour la détection d'émotions à partir de photographies.
