Makina Blog
SIG : Préparation de données pour la création de tuiles vectorielles
Pour servir des données sous forme des tuiles vectorielles une préparation est nécessaire comme le filtrage et la simplification des géométries. Quelles sont les questions à se poser ? Quels sont les outils pour y répondre ?
Une tuile vectorielle, c'est quoi ?
Les tuiles vectorielles sont des morceaux de cartes contenant les données nécessaires à la représentation d’une zone. Cette technique permet de faire transiter sur Internet uniquement les parties de cartes qui nous intéressent et de leur appliquer un style au dernier moment sur le navigateur web. L’avantage de cette approche est d’avoir moins de données à transférer sur le réseau. Le rendu est également fait au dernier moment, le style peut donc être variable et dynamique. L’aspect vectoriel permet entre autres une certaine interactivité sur les données et des effets graphiques comme : la mise en surbrillance d’éléments, la rotation, l’inclinaison, un zoom continu entre les différents niveaux de détails, etc.
Visuel 1 - Données brutes d'une tuile vectorielle
Produire des tuiles vectorielles "correctement"
Les tuiles vectorielles offrent une grande flexibilité pour l’affichage de contenus. Cette partie présente les détails sur la préparation de données pour la génération de tuiles vectorielles.
De nombreux facteurs sont à prendre en compte comme :
- le découpage des données selon l'emprise de la tuile
- le filtrage et la simplification des géométries
Selon le choix des outils - Tippecanoe, t-rex, ST_AsMVT( ) de PostGIS - ces étapes (le découpage, le filtrage…) sont implémentées plus ou moins explicitement. Toutefois c'est intéressant d'avoir connaissance des problématiques pour s'orienter vers l'outil le plus adapté au besoin, de déterminer les paramètres, ou encore de mieux comprendre les résultats obtenus.
Adapter les données aux tuiles vectorielles
L'idée maîtresse pour la production de tuiles vectorielles peut se résumé par "le mieux est de faire simple". De plus, un grand volume de données entraîne des surcoûts.
La limite de taille par tuile établie par Mapbox est de 500 Ko, même si techniquement cette contrainte peut être dépassée. Cette limitation répond à une nécessité de performance, son respect est préférable. Plusieurs couches de données sont utilisées dans une même tuile, l'ensemble doit respecter cette limite.
L'excès de données peut venir du côté attributaire autant que du côté géométrique. L'objectif est de générer des tuiles les plus légères possibles en répondant aux besoins d'affichage et d'interaction en conservant les données pertinentes.
Les techniques disponibles pour répondre à ce besoin sont exposées plus tard dans l'article. Tout d'abord, quels sont les différents paramètres influençant la production des tuiles ?
Les paramètres de définition d'une tuile
Une tuile représente une portion carrée de la carte :
- à un niveau
- à une certaine échelle
- à une position X (lon) pour la localiser
- à une position Y (lat) pour les coordonnées de la tuile
- Z pour son niveau de zoom
Ces coordonnées désignent simplement la case dans une grille découpant la carte du monde.
De ces paramètres, la déduction des coordonnées géographiques de la zone - bounding box - ainsi que l'échelle est possible. La résolution de la tuile peut alors être définie. Elle est en mètres par pixel affiché.
Pour éviter des problèmes d'affichage sur les objets à cheval sur plusieurs tuiles, une zone tampon supplémentaire (buffer) autour de la zone géographique que représente la tuile doit être conservée. Comme ce buffer est utilisé à des fins d'affichage, sa définition est en pixels. Ensuite, il est converti en unité géographique pour recalculer la zone géographique étendue.
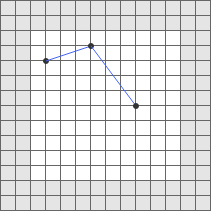
Visuel 2 - Grille d'une tuile vectorielle avec sa zone buffer autour, source: spécification Mapbox
Ces paramètres étant liés entre eux, il est envisageable d'écrire nous-même les fonctions pour les calculer et les mettre en relation. Mais, il serait dommage de ne pas nous servir de bibliothèques libres déjà existantes, comme mercantile (en Python, de Mapbox) ou globalmaptiles (bibliothèques en Python et de MapTiler, utilisée par le paquet pyspatial). Elles permettent de projeter des coordonnées latitude/longitude en coordonnées Web Mercator utilisées par les tuiles, ainsi que de calculer la taille des pixels pour un niveau de zoom en fonction de la résolution de la tuile. Par exemple, le serveur de tuiles t-rex calcule déjà ces paramètres et les introduit comme variable dans les requêtes SQL qui servent à extraire les données dans une base de données.
Traitement des attributs
Filtrer les données par nature
Le niveau de détail de la carte va dépendre du niveau de zoom auquel il s'affiche. La sélection des objets selon leurs natures est pertinente, pour afficher seulement ceux nécessaires à un certain niveau de détail. Par exemple à faible zoom, seules les frontières et les routes seront représentées, mais pas les numéros de rues ou les fontaines.
Ainsi, Il convient de filtrer les objets par nature en fonction du niveau de zoom des tuiles. Cela permet à la fois d'incorporer uniquement les objets nécessaires et d'alléger grandement le contenu des tuiles.
Hiérarchiser, filtrer par attributs
C'est intéressant de pouvoir représenter différents sous-types de données selon l’échelle de la carte. Ceci peut se faire par la combinaison de plusieurs couches par exemple :
- pour les limites administratives, entre les zooms 6 et 8 pour afficher les régions françaises
- puis les départements entre les zooms 9 au 12
- et les communes à partir du zoom 13
Pour le réseau routier :
- dans un premier temps, on affiche les autoroutes
- puis on ajoute successivement au fur et à mesure que l'on zoome : les nationales, les départementales, les voies communales, les chemins, etc.
Cette hiérarchisation peut se faire par appréciation des niveaux de zoom de façon subjective. Pour vous aider dans vos choix, quelques sites permettent d'avoir un aperçu visuel de la correspondance entre niveaux de zoom et emprises géographiques : maptiler ou encore what the tile.
Sélectionner les attributs
Une couche de données cache parfois une longue liste d'attributs. Il est conseillé de conserver uniquement ceux qui sont nécessaires, toujours dans le but d'avoir des tuiles les plus légères possibles.
Exemple pour illustrer le gain de ce traitement :
Une étude démographique simple doit être réalisée afin de connaître le nombre d'hommes et de femmes ainsi que de personnes majeurs ou non à l'échelle des communes françaises. Ces informations sont disponibles sur le site de l'INSEE qui regroupe des données sur l'activité économique des communes. La quantité d’attributs de ce jeu de données est très importante et le fait de supprimer ces informations excédentaires permet de gagner 12.9 Mo sur les 14.4 Mo du fichier de base.
|
|
Nombre d’attributs | Taille |
|---|---|---|
| Ensemble du jeu de données INSEE | 101 | 14.4 Mo |
|
Informations nécessaires |
6 | 1.5 Mo |
La séléction de la part pertinente des attributs est donc souhaitable !
Traitement des géométries
Une fois la table d'attributs traitée, il faut également se poser la question des géométries. Par exemple, l'affichage du tracé de la ligne de côte de façon très détaillée n'est pas indispensable si les détails ne se distinguent pas. Cette question concerne le niveau de détail des données à afficher en fonction du niveau de zoom, ainsi que de leur représentation.
Simplification des géométries
Après avoir choisi les niveaux de zoom par jeu de données et attributs, il faut aligner ces géométries avec le niveau de détail de leur représentation. Cette procédure dépend de la nature des géométries : points, lignes ou polygones.
Cas des lignes et polygones
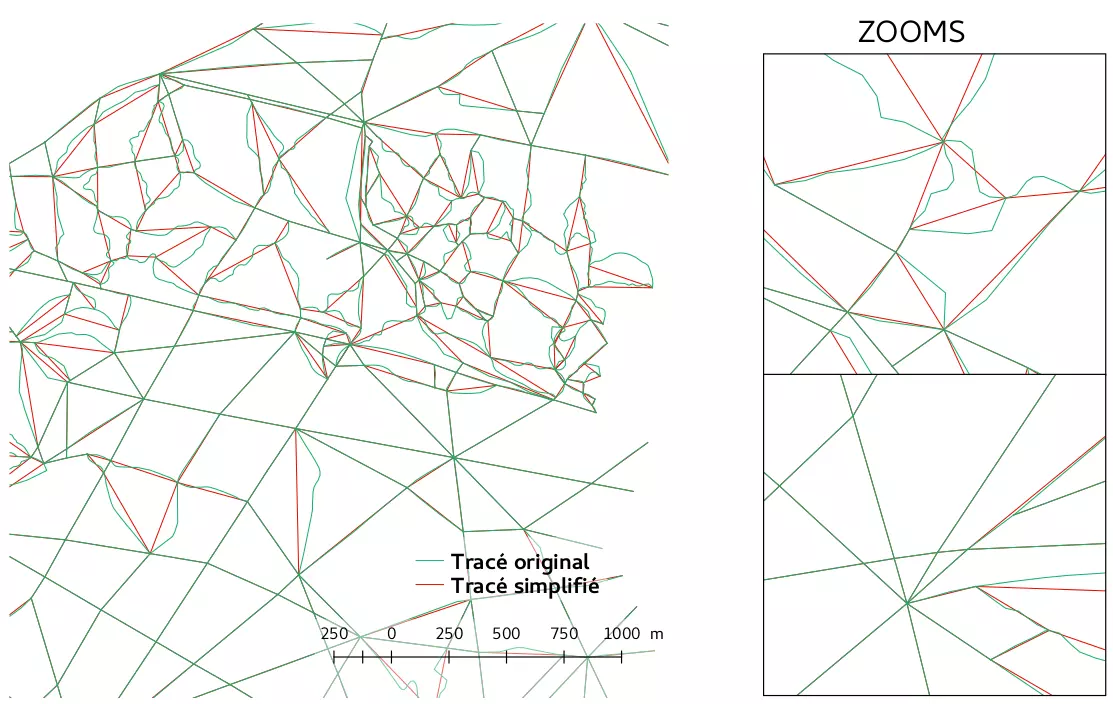
Plusieurs fonctions PostGIS permettent de faire facilement de la simplification :
- ST_Simplify( ) : retourne les géométries simplifiées selon une distance de tolérance, d'après l'algorithme de Douglas-Peucker
- ST_SimplifyPreserveTopology( ) : fait la même chose que ST_Simplify mais éviter de retourner des géométries invalides
- ST_SimplifyVW( ) : retourne les géométries simplifiées selon une distance de tolérance, d'après l'algorithme de Visvalingam-Whyatt
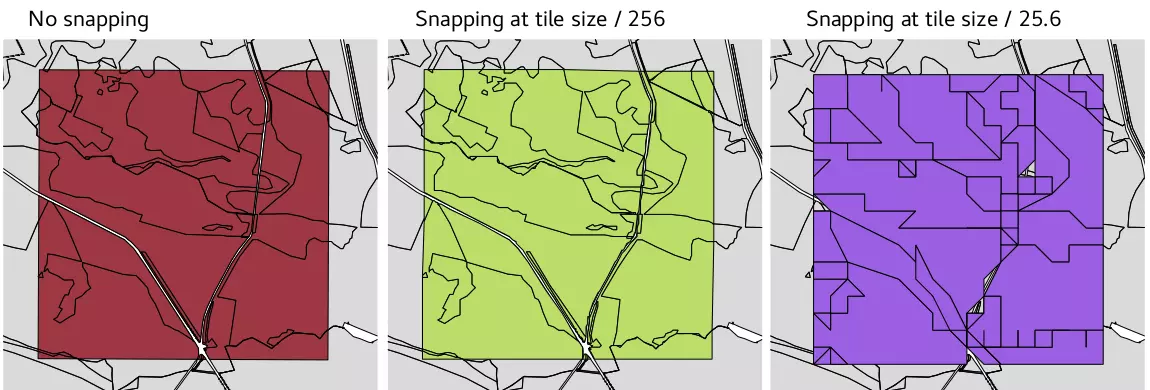
- ST_SnapToGrid( ) : déplace chaque nœud de la géométrie pour les aligner sur une grille, mais ce n'est pas vraiment une simplification.
ST_SnapToGrid s'avère très simple, car les tuiles sont en fait une grille discrète où seule les valeurs entières sont possibles. De plus à la différence des autres possibilités, elle préserve l'adjacence des arêtes bien que pouvant modifier la topologie.
Exemple visuel avec des grilles de différents pas
Toutes les méthodes de simplification si elles sont utilisées seules, laissent des problèmes en suspens.
En effet, la simplification d'un triangle qui est la forme de polygone le plus simple ou encore celle d'un chemin constituée de seulement deux points ne sont pas possibles.
D'autres stratégies complémentaires doivent alors être envisagées : supprimer des géométries ou les fusionner entre elles.
Supprimer des entités
L'objectif est de réduire le nombre d'entités en supprimant celles qui sont trop petites pour être distinguées à l'écran. À noter, il faut indiquer, comme variable d'entrée du processus, le niveau de zoom auquel la tuile s'affiche. Ce paramètre est utilisé pour comparer la taille des géométries (longueur/surface) à leur taille d’affichage (taille des pixels).
Par exemple, cela peut être fait automatiquement avec Tippecanoe via l'option --drop-smallest-as-needed.
Regrouper des entités
Fusionner les géométries avec des attributs en commun permet de diminuer le nombre d'objets et d’accroître les possibilités de simplification. En conséquence, l'ensemble a une taille plus faible.
Tippecanoe intègre ce traitement, avec l'option --coalesce-densest-as-needed.
Les résultats de ces méthodes ne sont pas toujours satisfaisants visuellement. Toutefois, elles aident à produire des tuiles d'une taille acceptable. Conseil : testez-les et utilisez-les !
Cas des points
"Simplifier" une géométrie ponctuelle n'est pas possible. Selon les cas, il est alors possible de supprimer des points ou de les regrouper en clusters.
Supprimer des entités
Nous pouvons ne pas avoir besoin de certaines informations à certains niveaux de zoom. Dans ce cas, le plus simple est d'enlever cette information.
Par exemple : une couche de points contenant les fontaines en France
Sauf pour un cas de dataviz très spécifique, avoir une information sur les fontaines disponibles à une échelle où nous ne pourrons pas distinguer les rues, où elles se trouvent et où les points se verront superposés, n'est pas pertinent.

Toutefois, pour garder une vision globale de tous les enregistrements, du regroupement d'entités est nécessaire.
Clustering
C'est une technique très répandue, qui permet de consolider une partie de l'information sous forme d’agrégats en même temps qu'elle rend possible une meilleure visualisation en évitant les superpositions. L’agrégation des points est alors adaptée en fonction du niveau de zoom.
De nombreux algorithmes de clustering existent prenant en compte différents aspects. L'algorithme à utiliser dépend alors du contexte de l'application. C'est un vaste sujet dans lequel nous n'allons pas rentrer. Mais il est présent dans le domaine de la recherche notamment celui du Machine Learning.
+ INFO : L'article Le clustering pour l'analyse de la biodiversité
Toutefois, les méthodes les plus courantes sont présentées afin qu'il soit possible de le mettre en place de façon assez simple avec PostGIS :
- DBSCAN, avec la fonction ST_ClusterDBSCAN
- K-means, avec la fonction ST_ClusterKMeans
Pour faire encore plus simple, un comptage des éléments présents dans chaque case d’une grille peut être suffisant.
Détermination automatique du niveau de zoom maximal
On peut toujours déterminer manuellement jusqu'à quel niveau de zoom les tuiles doivent être produites. Mais, il est intéressant d'avoir un outil pour estimer la résolution et la densité des données afin de déterminer automatiquement ce zoom maximal pour les représenter à un niveau de détail adéquat. À noter, il est possible d'afficher les données au-delà du niveau de zoom le plus détaillé en faisant de l'overzoom.
Sans rentrer ici dans les détails du processus, les deux étapes principales sont :
1. Analyser les données pour déterminer une distance qui représente la résolution du jeu de données.
2. Associer cette distance à un niveau de zoom, en fonction de la taille de la tuile : à quel niveau de zoom la taille du pixel est équivalente à cette distance ? (En fait, équivalente à deux ou trois fois plus petite que la taille du pixel pour garantir qu'il n'y ait pas de perte de précision et que les tuiles restent utilisables en overzoom).
Perspective et autres choix possibles
Finalement, le traitement des données sources pour l'affichage peut avoir lieu côté serveur ou coté utilisateur (client).
Ici, la procédure mise en place est du côté serveur. Néanmoins, plusieurs traitements sont également possibles de l'autre côté, en utilisant des bibliothèques comme mapbox GL JS, turfjs, ou carto :
- Simplification de géométries en utilisant l'algorithme Visvalingam-Whyatt pour la pré-simplification grâce à la pondération de nœuds : implémenté sous PostGIS via la fonction ST_SetEffectiveArea(). C'est-à-dire, quelle perte de qualité représente la suppression d'un nœud, coté client il ne reste plus qu'à supprimer les nœuds pour atteindre la qualité souhaitée. Comme le montre cet exemple, ou directement en utilisant la bibliothèque geojson-vt de Mapbox.
- Assemblage de points : exemple avec carto
- Calcul de centroïdes, etc.
Ainsi les choix sont nombreux. Pour choisir quelle solution adopter, la prise en compte de la question suivante est souhaitable : Quelles sont les contraintes, est-ce la taille de données, ou plutôt son affichage ?
Conclusion
Les tuiles vectorielles peuvent être générées avec plusieurs outils, de façon plus ou moins automatique. Ces outils peuvent servir pour développer notre propre chaîne de traitement. Finalement, les tuiles vectorielles sont affichées avec une mise en forme qui se fait côté client. Pour établir le choix de la solution à implémenter, la prise en compte des besoins ainsi que les caractéristiques des données à afficher est importante.
En outre, la plupart de ces outils sont assez récents, il est conseillé de suivre leurs évolutions et de ne pas rester avec d'anciennes méthodes qui ne sont peut-être plus adaptées.
Chaque jeu de données peut poser des problèmes spécifiques, et chaque nouvelle situation aide Makina Corpus à réfléchir sur les problématiques rencontrées et à envisager des solutions. Ainsi, parfois il peut s'avérer pertinent de mettre en place un pré-traitement des données.
Contactez-nous : vous rencontrez des problèmes ? Des questions ou des renseignements ?
Formations associées
Formations SIG / Cartographie
Formation Tuiles vectorielles
Nantes - Toulouse - Paris - Bordeaux ou distanciel A la demande
Voir la Formation Tuiles vectoriellesFormations SIG / Cartographie
Formation QGIS
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation QGISFormations Outils et bases de données
Formation PostgreSQL
Nantes Du 8 au 10 septembre 2026
Voir la Formation PostgreSQLActualités en lien
Générer des tuiles vectorielles sur mesure avec Django
Django
31/05/2016
Dans cet article nous allons voir comment générer dynamiquement des tuiles vectorielles utilisables par la bibliothèque de visualisation mapbox-gl-js à partir de données stockées dans un modèle GeoDjango.

Profil d'élévation avec des tuiles vectorielles
SIG
30/05/2016
Comment calculer un profil d'élévation côté client en utilisant des tuiles vectorielles
