Makina Blog
Extraction d'objets pour la cartographie par deep-learning : évaluation du modèle
Voici le dernier article de notre série sur la cartographie par deep-learning. Après avoir expliqué comment choisir et utiliser un modèle d'extraction d'objets, nous allons maintenant en évaluer les performances. Que pouvons-nous attendre du modèle entraîné ? Quels sont ses limites et ses sensibilités ?
Dans les articles précédents de cette série, nous avons décrits les deux premières étapes nécessaires à la détection d'objets par deep-learning :
- la création d'une vérité terrain composée de couples (image, label) et/ou des images et d'un fichier d'annotations.
- le choix du modèle, son entraînement à partir d'un jeu de données constitué et son utilisation.
Ces étapes vont influencer l'efficacité du modèle à détecter les objets ciblés. C'est ce que nous allons ici mesurer à l'aide d'indicateurs bien choisis et ainsi analyser l'effet de notre méthodologie. Quels sont les indicateurs permettant d'évaluer notre modèle ? Quelles sont les limites et les avancées qui sont d'ores et déjà observées quant à la détection de nos objets cibles par notre modèle ? Quelles sont les facteurs qui semblent jouer un rôle dans la qualité du modèle et quelles sont les pistes d'améliorations ?
Comment se mesure l'efficacité de notre modèle ?
Les modèles de deep-learning sont évalués en analysant les résultats des prédictions obtenues sur un jeu de données constitué pour la validation au moment de la création de la vérité terrain. Nous comptons notamment les nombres de :
- vrais positifs : le nombre de fois où le modèle prédit correctement la classe positive ;
- vrais négatifs : le nombre de fois où le modèle prédit correctement la classe négative ;
- faux positifs : le nombre de fois où le modèle prédit la classe positive alors que le résultat attendu était la classe négative ;
- faux négatifs : le nombre de fois où le modèle prédit la classe négative alors que le résultat attendu était la classe positive.
Par exemple, si notre modèle prédit la présence de bâtiments dans une image :
Vrai positif Prédiction : bâtiment présent Résultat attendu : bâtiment présent |
Faux positif Prédiction : bâtiment présent Résultat attendu : pas de bâtiment |
Faux négatif Prédiction : pas de bâtiment Résultat attendu : bâtiment présent |
Vrai négatif Prédiction : pas de bâtiment Résultat attendu : pas de bâtiment |
A partir de ces statistiques, deux indicateurs sont généralement calculés : la précision et le rappel.
Précision (precision)
La précision est le pourcentage de détections correctes. Il met en évidence l'exactitude des prédictions. Il se calcule par ce ratio :
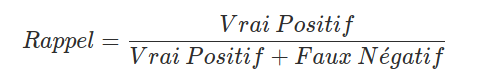
Rappel (recall)
Le rappel est un indicateur qui mesure la capacité du modèle à prédire l'ensemble des résultats attendus. Ainsi, un modèle peut avoir une très bonne précision mais avoir un mauvais rappel. En effet, un modèle peut-être exact lorsqu'il prédit la présence d'un objet, mais ne pas détecter des objets qui aurait du l'être.
Il se calcule ainsi :
Ces indicateurs sont relativement simples à calculer lorsque que la réponse du modèle avec lequel nous travaillons est du type "Vrai" / "Faux". Mais lorsque le travail est effectué avec des modèles de localisation d'objets ou de segmentation sémantique, il est plus difficile de qualifier la prédiction du modèle comme étant "vraie" ou "fausse".
Application aux modèles de localisation d'objets ou de segmentation
Le modèle Mask R-CNN utilisé ici produit en sortie une réponse composée de trois éléments :
- la boite englobante (bounding box) qui localise l'objet dans l'image ;
- le masque correspondant aux pixels appartenant à l'objet ;
- la catégorie de l'objet détecté.
Pour pouvoir évaluer l'efficacité d'un tel modèle à l'aide des indicateurs vus précédemment, il faut être capable de dire quand est-ce qu'une prédiction est "vraie" et quand est-ce qu'une prédiction est "fausse". À priori ce n'est pas quelque chose d'évident.
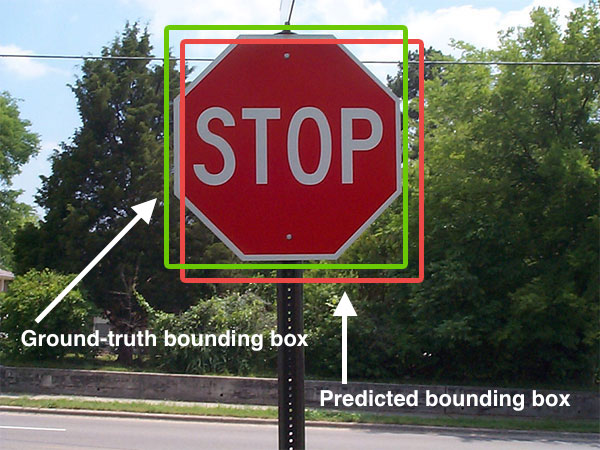
source : pyimagesearch, 2016.
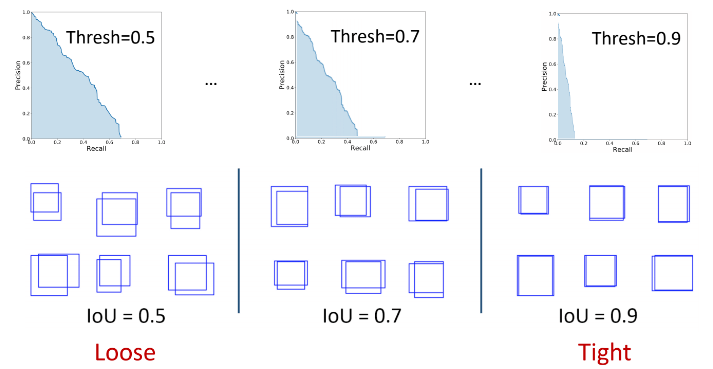
Il est en effet très rare qu'avec ce type de modèle la prédiction corresponde parfaitement au résultat attendu. Nous allons donc avoir besoin de définir un seuil d'acceptabilité du résultat produit par le modèle. Pour cela, nous allons calculé le recouvrement qui existe entre le résultat prédit et le résultat attendu via un nouvel indicateur appelé Intersection Over Union (IoU).
Intersection Over Union (IoU)
L'IoU permet de comparer la région détectée “prédite” avec la région de la vérité terrain, de manière proportionnelle à la taille de l'objet recherché.
Les régions comparées peuvent être les boîtes englobantes ou les masques, selon l'évaluation recherchée :
la comparaison des boîtes englobantes permettra de mesurer la qualité de la détection d'objets alors que celle des masques permettra de mesurer la qualité de la segmentation.
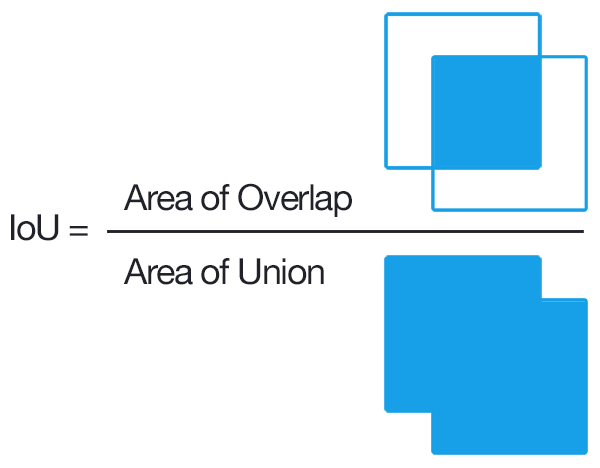
source : pyimagesearch, 2016.
À partir de cette mesure, un seuil de tolérance acceptable va être défini qui permettra de déterminer si la prédiction est correcte ou non.
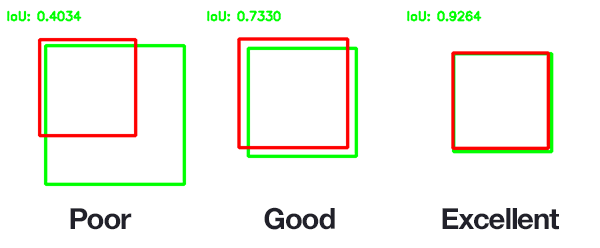
Le seuil minimal utilisé pour déterminer si la prédiction est bonne est de 0.5 : c'est-à-dire que si les deux régions, celle prédite et celle de la vérité terrain, se recouvrent à plus de 50 %, nous considèrons que la réponse du modèle est bonne. Cela correspond à un IoU équivalent à 0,5.
C'est donc l'IoU qui va déterminer si une prédiction est :
- vraie positive, c'est-à-dire que l'objet est correctement détecté ;
- fausse positive, c'est-à-dire qu'un objet est détecté alors qu'il n'est pas présent dans la vérité terrain ;
- fausse négative, c'est-à-dire que le modèle ne détecte pas d'objet alors qu'il y en a un présent dans la vérité terrain.
Et nous pouvons ainsi ensuite calculer la précision et le rappel de notre modèle comme vu précédemment.
Mean Average Precision (mAP)
À partir de l'ensemble de ces indicateurs, il est maintenant possible de tracer la courbe de précision en fonction du rappel (PR). Elle va permettre, grâce au calcul de l'aire sous cette courbe, de définir l'Average Precision (AP) du modèle. La moyenne de la précision moyenne est obtenue (mean Average Precision, mAP) en faisant la moyenne de toutes les AP sur l'ensemble des classes recherchées par le modèle.
Si plusieurs valeurs sont choisies pour le seuil de l'IoU, pour chaque classe, l'AP moyenne est calculée sur l'ensemble de ces valeurs seuils et la moyenne des valeurs obtenues donne le mAP.
Il est à noter que le mean Average Recall (mAR) est lui aussi un indicateur utilisé. De façon similaire au calcul du mAP, il est obtenu à partir de l'aire sous la courbe Recall - IoU.
Premières prédictions et observations
Dans l'article précédent, nous vous avons montré comment entraîner notre modèle et réaliser des prédictions. Il est possible d'observer en quelques prédictions effectuées sur nos données les améliorations obtenues. Dans cet exemple, où la première image est le résultat de la prédiction par un modèle non entraîné avec notre vérité terrain et la seconde celle du résultat du modèle entraîné, nous pouvons voir que les masques associés aux deux bâtiments détectés sont plus précis.
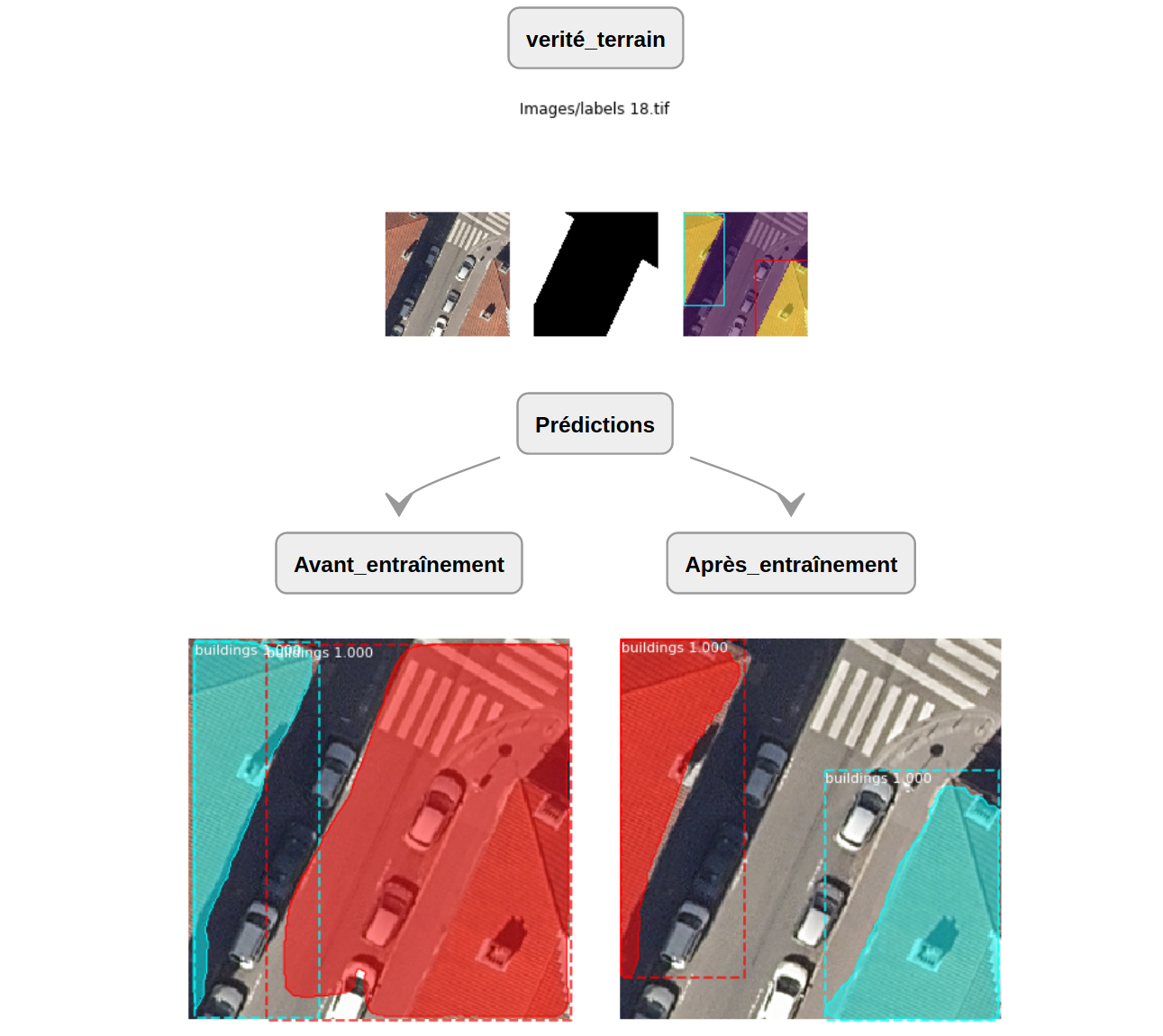
Nous observons donc que lors de l'entraînement, le modèle a appris à mieux détecter les bâtiments présents sur les images de nos jeux de données.
Évaluation du modèle
Ce notebook présente comment réaliser une évaluation : Evaluation_Mask-RCNN
L’évaluation du modèle va permettre de lancer un ensemble de prédictions sur un lot d'images (non utilisées pour l'entraînement du modèle, voir la constitution du jeu de données détaillée dans l'article précédent). Pour chaque image, la prédiction sera comparée à la vérité terrain contenue dans le fichier d'annotations au format COCO (que nous avons généré à l'aide de notre outil geolabel-maker). Dans le cadre de notre étude, nous cherchons à localiser les bâtiments d'une image, l'évaluation va donc permettre de comparer les masques prédits avec ceux de la vérité terrain.
Pour l'évaluation, nous utilisons les fonctions issues de l'exemple coco de l'implémentation de Mask R-CNN :
evaluate_coco()build_coco_results()
Résumé simplement, la fonction evaluate_coco() permet d'effectuer une prédiction pour chaque image d'un lot d'images.
Chaque prédiction est transformée au format COCO grâce à la fonction build_coco_results() à laquelle elle fait appel.
Toutes les prédictions sont compilées et comparées à la vérité terrain contenue dans le fichier d'annotations.
La mAP est ensuite calculée pour différents seuils d'IoU.
La fonction evaluate_coco() utilisée pour évaluer le modèle Mask R-CNN dans le cadre du COCO Challenge permet donc d'évaluer notre modèle entraîné. Le paramètre eval_type permet de définir sur quoi nous voulons évaluer notre modèle et l'option "segm" permet d'évaluer le modèle sur les résultats de segmentation (l'option "bbox" permet de réaliser une évaluation similaire mais sur les boîtes englobantes (bounding boxes)).
Les autres paramètres important sont les suivants :
model, le modèle à évaluer ;dataset, le jeu de données initialisé avec la classe de configuration de notre jeu de données ;coco, la vérité terrain correspondant aux annotations initialisées de même avec la classe de configuration de notre jeu de données ;limit, qui permet de définir sur combien d'images l’évaluation va être réalisée.
La commande pour lancer l'évaluation (ici sur 1000 images) est la suivante :
evaluate_coco(model, dataset_val, val_coco, eval_type="segm", limit=1000)
Le résultat en sortie est de cette forme :
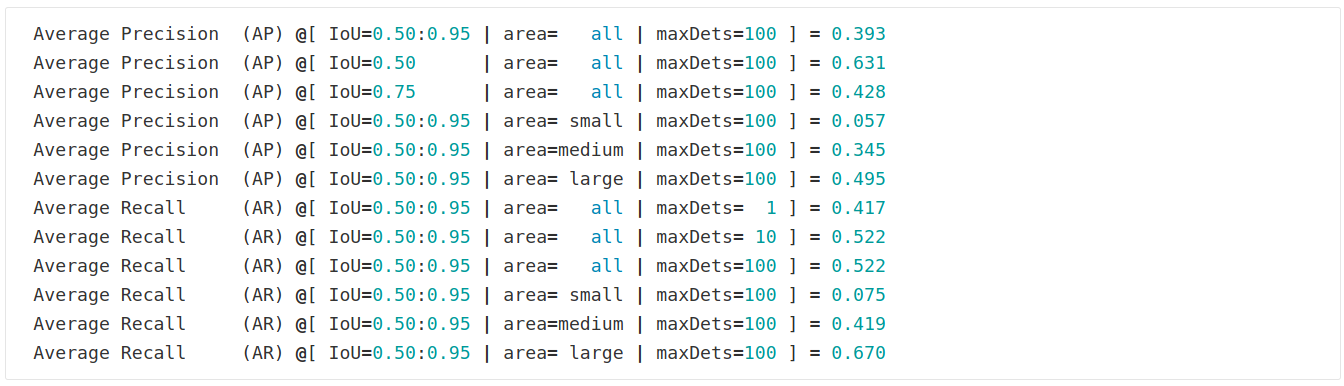
Il donne le calcul du mAP (noté AP) pour différents seuils d'IoU (compris en 0.5 et 0.95), mais indique aussi la performance du modèle selon la taille des objets détectés : "all" prend en compte toutes les tailles de masques et ensuite les masques sont catégorisés en trois groupes "small", "medium" et "large".
De même, le calcul du mAR (noté AR) est donné pour les différentes tailles de masques ("all", "small", "medium" et "large").
De plus, ces deux indicateurs sont aussi calculés selon le nombre maximum d'objets détectés dans l'image (maxDets).
Ces différents critères permettent d'avoir une vison plus fine de la performance du modèle et de son comportement.
Quels facteurs semblent avoir un rôle dans le comportement du modèle ?
Entraînement du modèle
Effet de l'apprentissage
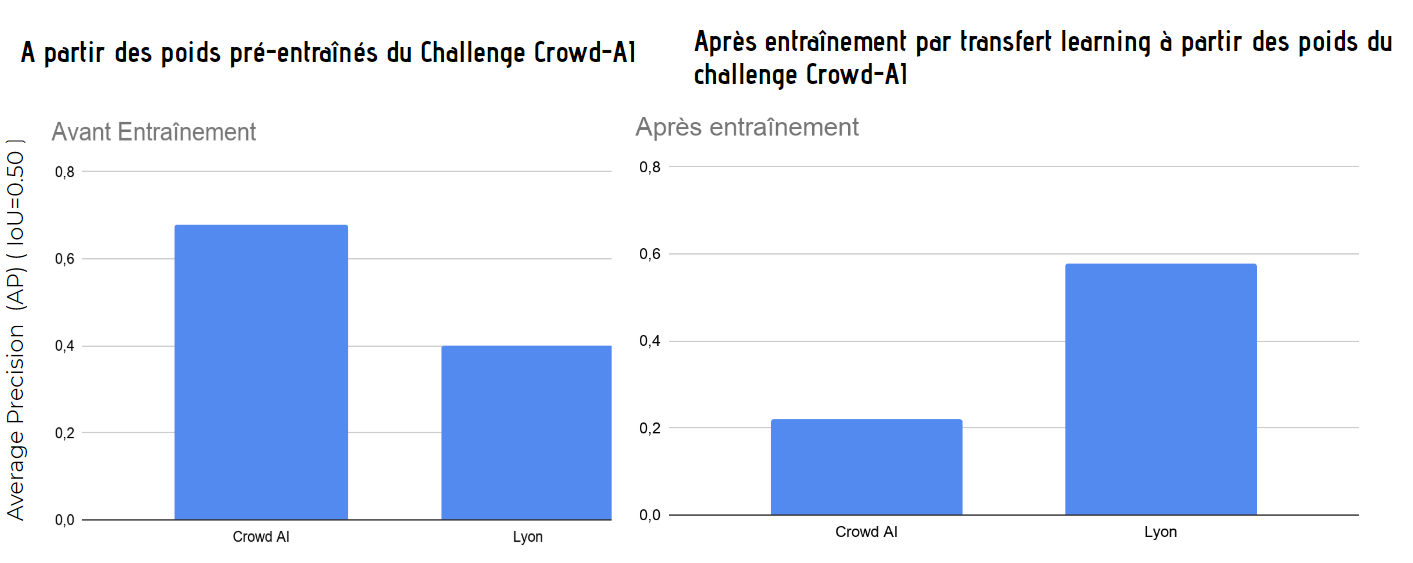
Des évaluations ont été effectuées sur le jeu de données du Challenge Crowd-AI et un jeu de données de validation issu des données de la métropole de Lyon (extrait de la vérité terrain construite à l'aide de notre outil geolabel-maker). Nous utilisons le modèle pré-entraîné du challenge Crowd-AI d'une part et notre modèle ré-entraîné par transfert learning d'une autre part.
En comparant les résultats, nous observons que l'entraînement réalisé a réussi à rendre le modèle plus performant sur les données de Lyon.
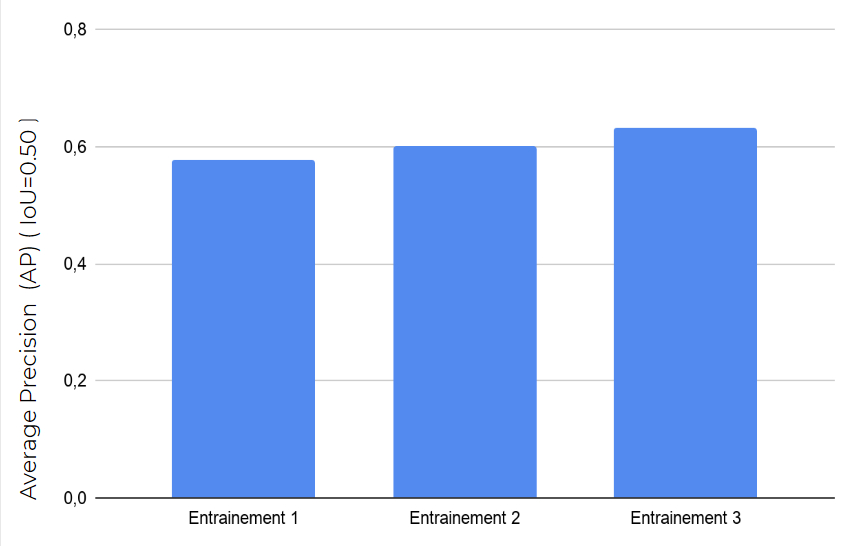
Effet de la méthode d’entraînement
Le modèle Mask R-CNN a été entraîné selon trois méthodes, toujours par transfert learning à partir de poids pré-entraînés issus du challenge Crowd-AI.
Entraînement 1 : Il est réalisé en 3 étapes (ce protocole a été présenté dans l'article précédent) uniquement sur des données de la métropole de Lyon :
- entraînement des premières couches (en 40 époques)
- entraînement des couches supérieures (en 120 époques)
- entraînement de toutes les couches (en 160 époques)
Entraînement 2: Il n'est réalisé qu'en 1 étape uniquement toujours sur les données de la métropole de Lyon :
- entraînement de toutes les couches (en 160 époques)
Entraînement 3 : Il est à nouveau réalisé en 1 étape sur un jeu de données mêlant des données de la métropole de Lyon, de données de la métropole de Nantes et un jeu de données proposé par l'INRIA pour des villes américaines :
- entraînement de toutes les couches (en 160 époques)
A la suite de chacun de ces entraînements, l'efficacité du modèle obtenu a été évaluée sur un jeu de données de validation issu des données de la métropole de Lyon (différent de celui utilisé pour l'entraînement). Des différences de performances sont observées selon la méthodologie utilisée : le modèle entraîné sur des données mixtes semble plus robuste et un entraînement en plusieurs étapes ne semble pas améliorer les performances du modèle.
Autres facteurs
Si les protocoles d'entraînements rendent plus ou moins performant le modèle, nous avons observé au fil des évaluations et prédictions réalisées sur nos données que le modèle pouvait être sensible à certains autres facteurs, ce qui influencerait directement la qualité de la prédiction.
Résolution spatiale
Un de ce facteur est la résolution spatiale. En effet, dans cet exemple utilisant un modèle ayant notamment été entraîné sur des données au niveau de zoom 19 et au niveau de zoom 18, nous observons que plus le niveau de zoom diminue, plus la qualité des prédictions se dégrade. Au zoom 17, tout un ensemble de bâtiments est occulté par le modèle, par exemple, alors qu'au zoom 20, la correspondance entre le bâtiment de la vérité terrain et le masque de la prédiction est élevée.

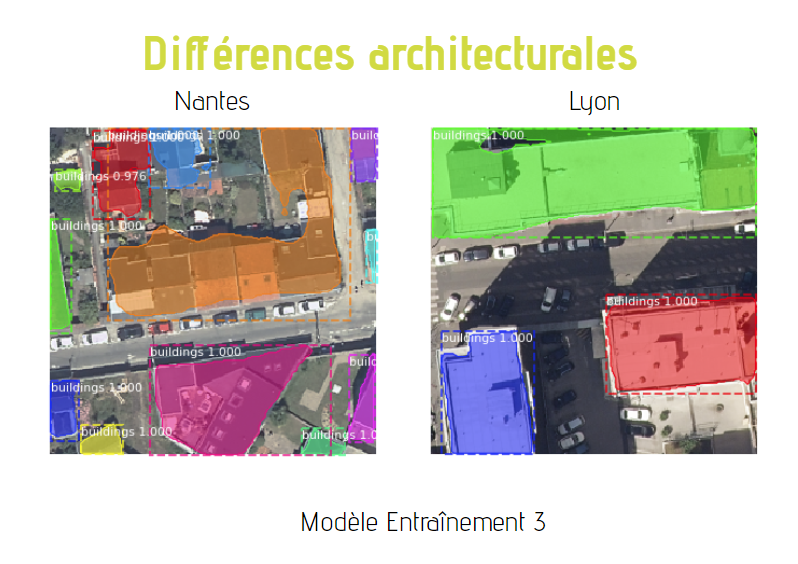
Différences architecturales
Une autre des limites de notre modèle pourrait être sa spécialisation sur un style architectural. En effet, nous avons remarqué qu'il a plus de facilités à détecter certains types de toits plutôt que d'autres. Dans cet exemple, la prédiction correspondant à la ville de Nantes a été réalisée sur une image où certains bâtiments ont une toiture en pente et en ardoises (grises), et celle de la ville de Lyon sur une image où les bâtiments disposent de toits terrasses. Nous observons que la correspondance entre le bâtiment de la vérité terrain et le masque de la prédiction est plus élevée quand il s'agit de toits terrasse (présents dans les deux images).
Ombres
Lors de nos premières prédictions avec le modèle pré-entraîné du challenge Crowd-AI, les ombres apparaissant sur les images dégradaient la capacité du modèle à réaliser de bonnes prédictions. En effet, comme nous pouvons l'observer dans cette exemple, la partie lumineuse de la route a été attribuée au bâtiment situé à droite de l'image. Ce comportement a été observé sur de nombreuses images où des ombres étaient présentes. En revanche, après ré-entraînement de notre modèle avec notre vérité terrain (qui comportait des images ayant des zones d'ombre), l'ombre ne semble plus perturber la prédiction faite par le modèle.

Conclusion
L'entraînement du modèle Mask R-CNN avec nos données de vérité terrain a montré la capacité du modèle à apprendre, comme le montre notamment l'augmentation de la précision des masques prédits.
Des pistes d'améliorations sont cependant possibles :
- Nous avons observé que la méthodologie utilisée pour entraîner le modèle influençait sont efficacité :
d'autres protocoles d’entraînement pourraient encore être testés afin d'établir la meilleure stratégie à adopter. - De même, un entraînement sur un jeu de données mixtes donne de meilleurs résultats : enrichir notre vérité terrain avec des images de sources plus hétéroclites pour l'apprentissage du modèle pourrait permettre d'obtenir un modèle plus robuste dans la détection de bâtiments. Au delà, de l'enrichissement du jeu de données, l'optimisation de la correspondance entre les images et leurs labels - donc la qualité de la labellisation - peut aussi être un axe d'amélioration.
- Enfin, un pré-traitement des images pourrait éliminer certains facteurs influençant la qualité du modèle : la suppression des ombres par exemple.
Si vous souhaitez prolonger ces travaux avec nous dans le cadre d'un stage ou si vous avez besoin d'aide dans l'évaluation d'une solution de deep-learning, n'hésitez pas à nous contacter .
Articles de la série
Série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires :
Article 1 : création de la vérité terrain
Article 2 : choix du modèle

Responsable Innovation
Formations associées
Formations Python
Formation Python pour l'analyse géospatiale
A distance (FOAD) Du 14 au 18 septembre 2026
Voir la Formation Python pour l'analyse géospatialeFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningActualités en lien
Geotrek 2025–2026 : nouvelles fonctionnalités et grands chantiers à venir
Logiciel libre
27/05/2026
Extraction d'objets pour la cartographie par deep-learning : choix du modèle
SIG
02/06/2020
Deuxième article de la série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires.

Extraction d'objets pour la cartographie par deep-learning : création d'une vérité terrain
SIG
18/05/2020
Cette série d'articles parle de cartographie par deep-learning à partir d'images aériennes ou satellitaires. Dans ce 1er article, l'étape préliminaire à toute utilisation d'un modèle d'apprentissage supervisé est abordée: la création du jeu de données d'apprentissage. Notre outil geolabel-maker est mis à votre disposition pour vous aider.
