Makina Blog
Itérations vers le DDD et la clean architecture avec Symfony (1/2)
Cet article pose un regard de haut niveau sur les choix effectués dans deux projets que nous avons réalisés qui s’orientent progressivement vers l’architecture hexagonale, en détaillant sommairement les raisons de ces choix.
Il sera suivi par un second article détaillant les évolutions effectuées dans une seconde itération de l’évolution de la conception. Des conclusions et des pistes d’amélioration de la solution seront alors détaillées par la suite.
Note importante : cet article n’a pas vocation à détailler l’ Architecture Hexagonale ni le Domain Driven Design, certaines parties pourront être difficiles à appréhender pour les néophytes quand bien même elles ne sont pas indispensables à la compréhension globale.
Un peu de contexte
En l’an de grâce 2018, et ce après un sérieux coup à la tête, nous avons décidé, de façon déraisonnable et pleins d’entrain d’architecturer un projet autour d’un bus de messages en s’approchant de la méthodologie CQS (Command Query Separation).

Pour faire court, le pattern CQS consiste à séparer les lectures des écritures dans une application en deux silos bien distincts. Nous avons dans le cadre de ce projet décidé d’orienter la couche métier, que nous nommerons le Domaine, en utilisant la méthodologie DDD (Domain Driven Design). Le but ici est de rendre le projet plus facile à maintenir dans le temps, et plus résilient aux bonds technologiques qui lui seront imposés lors de sa maintenance sur le long terme.
Pour bien comprendre les enjeux ici, on parle d’un site utilisé par un peu plus de 150 000 utilisateurs ayant été actifs en 3 ans de production, et ayant soumis entre 40 000 et 80 000 demandes par an. Ce chiffre varie selon les années, mais va globalement en grandissant car de nouveaux types de demandes s’ajoutent chaque année. Chaque demande est ensuite instruite manuellement par un gestionnaire et parcourt un workflow métier complexe, puis se termine par un ensemble de tâches automatisées dont certaines donnant lieu à des envois d’ordre de paiement bancaire (le paiement en lui-même étant géré à son tour par un progiciel de gestion comptable externe).
L’application est donc assujettie à un grand volume de lectures et d’écritures concurrentes. Rien d’extraordinaire en apparence car nous n’avons en aucun cas des chiffres dépassant le million. Néanmoins, elle subit régulièrement des pics de fréquentation sur des périodes identifiées, où le volume de demandes ouvertes en une journée peut monter à plusieurs milliers et ce durant un à deux mois constants, le plus généralement sur une plage horaire restreinte à quelques heures à peine. Durant ces périodes de charge exceptionnelles, le site n’a pas le droit de faillir ; qui plus est, il arrive parfois que des types d’offres exceptionnelles soient mises à disposition ponctuellement, ce qui crée d’autant plus de charge en dehors des périodes habituelles, et impose d’avoir une infrastructure dimensionnée pour soutenir les pics tout au long de l’année.

L’application dispose de deux interfaces utilisateur :
Un front-office, une vitrine accessible aux clients de notre client, qui leur permet de consulter les offres disponibles, et de déposer leurs demandes de dossier pour en bénéficier.
Un back-office de gestion métier, qui sert à instruire les demandes, chacune d’entre elles ayant un workflow de gestion complexe, parfois divergent, et soumis à de nombreuses validations.
Revenons à notre conception, en 2018, le site historique utilisait Drupal comme base technique, il était alors une version très primitive du produit que nous devions construire. Le site d’origine gérait un unique type de demande, contre une vingtaine aujourd’hui. Il ne représentait qu’une infime partie du volume supporté par l’application actuelle. Les autres types de demande étant à cette époque encore traités manuellement sur papier par les gestionnaires.
Sachant que le nombre d’utilisateurs ainsi que le volume de demandes annuelles attendus étaient alors inconnus, l’idée était à ce moment là d’essayer de maximiser l’extensibilité horizontale, de concevoir une application scalable :
Conserver la possibilité, à tout moment, de remplacer les lectures sur la base de données par un Read Model si nécessaire, sans avoir à changer le code de l’interface utilisateur ou du modèle métier, le Read Model consiste en une projection des données dans une base de données optimisée pour la lecture.
Note : Ce qui s’est révélé utile par la suite, plusieurs écrans métiers sont plus tard devenus des goulots d’étranglement de l’application, plusieurs Read Models dédiés à ces écrans ont été développés,
Délayer au maximum les écritures dans des queues de traitements asynchrones pour ne pas pénaliser les performances ressenties par les utilisateurs en train d’utiliser la plateforme.
Réduire les traitements en un ensemble de tâches unitaires et atomiques, assurant un état de la base de données cohérent et permettant ainsi de paralléliser ou délayer certains traitements.
Pour terminer, à cause de contraintes imposées à cette époque par l’hébergeur de la solution, ne pas être dépendant de services additionnels hors PHP et PostgreSQL.
Une des pistes envisagées mais vite abandonnée était de partir sur un modèle d’Event sourcing, en s’approchant de la méthodologie CQRS (Command Query Resource Separation). Après divers essais et prototypes jetables réalisés en amont, nous nous sommes éloignés de la méthodologie CQRS complexe à mettre en œuvre correctement. Ce choix technique expérimental a fait persister des reliquats sur le logiciel bien qu’ils n’aient plus de raison d’exister aujourd’hui. Nous aborderons ce sujet plus tard.
Vue d’ensemble
Cette première itération était contrainte par un planning serré pour la mise en production de l’outil demandé par le client, et par conséquent, elle a abouti à un projet allant dans la direction du DDD mais encore incomplet. Le résultat a été cependant satisfaisant car nous avons réussi à obtenir un code stable, performant, facile à prendre en main et maintenir.

Dans une application Symfony classique, utilisant la méthode appelée RAD (Rapid Application Development), il est d’usage de créer des entités et de les brancher sur un ORM (Object-Relational Mapping), le plus souvent Doctrine, pour gérer leur persistance, ainsi que de maximiser l’utilisation des composants qu’apporte le framework Symfony. En bref, se donner corps et âme au framework et le laisser structurer et porter le projet ainsi que le code métier.
Les multiples composants Doctrine ainsi que son ORM forment ensemble un produit très mature, stable et performant, et l’utiliser dans notre architecture aurait été un choix pertinent. Nous avons fait le choix de nous en séparer pour d’autres raisons, qui ne seront pas détaillées dans cet article. De plus, la méthodologie du RAD en Symfony gratifie ses utilisateurs de résultats spectaculaires et d’un développement d’application très rapide, tout en gardant l’application performante.
Il faut bien comprendre que Symfony est un framework très complet, qui apporte beaucoup de fonctionnalités. Plus il évolue dans le temps, plus il apporte de nouvelles fonctionnalités, et plus il devient aisé de construire une application complète sans avoir à rajouter d’outils externes ou sans avoir besoin de créer nos propres librairies, API ou composants. Cependant, le laisser devenir la colonne vertébrale d’un projet est un exercice à double tranchant :
Dans la durée, plus on va utiliser les facilités du framework, plus ses montées en version vont devenir difficiles pour le projet, car en utilisant ses API, on s’expose à leur dépréciation éventuelle dans le futur ; à ce jour, le projet dont on parle a déjà vécu trois mises à jour de versions majeures de Symfony, et nous avons été confrontés à de telles dépréciations à plusieurs reprises.
Si un jour une des API du framework dont on s’est servi pour structurer le projet devient un goulot d’étranglement, se révèle trop limitée voire trop spécifique pour réaliser correctement ce que le métier ou l’environnement technique requiert, il est alors extrêmement fastidieux de faire marche arrière.
Plus généralement, utiliser intégralement le framework c’est le laisser s’étendre et s’immiscer dans le code métier, ainsi tout besoin de faire marche arrière devient presque impossible, car tout remplacement d’un composant du framework nécessiterait de repasser sur l’intégralité du code de l’application (ou d’implémenter une couche de rétro-compatibilité et miser sur la migration incrémentale).
Nous avons donc décidé de ne pas suivre les bonnes pratiques du moment et du plus grand nombre, et avons inversé la dépendance au framework pour le positionner en tant que composant remplaçable de l’infrastructure du projet et non comme élément structurant. Ceci afin de conserver un code métier le plus indépendant, portable et maintenable possible.
La couche Domaine
L’application est donc construite autour d’un noyau de code métier que nous appellerons désormais la couche Domaine qui est découplée de toute brique logicielle extérieure. Elle se compose ainsi :
Les entités métier
Les entités métier, les modèles, équivalent à des entités que vous auriez écrites pour leur utilisation avec un ORM classique, par exemple :
namespace SuperBoutique2000\Domain\Model;
class Panier
{
public function __construct(
private PanierId $id,
private ClientId $clientId,
private Collection $lignes = new ArrayCollection(),
// ...
) {}
}
Les repositories
Les repositories pour lire et écrire ces entités, par exemple :
namespace SuperBoutique2000\Domain\Repository;
use SuperBoutique2000\Domain\Model\ClientId;
use SuperBoutique2000\Domain\Model\Panier;
use SuperBoutique2000\Domain\Model\PanierId;
class PanierRepository extends AbstractRepository
{
public function find(PanierId $id): ?Panier { /* ... */ }
public function getForClient(ClientId $id): ?Panier { /* ... */ }
public function upsert(Panier $panier): Panier { /* ... */ }
public function get(PanierId $id): Panier { /* ... */ }
}
Dans cet exemple, les implémentations n’ont pas d’importance, et les méthodes vides ne sont là que pour montrer la finalité du repository.
Les commandes
Les commandes, qui sont des simples DTO (Data Transport Object) sous la forme de classes PHP portant des propriétés qui représentent l’entrée utilisateur, par exemple :
namespace SuperBoutique2000\Domain\Command;
use SuperBoutique2000\Domain\Model\ClientId;
class CommandeLePanierCommand
{
public function __construct(
public readonly ClientId $clientId,
public readonly bool $videPanier = true,
) {}
}
Les handlers
Les handlers qui sont des fonctions service qui sont écrites sous la forme de méthodes de classes PHP dont le but est d’ingérer et de traiter les commandes, par exemple :
namespace SuperBoutique2000\Domain\Handler;
use SuperBoutique2000\Domain\Command\CommandeLePanierCommand;
use SuperBoutique2000\Domain\Command\CommandeCreeResponse;
use SuperBoutique2000\Domain\Repository\CommandeRepository;
use SuperBoutique2000\Domain\Repository\PanierRepository;
use MakinaCorpus\CoreBus\Attr\CommandHandler;
class CommandeHandler
{
public function __construct(
private readonly CommandeRepository $commandeRepository,
private readonly PanierRepository $panierRepository,
) {}
#[CommandHandler]
public function commandePanier(CommandeLePanierCommand $command): void
{
$commande = Commande::fromPanier(
$this
->panierRepository
->getForClient(
$command->clientId
),
);
return new CommandeCreeResponse(
$this
->commandeRepository
->upsert($commande)
->getId(),
);
}
}
Pour aller plus loin
À noter que lorsque des traitements métier sont plus complexes, ils sont extraits sous la forme de services additionnels, ce qui permet d’isoler cette complexité tout en la rendant plus facilement testable.
L’intégralité des règles métier et de l’espace fonctionnel de l’application est présent dans la couche Domaine, et ne repose sur strictement aucun code provenant de l’extérieur ; à l’exception du composant de connexion à la base de données, car dans ce premier projet, les repositories n’ont pas été découplés de leur implémentation dans la couche Infrastructure.
Dans ce projet, nous avons fait le choix d’utiliser notre propre DBAL (DataBase Access Layer) et non un provenant de la communauté Open Source, pour de nombreuses raisons qui pourraient être détaillées dans un autre article. Utiliser ici un ORM à la place d’un connecteur SQL spécifique aurait également été un choix légitime et valide, qui n’aurait pas eu de conséquences sur les choix de conception de l’application.
Toutes les possibles dépendances externes dont le domaine métier pourrait avoir besoin sont abstraites par des services sous la forme d’interfaces, et leurs implémentations écrites en dehors de cette couche. Les implémentations réelles sont injectées aux composants en ayant besoin via un conteneur d’injection de dépendance. Cependant dans ce projet, il y en a très peu.
Le framework
Le code du domaine métier ne se suffit pas à lui-même, il nous fallait de l’outillage pour ce qui est de l’ordre de l’infrastructure :
La gestion du protocole HTTP, et donc des requêtes et réponses
La gestion de l’authentification et de la sécurité
Un composant pour créer et maintenir des formulaires, une des parties les plus complexes de ce genre d’application
Un composant d’injection de dépendances pour automatiser la configuration et ne pas avoir à s’en soucier
Maitrisant le framework Symfony, nous avons décidé de l’utiliser pour toute la partie infrastructure technique, configuration et interface utilisateur.
Il est important de noter ici que le framework Symfony, dans ce projet, ne constitue pas une base technique sur laquelle repose l’application, mais est lui même un composant discret dans l’infrastructure : l’application a été conçue de telle sorte que le remplacement de Symfony par un autre outillage reste possible.
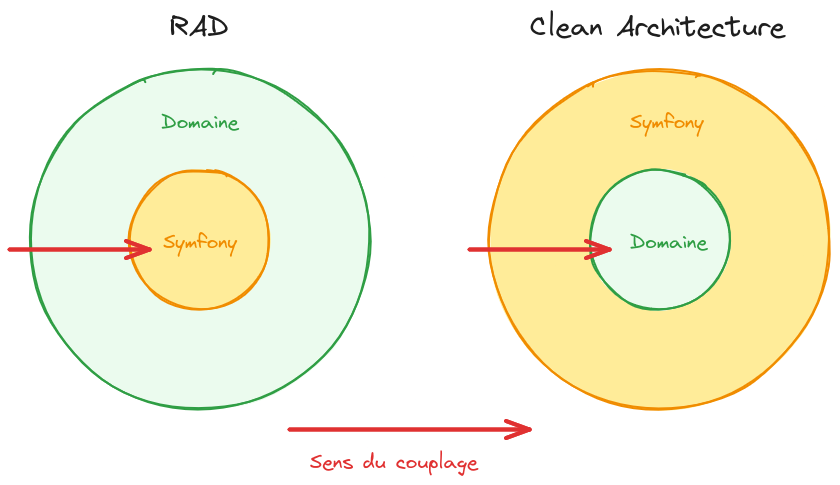
En réalité, bien que nous ayons comme possibilité de remplacer le framework, cette opération ne serait pas triviale : des composants, comme les contrôleurs, utilisent Symfony et par conséquent, pour remplacer le framework, il faudrait aussi réécrire l’interface utilisateur.
Cependant, de la façon dont est construite l’application, on a conservé le Domaine métier complètement découplé du framework, ce qui lui permet d’être réutilisable quel que soit ce dernier, permettant une hypothétique évolution majeure du produit vers un autre outillage sans avoir à toucher au Domaine.
L’interface utilisateur
Toute l’interface utilisateur est construite sous la forme de contrôleurs Symfony et retournent des réponses HTML sous la forme de template Twig, tout ce qu’il y a de plus classique.
Cependant, nous nous éloignons un peu d’une application classique au travers des conventions mises en place déduites du pattern CQS :
Les informations affichées à l’écran, donc restituées au travers des templates Twig, proviennent des repositories et sont utilisées dans ce contexte en lecture seule et sont facilement remplaçables par des Read Model.
Tout envoi de requête de modification de données, donc des requêtes HTTP
PATCH,POSTouPUT(étant une application web traditionnelle, ce ne sera dans notre cas que duPOST) via un contrôleur Symfony donne lieu à la création d’un objet commande et à son envoi dans le bus de messages.
Ce qui se passe ensuite est la consommation du message par la couche Domaine (par les handlers, qui remplacent les contrôleurs) et reste donc fortement découplé de toute dépendance externe.
Le bus de messages
Comme vu précédemment, nous avons fait le choix de concevoir l’application autour d’un bus de messages pour gérer les opérations d’écriture. À l’époque où nous avons démarré la réalisation de ce projet, nous avions plusieurs possibilités :
Utiliser le composant
symfony/messengerque nous fournit le framework Symfony que nous avons évalué et testé extensivement.Utiliser un bus tel que RabbitMQ ou autres prétendants, et utiliser un connecteur existant pour communiquer avec lui.
Développer notre propre solution.

Nous avons abandonné le composant Messenger de Symfony car il était encore loin d’arriver à maturité à ce moment. À ce jour, il est devenu un composant mature et stable, mais ayant choisi historiquement une autre voie en développant notre propre outillage, nous avons conforté le choix de ne pas y migrer. À noter que si c’était à refaire dans le temps présent, nous utiliserions le composant Messenger sans hésiter.
La solution d’utiliser un serveur tiers tel que RabbitMQ a été très sérieusement envisagée. Ainsi, nous avons testé divers prototypes autour de ce dernier, mais à cause de contraintes techniques liées au futur environnement de production, nous avons dû abandonner cette piste.
Nous avons donc développé notre propre solution de bus de messages branchée par défaut sur PostgreSQL. Il fonctionne aujourd’hui dans trois projets distincts, ce bus de messages a été stabilisé et amélioré à travers le temps.
Commandes et événements
Une petite erreur de conception
Une des erreurs de ce projet a été de vouloir trop se rapprocher d’un modèle de stockage en Event Sourcing sans s’y engager complètement. Le but du tout premier prototype était de permettre de rejouer les commandes passées dans le système, pour reproduire un état stable à tout moment.
Cependant, vouloir se rapprocher de ce but sans prendre le virage vers la méthodologie CQRS, a malheureusement enfanté une petite chimère assez improbable :
Nous avons donc des commandes qui sont envoyées dans le bus.
À chacune de ses commandes, nous rattachons un identifiant qui permet de retrouver l’objet métier auquel est destinée cette commande.
Une fois la commande terminée, elle est stockée dans un Event Store.
Si une erreur est survenue, elle est stockée dans l’Event Store de la même manière, mais avec une copie de la trace de l’exception qui s’est produite.
Vous pouvez tout de suite voir là où le bât blesse : nous ne stockons pas des événements, mais les commandes. Notre Event Store placé ici à l’origine pour de grands dessins est devenu à la fin un historique géant de tout ce qui se passe sur la plateforme, mais il n’a aucune utilité métier, il n’existe que pour exister.
Par chance, ce modèle nous a apporté une chose que l’on avait pas au début imaginée : nous avons un journal d’audit complet de ce qu’il se passe sur la plateforme. Ce point nous a permis d’aller plus vite dans la résolution des problèmes, car les facilités de listing et de filtrage que nous apporte cet Event Store se sont alors substituées à un agrégateur de logs.
Pour cette dernière raison, nous avons décidé de le conserver, au prix de devoir développer des tâches planifiées pour le nettoyer régulièrement et ne garder qu’un historique récent de quelques mois.
Et les Domain Event ?
En principe, un Domain Event est un événement interne dans une application, lancé lorsqu’une action se produit dans un certain contexte applicatif, permettant à un autre contexte applicatif de réagir lorsqu’il se produit.
Dans le Domain Driven Design, l’application est découpée en Bounding Context, notion qui relate un espace fonctionnel particulier, et indépendant des autres espaces fonctionnels. Les Domain Events permettent de traverser les frontières (Crossing Boundaries), c’est-à-dire sortir d’un espace fonctionnel pour déclencher des actions dans un autre, sans coupler les espaces fonctionnels autrement qu’avec l’événement lui-même.
Notre application ne dispose pas de Domain Events, dans ce projet en particulier, il y a un et un et un seul métier, et par conséquent un et un seul Bounding Context, ce qui rend nulle l’utilité d’avoir des Domain Events.
Quelques années plus tard, dans le cadre d’une évolution assez conséquente, nous avons utilisé les commandes existantes et permis à des Event Listener de réagir à leur traitement, et ce dans la même transaction métier, afin de créer cette fonctionnalité. Ceci nous a permis d’isoler des parties de code complexes dans leur propre espace fonctionnel.
Conclusion
Ce premier projet nous a permis d’amorcer le virage vers un modèle se rapprochant de la méthodologie Domain Driven Design, et de se faire la main avec un modèle d’écritures asynchrones via un bus de messages. Il n’est cependant pas exempt de défauts.
Voici ce que nous avons obtenu lors de cette première itération :
Des entités métier et leurs repositories, construits sur un connecteur SQL qui a été réalisé dans le cadre de ce projet, maintenu par nos soins.
Un bus de messages intégré à l’application, reposant sur PostgreSQL, dont implémentation initiale a été créée pour ce projet, qui à ce jour n’a plus rien à voir avec son implémentation d’origine et qui est utilisé dans d’autres projets.
Toutes les lectures sont synchrones, et utilisent directement les repositories depuis l’interface utilisateur.
Toutes les écritures sont asynchrones de part leur API, et passent par des commandes envoyées dans le bus depuis l’interface utilisateur. À noter que dans certains contextes, le bus est exécuté de façon synchrone, ce qui n’a pas d’impact sur le découplage de la couche Domaine.
La gestion des transactions SQL est intégrée sous la forme de décorateur du bus de messages, qui agit en cas d’échec de sérialisation de la base en passant les messages en retry dans le bus, ce qui permet de contourner les scénarios de contention liés à des transactions qui se marchent sur les pieds dans la base de données SQL automatiquement. Ça peut paraître primitif, mais après 5 ans de production, ce mécanisme n’a pas failli à sa tâche.
Le code métier est intégralement indépendant de toute dépendance externe, à l’exception de la construction des requêtes SQL dans les repositories.
Toute la validation est faite dans les Command Handler, et donc dans la couche Domaine, ou réside le métier final du client, elle n’utilise pas d’API tierce, elle est orientée métier et écrite en PHP vanilla.
Le framework n’est pas structurant pour le code métier, et est relégué dans une couche infrastructure. Seuls les contrôleurs Symfony sont directement influencés et structurés par ce dernier.
Nous disposons d’un reliquat d’Event Store qui journalise l’intégralité des commandes passant sur la plateforme, ce qui sert à mener des audits sur la santé de la plateforme.
Nous n’avons pas de Domain Events dans ce projet, bien qu’ils aient été introduits plus tard dans une future version, sous la forme d’un contournement de l’Event Store.
Bien que souffrant de quelques défauts de conception, ce projet continue aujourd’hui de vivre en production, est régulièrement maintenu, et va bientôt fêter sa version 5.0. Il a subit trois évolutions fonctionnelles majeures, au cours des cinq dernières années, et continue à fonctionner de façon performante et résiliente dans un environnement matériel modeste, n’ayant pas été remplacé depuis son lancement initial.
Par la suite, et travaillant pour le même client, nous avons continuer de faire évoluer la conception présentée ici. Un second projet qui fait évoluer cette architecture sera présentée dans un prochain article.
Formations associées
Formation Symfony
Formation Symfony Initiation
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Symfony InitiationFormations Outils et bases de données
Formation PostgreSQL
Nantes Du 8 au 10 septembre 2026
Voir la Formation PostgreSQLActualités en lien
Repenser les formulaires Symfony : une approche moderne
Application Web & Mobile
06/02/2026

Itérations vers le DDD et la clean architecture avec Symfony (2/2)
Symfony
20/02/2024

Créer une application Symfony/Vue.js
Logiciel libre
21/06/2022
Pour faire des essais ou bien démarrer un nouveau projet, vous avez besoin de créer rapidement une application Symfony couplée avec un front Vue.js ? Suivez le guide !
