Makina Blog
Itérations vers le DDD et la clean architecture avec Symfony (2/2)
Cet article suit le précédent, et décrit l’évolution de l’architecture technique qui y est exposée. Pour rappel, nous avons évoqué l’existence de deux projets, dont le premier définissait une architecture basée sur le pattern CQS (Command Query Separation) en essayant de s’approcher de la méthodologie DDD (Domain Driven Design).
Nous allons donc maintenant aborder ce qu’il s’est passé ensuite : la génèse d’un nouveau projet, qui, partant des fondations ainsi créées, va faire évoluer le socle technique.
Contexte
Une fois n’est pas coutume, ce projet est lui aussi la refonte d’un projet existant, initialement conçu avec Drupal. Il est très similaire au premier dans le sens où :
Bien que le métier du client soit différent, il s’agit aussi de suivre et d’instruire des demandes clients, de leur création jusqu’à leur finalisation en passant par la planification et la réalisation, la nature des demandes change car il s’agit ici de prestations d’audits et de formations.
Lui aussi se décompose en deux parties, un front-office destiné aux clients de notre client, et un back-office dédié aux gestionnaires métiers, mais il dispose cependant de deux interfaces utilisateur supplémentaires : une dédiée à des prestataires de services, et une autre pour des utilisateurs d’un autre site qui se sert de celui-ci comme d’un fournisseur d’identité au travers d’un SSO (Single Sign On).
Ce projet présente également des workflows complexes, cependant au lieu d’avoir un seul espace fonctionnel, il en dispose de 5, soit 5 workflows tous différents, et ce sans compter un certain nombre de fonctionnalités secondaires venant s’ajouter.
Il est plus riche fonctionnellement : il intègre un composant de création de formulaires en ligne dynamiques, d’une génération de PDF basée sur un DSL (Domain Specific Language), et de multiples autres outils dédiés aux gestionnaires.
Contrairement à son grand frère, ce projet ne s’adresse pas à plusieurs centaines de milliers de clients, mais décompte aujourd’hui quelques milliers d’utilisateurs. Les contraintes sur l’infrastructure sont bien moindres.
Architecture hexagonale
Ports and adapters
L’architecture hexagonale porte un nom qui fausse la perception réelle de ce patron de conception, il devrait être appelé ports and adapters, ce qui désigne son aspect le plus important : l’infrastructure est masquée derrière des interfaces appelées les ports, et les implémentations appelées les adapters sont déportées dans la couche Infrastructure

La notion de couches de l’architecture hexagonale est source de confusion, car elle englobe deux notions distinctes :
Souvent représentées de façon concentriques, les couches Shared Kernel, Domain et Application sont là pour représenter un couplage unidirectionnel de dépendances : l’application dépend du domaine métier, qui lui-même dépend d’un outillage spécifique dédié au projet (le Shared Kernel). On parle ici du patron de conception architecture en oignon (Onion Architecture). Les couches Domain et Application contiennent les ports.
Le plus souvent représentés de façon horizontale, la couche Infrastructure, parfois la couche Persistence ainsi que d’autres composants et systèmes tiers au Domain métier, sont des notions différentes des couches de l’oignon. Ensemble, elles contiennent les adapters. Dans les faits, il s’agit d’une seule et même couche, sur-découpée : la couche Infrastructure pour mettre en valeur les divers composants techniques du système.
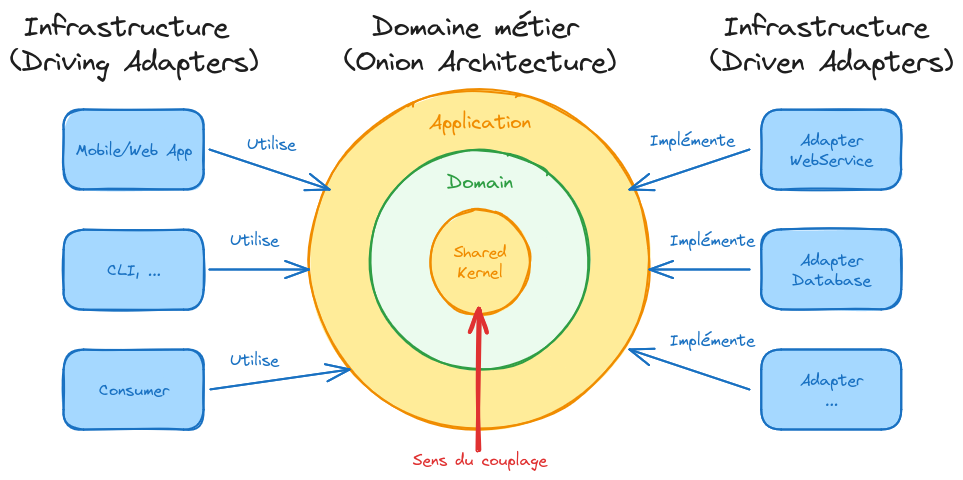
Riches de notre expérience, que ce soit au travers des projets que nous avons conçus et réalisés ou d’audits que nous avons menés, il ressort souvent que les projets s’essayant à l’architecture hexagonale implémentent souvent strictement les différentes couches théoriques définies par ce patron de conception :
Ce sur-découpage entre parfois en conflit avec le reste de la conception d’un projet. Par exemple, la couche Application n’a pas toujours de sens.
En voulant respecter ce découpage à tout prix, la frontière entre Domaine et Application est parfois floue, ce qui peut créer de la confusion mentale.
Qui dit plus de couches, dit plus d’interfaces, et par conséquent un code plus éclaté et plus verbeux.
Le découpage en couche peut parfois amener des algorithmes métiers à être découpés et implémentés à travers de plusieurs couches, ce qui a pour résultat de rendre le code particulièrement incompréhensible, et difficile à maintenir.
Pour rappel l’avantage majeur du patron ports and adapters est de faciliter la maintenance, et non de la complexifier : si les frontières entre les couches applicatives sont floues ou mal définies, ou si l’intérêt de matérialiser une couche est nul ou non évident, il est alors pertinent de ne pas l’implémenter plutôt que perdre la maîtrise du projet.
Dans notre projet
Dès les premières briques posées dans ce projet, nous avons décidé de partir sur l’architecture hexagonale au complet (ce qui, a posteriori, est une erreur). Voici le découplage supplémentaire par rapport à la conception du premier projet :
Nous avons rajouté un Shared Kernel, un espace de nom contenant du code strictement indépendant de toute bibliothèque externe, dont le but est de porter l’outillage transverse à tous les Bounding Contexts du projet.
Le code censé manipuler des API ou du code externe a été ségrégué derrière des interfaces, et leurs implémentations résident désormais dans la couche Infrastructure, en suivant scrupuleusement les notions de Ports et Adapters, à noter que ce choix est parfois discutable et dans certains cas regrettable car cela rend plus difficile la navigation dans le code du projet pour les développeurs.
Une couche Persistence est ajoutée, sortie de la couche Infrastructure, et ce pour structurer le code, elle contient l’implémentation des repositories.
La couche User Interface (pour interface utilisateur) est rajoutée et sortie du Domain pour découpler la dépendance aux contrôleurs de Symfony.
Une couche Application a été ajoutée en plus de la couche Domain, elle contient les interfaces et API exposées directement pour la User Interface, et nous verrons plus tard que ce choix n’était pas pertinent.
Afin de rendre le projet plus cohérent, et redonner ses lettres de noblesse à l’Event Store, nous avons dissocié les Commandes des Domain Events.

Ce projet a débuté après une période d’un peu plus d’un an durant laquelle le run de production et la maintenance applicative du premier projet s’est déroulée. Ceci, nous a permis d’avoir suffisamment de recul pour réfléchir et améliorer un certain nombre de nos choix précédents.
Par exemple, nous avons conservé le bus de messages, et énoncé strictement dans la documentation technique les règles d’usage de ce dernier :
Une commande est toujours traitée de manière atomique, et donne lieu à une unique transaction SQL. En cas d’échec, la transaction
ROLLBACK, et rien ne persiste dans la base de données.Pour respecter la règle « une commande égale une et une seule transaction », aucune commande ne pourra être traitée de façon synchrone pendant le traitement d’une autre (dans le même contexte d’exécution).
Durant une transaction, zéro ou plusieurs commandes peuvent être poussées dans le bus, mais en cas de
ROLLBACKde la transaction, elles seront annulées, et elles ne seront réellement envoyées dans le bus qu’après unCOMMIT.Durant une transaction, zéro ou plusieurs Domain Events peuvent être lancés et seront traités de façon synchrone au sein du domaine métier. En cas de
ROLLBACK, les traitements résultants de ces événements disparaîtront aussi.
Les évolutions
La couche Domaine
La couche domaine de ce projet est très similaire à celle du premier projet à l’exception que nous avons une quinzaine de Bounding Contexts, la structure est bien plus découpée.

De plus, pour la configuration, nous avons opté pour l’utilisation des Attributs apportés par la version 8 de PHP. Ainsi, nous avons introduit des attributs pour :
- Indiquer qu’une classe est une commande.
- Indiquer qu’une classe est un modèle.
- Indiquer qu’une méthode est un command handler.
- Indiquer qu’une méthode est un event listener.
Ceci nous a permis d’utiliser l’auto-configuration du framework pour rendre notre workflow de développement plus efficace. De plus, cela permet de découpler intégralement le code du domaine de l’infrastructure.
Ces attributs servent aussi à des tests unitaires, qui prennent la place d’une phase d’analyse statique, pour procéder à diverses validations :
Des tests automatisés de sérialisation et désérialisation qui lorsqu’ils échouent font échouer la suite de tests unitaires, et forcent les développeurs à aller modifier ou créer les Normalizer et Denormalizer spécifiques dans la couche infrastructure.
Des tests qui valident que toutes les commandes ont bien un et un unique handler.
Des tests qui vérifient la présence ou non d’attributs obligatoires sur les divers composants de la couche Domain afin de s’assurer que la configuration du framework soit bien effectuée.
Les attributs peuvent provenir de dépendances externes car ils n’ont pas d’impact sur l’exécution du code métier, ils servent seulement à des fins de configuration. Nous conservons un domaine métier complètement découplé de tout intrication avec le code de l’infrastructure, tout en rapprochant les éléments de configuration du code, rendant sa lecture, son écriture et sa maintenance plus aisées.
Les Domain Events et l’Event Store
Du fait d’avoir découpé le code métier en un certain nombre de Bounding Contexts, il nous fallait un moyen technique pour permettre la communication entre ces silos : nous avons pour cela utilisé extensivement les Domain Event.
Il a été décidé arbitrairement, par convention, qu’à chaque commande traitée par un handler, au moins un événement devait être lancé, portant l’intégralité des données utiles liées au changement. L’idée d’origine étant, à ce moment là, de ne plus journaliser dans l’Event Store des commandes ayant potentiellement échoué, mais des événements ayant vraiment eu lieu sur la plateforme.
On voit ici qu’on redonne à l’Event Store son usage originel, mais malgré ce détail, il reste toujours aussi désuet qu’il ne l’était dans le premier projet, son utilisation restant toujours et uniquement à des fins d’audit.
Les Domain Events, quant à eux, apportent une vraie fonctionnalité indispensable pour ce projet et ont été largement utilisés.
Plus tard lors de l’évolution du projet, nous sommes revenus en arrière sur la règle qui impose d’avoir un événement pour chaque commande, afin de réduire la verbosité et la lourdeur de l’écriture du code : les événements ne sont désormais plus qu’écrits et lancés que lorsque c’est nécessaire.
La couche Application
Quand on passe du temps à faire de la lecture sur le sujet sur Internet, on se rend compte que le sujet peut être clivant. Il y a deux forces qui s’opposent :
D’un côté, nous avons les gens qui appliquent l’architecture hexagonale de façon très théorique, et qui bricolent des morceaux de glue là où les aspects pratiques rentrent en conflit avec la théorie. C’est de cette façon que nous avons débuté le développement du projet.
De l’autre, ceux qui déclarent que l’architecture hexagonale n’apporte rien d’autre qu’une exagération des abstractions qui parfois s’avèrent inutiles, et qui vont paradoxalement rendre le projet plus complexe à maintenir.
Le projet a évolué vers un juste milieu entre les deux : n’utiliser le découpage de l’architecture hexagonale que là où les bénéfices pour faciliter la maintenance sont évidents.
Note importante : on parle ici d’un projet vivant, qui durant toute sa période de run en production n’a jamais cessé d’évoluer. Que ce soit pour des évolutions mineures ou majeures, une équipe de plusieurs personnes y travaillait à temps plein.
Au début, nous avions donc choisi la première voie. Ne maîtrisant pas tout à fait l’architecture hexagonale à ce moment là, nous avons maladroitement matérialisé la couche Application : nous en avons fait un autre namespace que la couche Domain. Le contenu de ce namespace est un miroir du namespace Domain, disposant d’un sous namespace pour chaque Bounding Context. On y retrouvait, dans notre cas :
Les commandes, envoyées par l’interface utilisateur.
Les événements, qui peuvent être écoutés à l’extérieur, bien qu’à ce jour nous n’ayons pas utilisé cette possibilité.
Les query qu’on envoie à la couche domaine ensuite pour récupérer les entités.
À noter ici qu’au sein même de notre conception, la limite entre Domain et Application est fragile : le code de l’interface utilisateur va manipuler de façon directe les commandes et queries, mais par le biais de ces dernières, elle va aussi se retrouver à manipuler des entités, et donc créer une dépendance explicite à la couche Domain.
Ce n’est pas idéal, et plus tard dans la vie du projet, nous avons fusionné de nouveau les couches Application et Domain : ce découpage tel qu’il existait ne présentant aucun avantage dans le contexte de ce projet.
La nouvelle couche User Interface
Ce projet dispose de plus d’interfaces utilisateurs que le premier qui en a deux. Par conséquent, nous avons décidé de créer une frontière plus franche entre les contrôleurs et la couche Domain (et Application ici) : nous avons donc créé une couche supplémentaire, la couche User Interface.
Selon l’architecture d’un projet, l’interface utilisateur peut être :
Soit intégrée dans le code du backend, ce qui est le cas ici, en utilisant le framework.
Soit sous la forme d’une autre application utilisant des technologies différentes et communiquant avec le domaine au travers du bus de messages, via les commandes ou tout autre moyen tel qu’une REST API par exemple.
Notre projet bien qu’implémentant la première solution, combine des aspects de la seconde : les lectures sont synchrones, et utilisent directement les interfaces des repositories, mais toutes les écritures passent par le bus de messages.
Les Bounding Contexts de cette couche sont les différentes applications et ne suivent pas scrupuleusement le découpage du Domain : on retrouve un namespace par interface utilisateur :
- Un pour le back-office.
- Un autre pour le front-office.
- S’en suit un autre pour l’interface de gestion dédiée aux prestataires tiers.
- Et une dernière pour toute la partie fournisseur d’identité, le SSO.
Nous avons ici d’ores et déjà un découplage de l’interface utilisateur avec la couche Domaine, d’où la création de cette nouvelle couche User Interface pour maîtriser et limiter la fuite d’interfaces du Domain dans cette couche de niveau supérieur.
Conclusion
Ce projet plus riche fonctionnellement que le premier, et disposant d’un panel de types d’utilisateurs plus varié que le premier, s’est très bien prêté à l’exercice de l’implémentation de l’architecture hexagonale. Même si nous avons effectué quelques retours en arrière sur des choix d’implémentation et de découpage, le résultat est un code très lisible, aisé à maintenir, dans lequel les couplages entre composants sont minimes.
Avec quelques années de recul, nous avons statué que l’architecture hexagonale était intéressante, mais ne doit pas être implémentée aveuglément. Bien choisir les aspects de ce patron de conception qui sont en accord avec le projet est essentiel. En d’autres mots, comme tout patron de conception, il ne doit jamais être implémenté de manière scolaire, mais adapté, dérivé selon les besoins.
Le futur
La couche Application
Nous avions découpé notre domaine en deux couches distinctes :
La couche Domain, qui contient les entités et la logique métier,
La couche Application qui contient la surface du domaine qui peut être utilisée par le code des couches supérieures, notamment l’interface utilisateur, donc les commandes, les événements et les interfaces des Read Model.

À l’usage, nous avons observé que cette distinction, bien que semblant être une bonne idée à l’origine, est en réalité relativement inutile. L’architecture en oignon, ou hexagonale, ou la Clean Architecture dictent bien souvent que toute couche supérieure peut atteindre la couche inférieure, mais pas l’inverse (notion de dépendance unidirectionnelle). Dans ce contexte, avoir une couche domaine divisée en deux n’était pas nécessaire, et crée une dissonance cognitive inutile, forçant le développeur à faire sans arrêt des allers et venues à deux endroits différents dans son éditeur de code.
À ce jour, le projet a déjà évolué et nous avons fusionné ces deux couches dans la couche Domain d’origine.
L’Event Store
Avoir un Event Store inutile est… eh bien, inutile. De plus, il stocke aujourd’hui l’intégralité de l’historique de ce qu’il s’est passé sur les différentes applications où nous l’avons mis en place.
Cet historique est stocké sous la forme de commandes ou événements sérialisés, en JSON le plus souvent. Non seulement les lignes de cette table prennent énormément de place, mais en plus cette table tend à grossir énormément. En 5 ans de production, nous avons près de 10 millions de lignes sur le premier projet, sachant que nous avons une purge qui tourne régulièrement pour supprimer ce qui est inutile à conserver à des fins d’audit dans cette table.
Dans le futur, nous devrions remplacer cet Event Store par :
Une solution d’agrégation de logs, pour les traces applicatives.
Une plus grande rigueur dans l’écriture du code métier pour l’instrumenter, journaliser tous les avertissements, erreurs, événements métiers importants.
Lorsqu’un besoin métier est de journaliser des événements qui se passent et de pouvoir le restituer aux utilisateurs, que c’est une fonctionnalité demandée et non un simple besoin d’observabilité, alors il faut dédier des tables d’historiques dans le schéma SQL et des entités métiers pour ces données.
Le bus de commandes

Aujourd’hui, le composant Messenger de Symfony semble avoir atteint une maturité suffisante pour être utilisé en tant que tel. Nous prévoyons de revenir vers lui pour de futurs projets.
Les entités et leur repositories
À terme, il est envisagé de tester un projet ayant cette architecture avec l’ORM Doctrine pour évaluer ses performances et confirmer ou non qu’il soit suffisamment souple et extensible pour nos besoins : là où pour les simples lectures et écritures des données, il fera de toute évidence l’affaire. Nous avons en sus très régulièrement le besoin d’écrire des requêtes SQL complexes, (notamment pour des tableaux de bord, analytiques ou purement métiers) utilisant des fonctionnalités avancées de la base de données PostgreSQL.
Utiliser un ORM, quel qu’il soit, à terme, devrait nous permettre de devenir beaucoup plus efficace, car nous n’aurions plus à écrire les repositories et leur code SQL à la main (bien qu’à ce jour, nous ayons factorisé de manière efficace une majeure partie du code SQL). Ceci au coût de nous rendre dépendant de ce dernier et donc de devoir debugger un outil qu’on maîtrise bien moins en cas de soucis ou scénario un petit peu moins classique.
Cependant, vouloir revenir vers un ORM semble être un choix raisonné, car bien que nous n’ayons pas utilisé Doctrine ORM sur ces trois projets en particulier, nous ne l’avons pas abandonné par ailleurs, et :
Doctrine ORM est de toute évidence un produit mature, très stable, activement maintenu et très bien documenté.
Le manque de souplesse qu’il pourrait avoir dans certains cas d’utilisation à la marge est quelque chose de prévisible et tout à fait normal. C’est un ORM et par conséquent, comme tout outil de cette famille, il souffre de défauts inhérents à son champ fonctionnel originel. Ce n’est pas un marteau doré mais un outil performant pour les cas d’utilisation pour lesquels il a été conçu.
Rien n’empêche d’utiliser un second connecteur à la base de données à côté de Doctrine, en partant de l’hypothèse qu’il peut réutiliser la même connexion SQL, et donc travailler dans la même session SQL en partageant les transactions : de ce fait nous pouvons utiliser le meilleur de chaque outil.
La grande force de Doctrine ORM est la gestion des objets et grappes d’objets au travers de son pattern Unit Of Work, qui est parfois critiqué, mais fonctionne très bien. Même si certains comportements à la marge peuvent être ennuyeux, il reste suffisamment bien documenté pour s’en sortir.
Le Domain Driven Design
L’implémentation actuelle de ce second projet s’est paradoxalement éloignée des principes du Domain Driven Design en comparaison au premier projet : là ou le premier projet intégrait des méthodes métier sur les entités, le second lui délègue tous les traitements métiers aux handlers.

Dans un monde parfait, les handlers devraient s’effacer au profit de l’implémentation des règles de gestion métier et de leur validation, que ce soit le variant ou l’invariant, directement dans les entités elles-même.
Ceci présente de nombreux avantages :
La validation devient naturelle, et n’a plus besoin de composant tiers pour être implémentée : une simple gestion d’erreur via des exceptions peut suffire dans la majorité des cas.
De ce fait, jamais une entité ne pourra vivre en mémoire dans un état incohérent.
Les règles de gestion métier sont implémentées directement dans l’entité qui en jouit, et par conséquent le code n’est plus explosé dans différents composants.
Il n’y a plus besoin de créer un environnement virtuel incluant un bus de message en mémoire et une implémentation de la couche persistance pour écrire les tests fonctionnels : les entités se suffisent à elles-mêmes et l’écriture des tests fonctionnels devient naturelle.
Conclusion
Cet article a été rédigé il y a maintenant plus d’un an, et depuis de nombreux sujets ont été réfléchis par notre équipe.
On notera tout d’abord qu’après une phase d’expérimentation, nous avons décidé de revenir vers Doctrine ORM, car utilisé tel que documenté, il offre un stabilité étonnante, et ce même avec des relations entre objets complexes. Il permet donc aisément d’implémenter le DDD pleinement, c’est à dire en incluant tout le code métier qu’on retrouve actuellement dans nos handlers de commande directement sous la forme de méthodes sur les entités. Ceci pourra être le sujet d’un futur article.
Les projets étant encore en maintenance ont continué d’évoluer, principalement dans le sens de la simplification et de la rationalisation de l’outillage commun, afin de les rendre plus maintenables. Ceci veut dire que notre modèle qui tendait vers l’architecture hexagonale et le Domain Driven Design a subtilement évolué, pour s’éloigner de l’implémentation scolaire des couches de l’architecture hexagonale au profit d’une version simplifiée et adaptée à chaque projet, selon ses contraintes.
Les liens
Liens des projets open source utilisés dans les projets
- CoreBus, notre bus de messages : https://packagist.org/packages/makinacorpus/corebus et https://github.com/makinacorpus/php-corebus
- MessageBroker, l’implémentation PostgreSQL du bus de message : https://packagist.org/packages/makinacorpus/message-broker et https://github.com/makinacorpus/php-message-broker
- GoatQuery, le connecteur de base de données et son query builder : https://packagist.org/packages/makinacorpus/goat-query et https://github.com/pounard/goat-query
- AccessControl, un composant de gestion de droits d’accès utilisant les attributs PHP 8 : https://packagist.org/packages/makinacorpus/access-control et https://github.com/makinacorpus/php-access-control
Nouveaux outils développés depuis
- QueryBuilder, réécriture de GoatQuery dans un PHP plus moderne, disposant d’une batterie de tests unitaires et fonctionnels bien plus complète : https://github.com/makinacorpus/php-query-builder/
- DbToolsBundle, un outil d’anonymisation de bases de données, pouvant se configurer sous la forme d’attributs sur les entités de Doctrine ORM : https://github.com/makinacorpus/DbToolsBundle
Formations associées
Formation Symfony
Formation Symfony Initiation
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation Symfony InitiationFormations Outils et bases de données
Formation PostgreSQL
A distance (foad) Du 10 au 12 décembre 2025
Voir la Formation PostgreSQLActualités en lien
Makina Corpus : conférence sur le DbToolsBundle au BreizhCamp 2025
Symfony
18/06/2025

Itérations vers le DDD et la clean architecture avec Symfony (1/2)
Symfony
13/02/2024

DbToolsBundle : l'outil Symfony pour anonymiser vos bases de données
Symfony
06/02/2024
