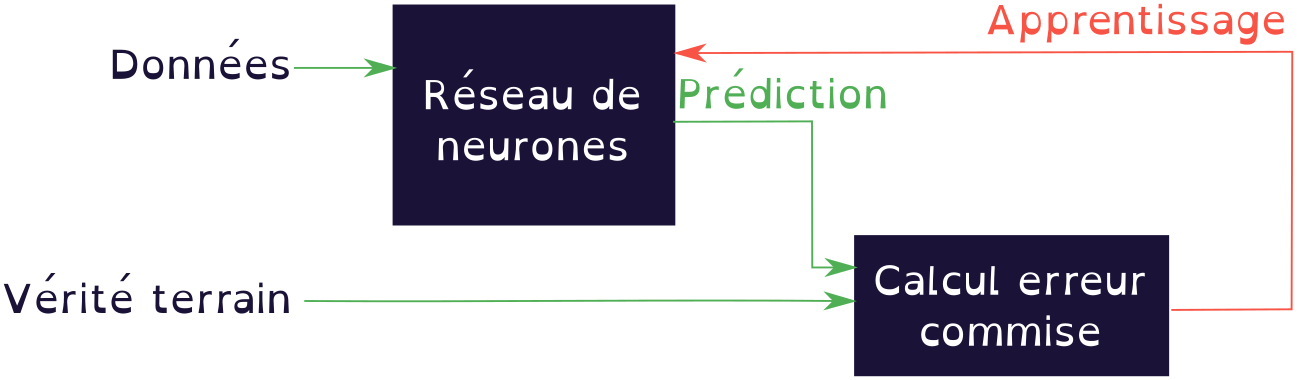
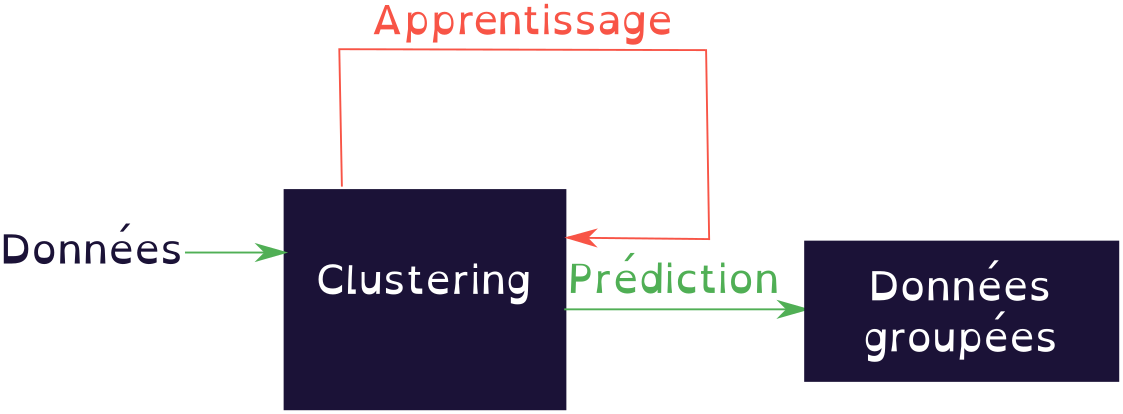
MLflow est un outil sous licence libre dont l'objectif est d’industrialiser de bout en bout les projets de Machine Learning, de la phase recherche à la mise en production. Actuellement nous étudions son intégration au sein de nos processus métiers.
MLflow se fixe deux objectifs :
- permettre la mise en production rapide et simple de modèles provenant de différentes bibliothèques (par exemple Scikit Learn et Tensorflow) ;
- permettre un suivi détaillé de la phase de design des modèles, facilitant notamment la reproductibilité des expériences menées.
C'est dans le cadre de cette deuxième problématique que nous l'avons utilisé, en nous limitant à ses fonctionnalités de tracking.
Après avoir importée la bibliothèque Python MLflow, nous lançons un **run** au niveau du point d'entrée principale de notre script Python :
with mlflow.start_run():
pass
Un run correspond généralement à une expérimentation menée. Dans notre cas il s'agit de l’entraînement de la méthode Deep Clustersur un ensemble de données. Lors d'un run, MLflow enregistre des paramètres et des métriques. Les paramètres sont des caractéristiques fixes de l'expérimentation. Dans notre cas nous avons par exemple :
with mlflow.start_run():
mlflow.log_params({
'nb_clusters': args.nb_clusters,
'data_directory': args.data_directory,
'models_directory': args.models_directory,
'nb_steps': args.nb_steps
})
Pour chaque expérimentation nous aurons donc accès au nombre de groupes demandés à l'algorithme de clustering, aux données utilisées, au répertoire où sont sauvegardés les réseaux de neurones obtenus après chaque itération et au nombre d'itérations réalisées par Deep Cluster. Nous pouvons ainsi facilement reproduire l'expérience.
Tout au long de l'expérimentation, grâce à MLflow, nous allons également enregistrer des métriques qui évoluerons au fil des itérations. Nous sauvegardons par exemple l'exactitude (accuracy) et le résultat de la fonction de coût (loss) obtenus par le réseau de neurones à la fin de chaque époque, et ce, pour les données d’entraînement comme pour celles d'évaluation.
mlflow.log_metrics({
'train_loss': res_train[0],
'train_acc': res_train[1],
'ctrl_loss': res_ctrl[0],
'ctrl_acc': res_ctrl[1]
})
MLflow fournit une application web facilitant la consultation des paramètres et métriques associés à chaque expérimentation. Elle se lance en ligne de commande :
mlflow ui
La figure 4 montre ce que nous obtenons après deux expérimentations :
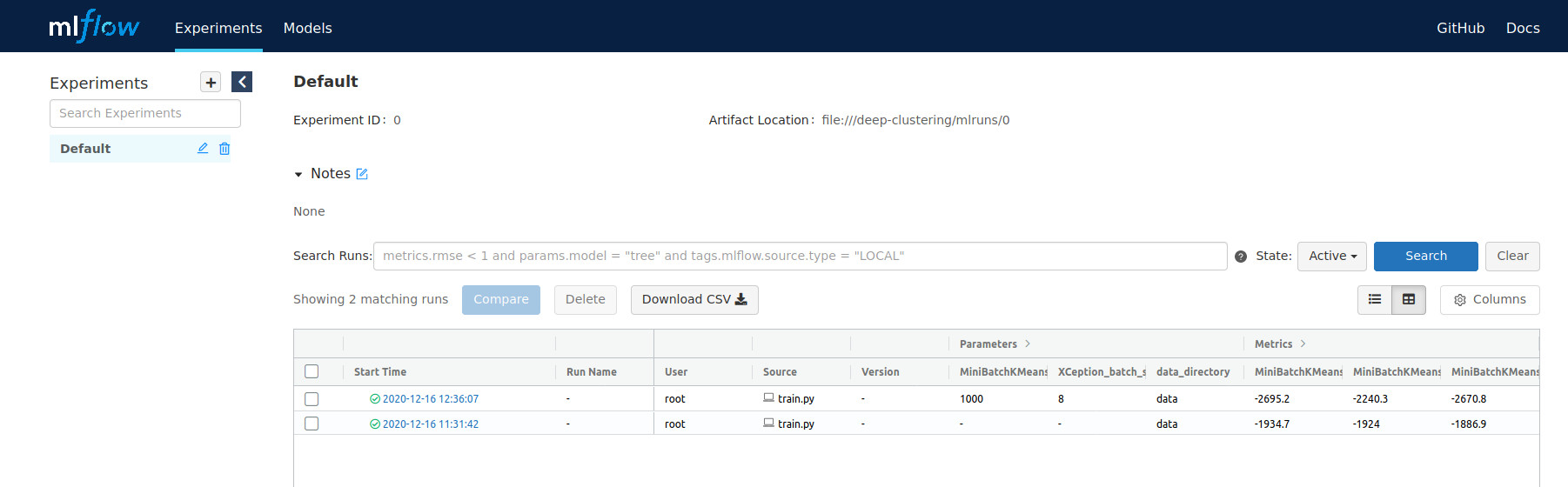
Figure 4 : interface de MLflow
Deux runs sont accessibles. Pour chacun d'entre eux, MLflow nous fournit les moyens de visualiser l'évolution d'une ou plusieurs métriques sur des graphiques adaptés.
Suivi de la progression de l'algorithme avec MLflow
Nous avons choisi de nous intéresser à trois types de métriques afin d'analyser la progression de DeepCluster durant l'entraînement :
- un score de performance pour la méthode de clustering : l'opposé des distances inter-groupes élevées au carré ;
- un score de performance pour le réseau de neurones : l'exactitude (en anglais accuracy) ;
- le nombre d'images associées à chaque groupe.
L'opposé des distances inter-groupes élevées au carré correspond à l'opposé de la distance moyenne entre le descripteur de chaque image et le centre du groupe auquel l'image est associée par l'algorithme de clustering. Il s'agit d'un score négatif qui tend vers 0 lorsque les groupes sont denses, i.e que les descripteurs forment un ensemble compact autour du centre du groupe. Comme l'amélioration du descripteur généré par le réseau de neurones permet à l'algorithme de clustering de produire des groupes plus homogènes, nous devrions voir ce score s'approcher de zéro tout au long des 10 étapes.
La figure 5 présente les résultats obtenus. Pour des raisons de capacités mémoires, les données ne sont pas présentées en un seul bloc à MiniBatchKMeans mais au travers de 7 lots contenant chacun un millier d'images.
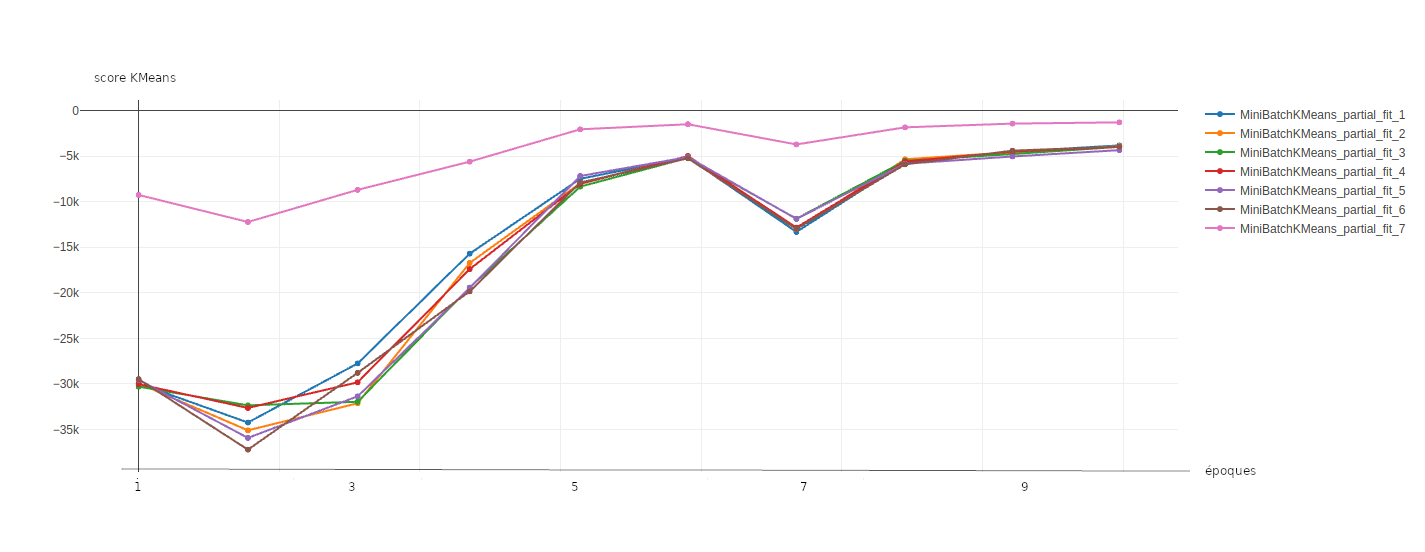
Figure 5 : évolution du score de l'algorithme MiniBatchKMeans sur les différents lots de données qui lui sont transmis.
Si les scores peuvent varier d'un lot à l'autre, tous suivent la même tendance. Durant les dernières étapes de l'entraînement de MiniBatchKMeans les scores se stabilisent autour de -4 000.
La figure 6 présente l'évolution du score d'exactitude obtenu par le réseau de neurones sur les données de validation (des données qui n'ont été utilisées ni pour l'apprentissage de l'algorithme de clustering ni pour celui du réseau de neurones) et les données d'apprentissage. Le score d'exactitude mesure l'adéquation entre la classe prédite par le réseau de neurones et la classe de la vérité terrain. Ce score tend vers 1 lorsque les résultats du réseau rejoignent la vérité terrain.
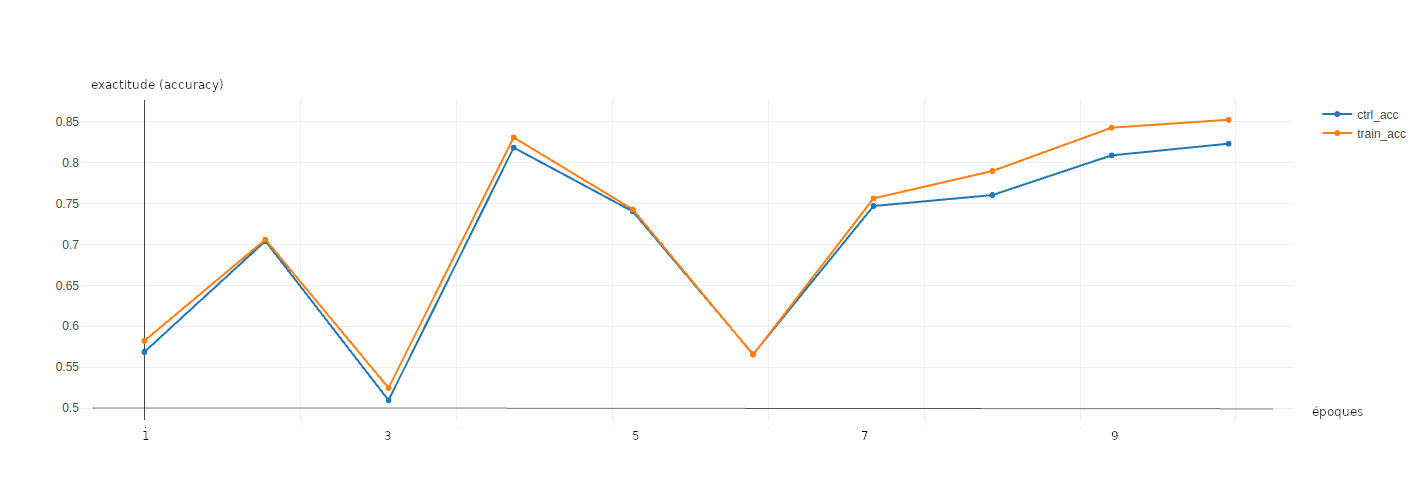
Figure 6 : évolution de l'exactitude (accuracy) sur les données de validation.
Ce score est optimale lors des dernières itérations avec une valeur supérieure à 0,8.
Enfin les figures 7 et 8 montrent l'évolution du nombre de données par groupe, au cours des itérations. Il est notable de constater que les déséquilibres entre les groupes tendent à se réduire entre les itérations 6 et 8, pour les données d’entraînement comme pour les données de validation. Lors des dernières itérations les déséquilibres entre les labels réapparaissent.
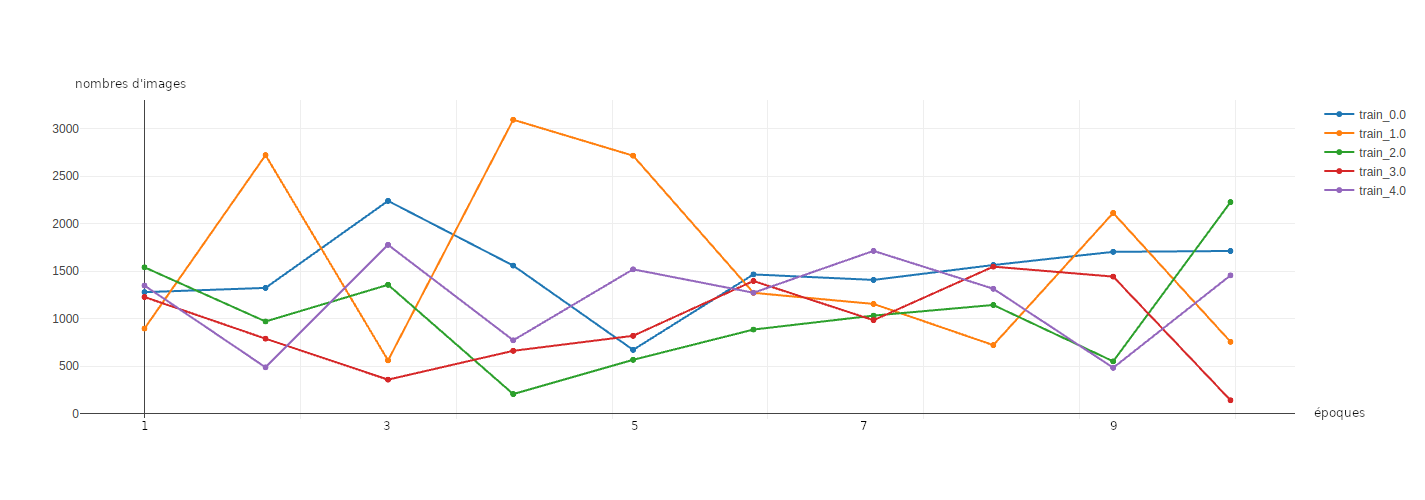
Figure 7 : évolution du nombre d'images d’entraînement pour chacun des groupes.
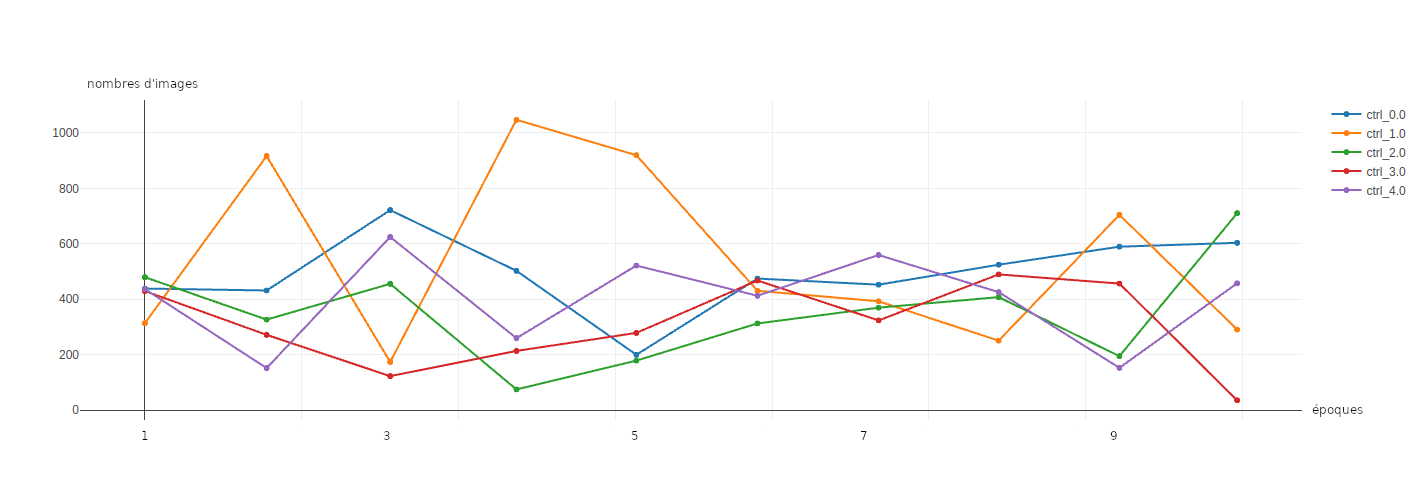
Figure 8 : évolution du nombre d'images de validation pour chacun des groupes.
Résultats et perspectives
Les figures 9, 10 et 11 correspondent à des images issues de trois clusters obtenus avec l'algorithme MiniBatchKMeans et le réseau de neurones XCeption à l'issu des 10 itérations de la méthode Deep Cluster. Durant la phase d'entraînement, Deep Cluster était paramétré pour produire 5 groupes. Nous nous assurions ainsi que lors de la phase de deep-learning, le réseau de neurones disposait d'un nombre suffisant d'images pour chaque groupe. Une fois l'entraînement terminé, afin de produire des résultats exploitables, il est souhaitable d'augmenter le nombre de groupes et de produire une sur-segmentation des images. Parmis les groupes obtenus, plusieurs pourront être fusionnés. Nous avons donc choisi d'organiser les images en 20 groupes.
Les figures 9, 10 et 11 correspondent à des images issues de trois de ces groupes. Les pondérations du réseau de neurones sont celles obtenues à la 10 eme itération. Les images sont décrites avec ce réseau, puis groupées en 20 ensemble avec MiniBatchKMeans.

Figure 9 : photographies aériennes rattachées au même ensemble.

Figure 10 : photographies aériennes rattachées au même ensemble.
Figure 11 : photographies aériennes rattachées au même ensemble.
Les groupes obtenus sont visuellement homogènes et correspondent à des paysages distincts. Utilisée directement, la méthode DeepCluster constitue donc un moyen efficace d'organiser automatiquement les quelques milliers d'images récoltées, ce qui facilite leur analyse. Lors de futur travaux nous aimerions nous concentrer sur les caractéristiques que le réseau de neurones retient pour chacun des groupes. Nous pourrions ainsi obtenir des couleurs, formes ou textures typiques de certains types de paysage.
Conclusion
L'implémentation réalisée par nos équipes de l'algorithme DeepCluster obtient des résultats similaires à ceux de Mathilde Caron et al. pour des données pourtant assez éloignées de celles d'Imagenet. Elle nous fournit, entre autre, un outil pertinent pour nos projets en lien avec les observatoires du paysages. Pour le moment le prototype développé se contente d'organiser les photographies. Nous souhaitons le faire évoluer pour qu'il nous aide à mieux caractériser les paysages en extrayant les propriétés visuelles qui leurs sont spécifiques.
Si vous souhaitez en apprendre davantage sur l'apprentissage non-supervisé et le deep-learning, jetez un oeil à nos formations.
Nous serons également ravie de tester notre version de Deep Cluster sur vos images, donc n'hésitez pas à nous contacter.