Makina Blog
Lier les photographies d'un observatoire ayant des thématiques communes
Cet article présente nos travaux en analyse d'image pour identifier les photographies de paysages correspondant à des thématiques similaires.
Le contexte
Adopté en octobre 2000 par le Conseil de l’Europe, la convention européenne du paysage est un traité qui affirme l’utilité sociale du paysage pour le bien-être individuel comme collectif. La validation de la convention européenne du paysage par le Conseil de l’Europe s’est accompagnée par la mise en place d’observatoires photographiques du paysage, afin de disposer d’un ensemble de données permettant de réfléchir sur l’intégration du paysage dans les politiques d’aménagement du territoire. En France, ces observatoires prennent la forme de fonds photographiques numérisés, organisés en séries, chaque série étant rattachée à un point de vue geo-référencé qui est re-photographié régulièrement.
 Extrait de la Plateforme des Observatoires Photographiques du Paysage de Bretagne, Keraudren photographié en 1995 puis 2017.
Extrait de la Plateforme des Observatoires Photographiques du Paysage de Bretagne, Keraudren photographié en 1995 puis 2017.
L’examen de ces fonds par des experts (géographes, personnes en charge de l’aménagement du territoire, etc.) permet d’analyser l’évolution d’un paysage lors d’un événement spécifique (construction d’un pont, chantier d’une autoroute) ou d’étudier la dynamique de zones particulières (les territoires périurbains par exemple). Leur mise à disposition pour le grand public participe à la valorisation du patrimoine paysager et offre un outil aux citoyens pour s’impliquer davantage dans les actions publiques pouvant influencer leur cadre de vie.
A minima, un observatoire photographique du paysage donne lieu à la mise en place d’un site web, par le biais duquel l’ensemble des citoyens peuvent accéder aux différentes séries de photographies. La mise en place de traitements plus fins, capables d’extraire des informations pertinentes de ce catalogue d’images offrent de nombreux défis dans le domaine de l'analyse d'images
Ce que nous voulions faire
L'observatoire sur lequel nous travaillons actuellement ne se contente pas de proposer des séries de photographies montrant l'évolution d'un paysage au fil du temps : chaque image est rattachée à une ou plusieurs thématiques. Ainsi nos données comprennent plus de 2000 images illustrant quelques 180 thématiques.
Lorsqu'une nouvelle photographie est ajoutée à l'observatoire, la personne qui réalise cette opération doit également renseigner les thématiques auxquelles la photographie se rattache. Sélectionner une poignée de thématiques alors que pratiquement 200 possibilités sont offertes peut rapidement conduire à commettre des erreurs, en oubliant une thématique importante ou en cochant par inadvertance une thématique non pertinente. Nous avons donc cherché un moyen de déterminer des thématiques possibles pour chaque nouvelle image.
Notre faible nombre d'images ne nous permet pas d'entraîner un réseau de neurone pour qu'il identifie la ou les thématiques auxquelles appartiennent une image. Nous avons donc choisi de nous intéresser non pas à une image unique, mais à un couple d'image, en cherchant à déterminer combien de thématiques ces deux images ont en commun.
Nous pouvons ensuite utiliser ce résultat pour que, lors de l'ajout d'une nouvelle image, nous proposions d'abord à l'utilisateur :
- les thématiques du point d'observation auquel l'image est rattachée ;
- les thématiques des images ayant beaucoup de thématiques en commun avec notre image, par rapport au nombre total de thématiques qui les caractérisent.
Nous avons sélectionné sept thématiques :
- dynamique végétale ;
- architecture ;
- erosion littorale ;
- paysages littoraux';
- zone humide ;
- route ;
- densification urbaine.
Chacune de ces thématiques couvre entre la moitié et un quart des images. Nous avons notamment écarté :
- les thématiques anecdotiques, pour lesquelles nous n'aurons pas assez de données pour apprendre leurs caractéristiques ;
- les thématiques omniprésentes, pour lesquelles nous n'aurant pas assez de données pour apprendre à identifier leur absence.
Ces sept thématiques vont nous permettre de réaliser une preuve de concept et de déterminer si l'objectif que nous nous sommes fixé est atteignable.
Quelques mots sur la préparation des données
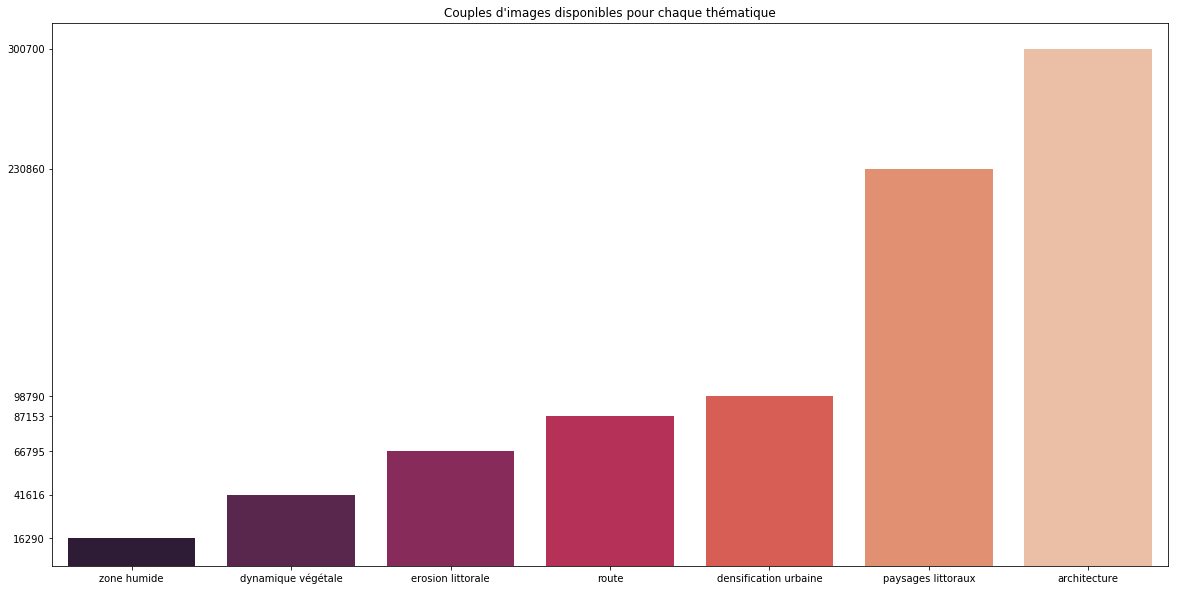 Figure-1
Figure-1
La Figure-1 indique pour chaque thématique combien de couples d'images la concerne. Nous constatons que certaines thématiques restent beaucoup plus présentes que d'autres. En étudiant les résultats de notre méthode, il nous faudra vérifier si ce déséquilibre impacte ou non la qualité du résultat.
![]images/images_communes_thematiques.png) Figure-2
La Figure-2 nous permet de nous assurer que les thématiques sont suffisamment distinctes deux à deux au sein de nos données. En particulier, nous cherchons à éviter le cas où deux thématiques seraient systématiquement présentes ensemble, ce qui fausserait notre étape d'apprentissage en conduisant la méthode entraînée à estimer que ces deux thématiques sont toujours présentes ensembles.
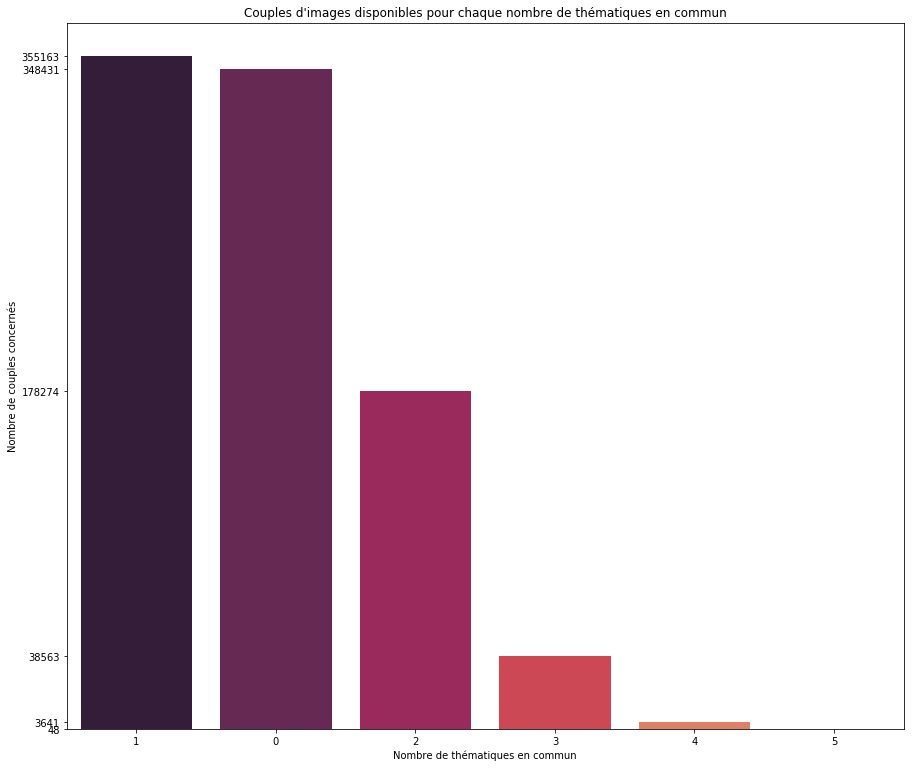 Figure-3
Figure-3
Nos images peuvent avoir entre 0 et 7 thématiques communes. our chaque nombre de thématiques communes, la Figure-3 indique le nombre de couples d'images concernés. Nous constatons un déséquilibre important entre les images ayant peu de thématiques en commun et celles en ayant beaucoup.
Ce déséquilibre, pour un être humain, est une indication : nous savons désormais qu'il est plus probable d'avoir une thématique en commun que cinq thématiques. Mais pour une méthode de Machine Learning ces données déséquilibrées vont être surtout une source de problème. La méthode, un brin paresseuse, risque de se contenter de
prédire que le couple d'images n'a aucune thématique en commun, puisque c'est le cas de figure le plus probable. Nous sommes donc venus prélever aléatoirement un sous ensemble de données pour chaque nombre de thématiques communes, afin d'avoir un jeu de données parfaitement équilibré.
Permettre à un algorithme de comprendre une image et de venir la décrire par un ensemble restreint de valeurs numériques est l'une des plus veilles problématiques en analyse d'image. Comment permettre à un programme d'avoir une vision d'ensemble d'une photographie ? Depuis quelques années les réseaux de neurone excellent dans cette tâche. Nous avons choisi d'utiliser le réseau RESNET50, entraîné sur les photographies de la base de données ImageNet. Normalement ce réseau est conçu pour identifier les objets présents dans une image, parmi une liste de 1000 objets possibles. Nous sommes venus enlever les dernières couches de ce réseau : pour notre application, la prédiction ne nous intéresse pas, nous préférons utiliser directement le descripteur produit par RESNET50 en lui permettant d'identifier le contenu d'une image.
La méthode utilisée
Décrire les dissemblances et ressemblances d'un couple d'images
Comment décrire les différences entre deux images ? Nous utilisons le réseau de neurones RESNET50, entraîné sur la ImageNet. Nous enlevons les dernières couches de ce réseau qui servent à détecter les objets présents dans les images et qui ici ne nous intéressent pas. Avec la bibliothèque Keras seul deux lignes de code sont nécessaires pour récupérer les réseaux entraînés.
from keras.applications.resnet50 import ResNet50
resnet50_model = ResNet50(weights='imagenet', include_top=False)
Ce réseau de neurone déjà entraîné va nous permettre d'obtenir un descripteur de l'image sous la forme d'un vecteur numérique de 2048 élément. Il nous faut charger nos images et leur appliquer un pré-traitement pour qu'elles soient utilisables par RESNET50. Ensuite nous utilisons RESNET50 pour décrire l'image. Malheureusement nous ne récupérons pas directementx un vecteur numérique : RESNET50 nous renvoie un cube de 7x7x2048 éléments. Pour obtenir notre descripteur nous calculons la moyenne sur les deux premières dimensions.
descriptors = load_image_v(imgs_to_load)
descriptors = preprocess_input(descriptors)
descriptors = resnet50_model.predict(descriptors).mean(axis=(1, 2))
Petit subtilité : la fonction load_image_v. Comme vous vous en doutez peut-être cette fonction permet de charger plusieurs images. Le suffixe v vient de vectorize : en effet nous utilisons la fonction du même nom proposé par la bibliothèque Numpy et permettant de transformer une fonction s'exécutant sur une donnée en une fonction capable de traiter en parallèle plusieurs données.
def load_image(img_path):
# load image
img = image.load_img(img_path, target_size=(224, 224))
return image.img_to_array(img)
# vectorize function to run it in parallel
load_image_v = np.vectorize(load_image, signature='()->(n,m,p)')
Notre hypothèse est que des images avec des thématiques communes auront des descripteurs similaires. Nous décrivons donc un couple d'images par le calcul de la valeur absolue de la soustraction de leurs descripteurs respectifs. Comme les descripteurs ont parfois des valeurs très proches, leur différence peut donner des nombres presques null et propices aux erreurs numériques. Afin de nous en prémunir, nous convertissons les nombres réels des descripteurs des deux images en de grands nombres entiers (en les multipliant par 1000). Nous effectuons notre soustraction et notre calcule de valeur absolue. Ce n'est qu'à la fin que nous nous que nous les ramenons à des nombres réels compris dans l'intervalle d'origine.
factor = 1000
descriptor_couple = np.absolute(np.round(descriptors[idx1] * factor) - np.round(descriptors[idx2] * factor)) / factor
Prédiction du nombre de thématiques en commun
Pour prédire le nombre de thématiques à partir du descripteur décrit précédemment, nous utilisons un modèle de régression relativement simple, dont le résumé est le suivant :
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 2048) 4196352
_________________________________________________________________
dropout_1 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_2 (Dense) (None, 1024) 2098176
_________________________________________________________________
dropout_2 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 1025
=================================================================
Total params: 6,295,553
Trainable params: 6,295,553
Non-trainable params: 0
Nous avons entraîné ce modèle en utilisant la méthode d'optimisation adam.
Ce que nous avons réussi faire
Une analyse quantitative rapide
Nous avons choisi d'utiliser un réseau de neurones pour prédire le nombre de thématiques communes. L'un des premiers éléments à analyser pour ce type de méthode est l'évolution de la fonction de coût au fil des époques.
Une époque correspond à une étape d'apprentissage sur l'ensemble des données. À la fin de chaque époque, en plus du score obtenu sur les données d'apprentissages, il convient de calculer le score obtenu sur un jeu de donnée de validation qui permet de s'assurer que le réseau n'a pas sur-appris i.e qu'il n'est pas uniquement bon sur les données d'apprentissages mais qu'il est également capable de généraliser ce qu'il a appri. Dans notre cas le score obtenu par la méthode correspond à la moyenne des erreurs commises en valeur absolue
(MAE, de l'anglais mean absolute error). La Figure-4 montre l'évolution du score MAE en fonction des époques, pour les données d'apprentissage comme de validation.
Notons que le score attendu varie de zéro (aucune thématique en commun) à quatre. Nous n'avions pas assez de données d'apprentissage correspondant à des images ayant cinq, six ou sept thématiques en commun.
 Figure-4
Figure-4
La courbe pour les données d'apprentissage correspond exactement à ce que nous attendons : au fil des époques l'erreur commise diminue. Les résultats obtenus sur les données de validation sont moins stables et divergent fortement à partir de la 12eme époque. Nous avons choisi de conserver les paramètres obtenus à ce moment.
La moyenne de la valeur absolue de la différence entre la prédiction et le résultat attendu est de 0.7 sur les données d'apprentissage et de 0.76 sur les données de validation. Nous avons réalisé une étude plus poussée, en traçant un diagramme boîte à moustache sur l'ensemble l'ensemble des différences en valeur absolue obtenues sur les données de validation (Figure-5). Ce graphique nous indique que les trois quarts des prédictions ont un écart inférieur à 1.1 avec le résultat attendu.
 Figure-6
Figure-6
Pour terminer cette première analyse, nous avons arrondi chaque prédiction à l'entier le plus proche (pour avoir un véritable nombre de thématiques en commun) et affiché la matrice de confusion par rapport à ce qui était attendu (Figure-6). Cette matrice indique notamment que notre réseau rencontre des difficultés lorsque les deux images ont un maximum de thématiques en commun. En revanche, les erreurs commises ne sont pas trop importantes. Par exemple, le réseau ne prédit correctement les quatre thématiques communes que dans 5% des cas, par contre 70% de ces prédictions correspondent à trois thématiques communes ce qui reste relativement proche du résultat attendu.
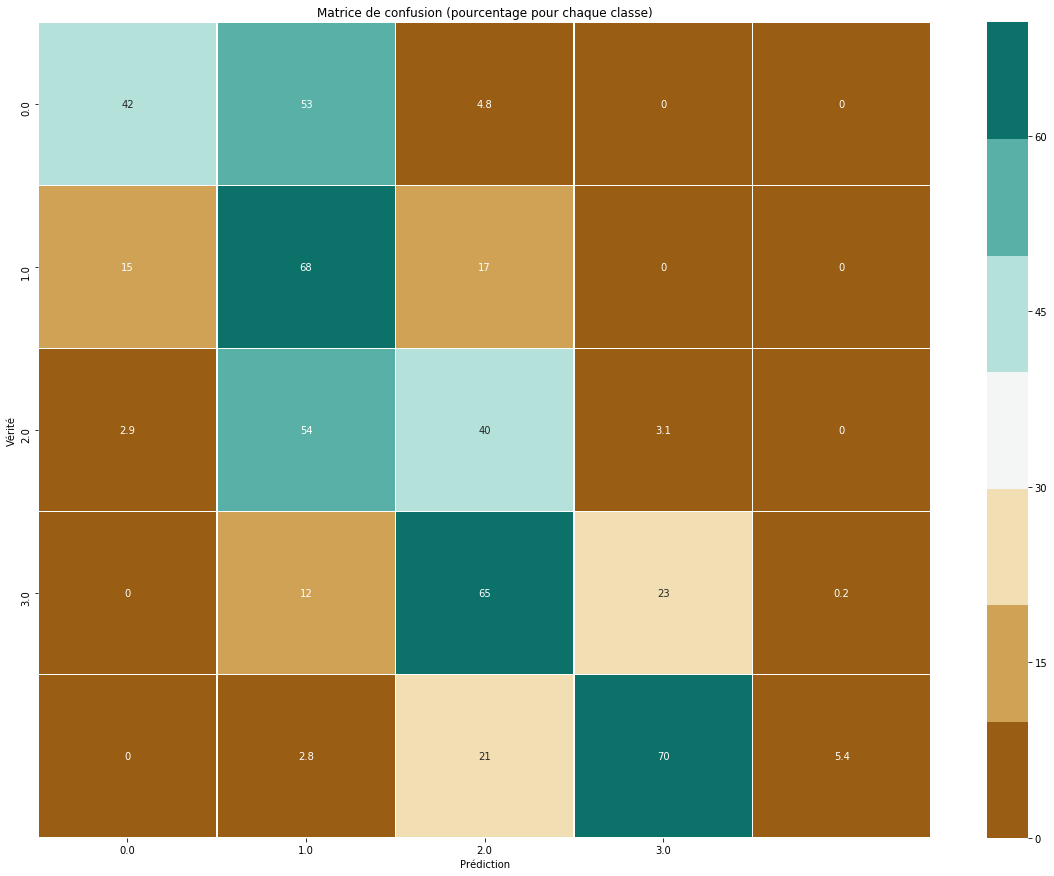 Figure-3
Figure-3
Mise en pratique
Même si les résultats suivant ne sont pas parfait, ils restent encourageants et nous avons cherché à vérifier s'ils nous permettaient d'aboutir un à POC satisfaisant. Nous avons sélectionné 112 points d'observations dont les caractéristiques sont les suivantes :
- les photographies de chaque point d'observation ont entre concernent entre zéro et cinq thématiques parmi nos sept thématiques sélectionnées ;
- chaque thématique concerne au moins une cinquantaine de photos ;
- les couples de photographies entre observatoires sont différents des couples utilisés pour l'entraînement de notre modèle ;
- la majorité des observatoires concernent plus de deux des sept thématiques initiales.
Les observatoires sont affichés sur la Figure-7, avec en rouge les observatoires comprenant moins de deux thématiques, en orange ceux comprenant entre deux ou trois thématiques et en vert ceux comprenant au moins quatre thématiques. 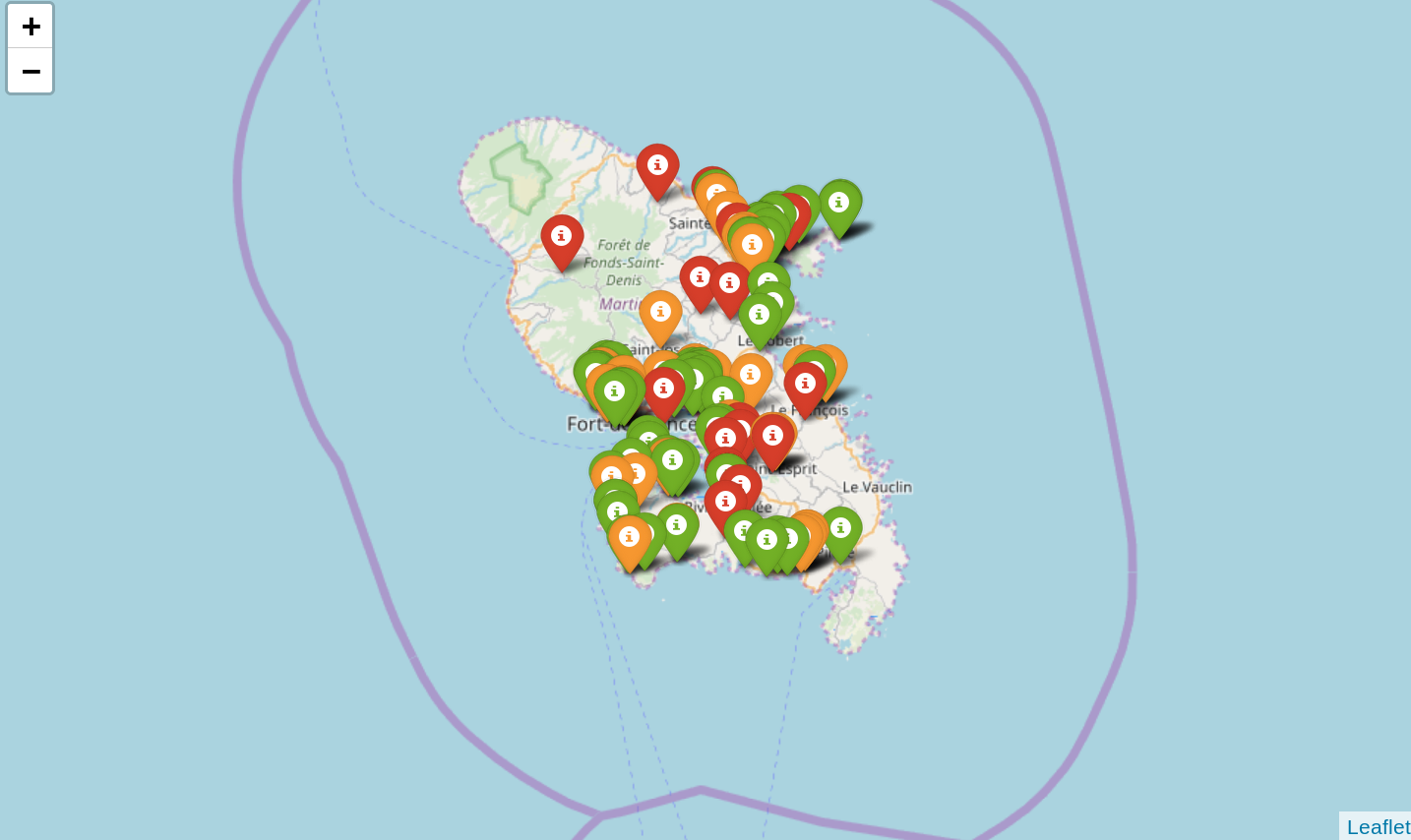 Figure-7
Figure-7
Actuellement toutes les photographies d'un point d'observation ont les même thématiques. Nous avons sélectionné 93 points d'observations comme données de référence et 15 points d'observations jouant le rôle de nouvelles séries de photographies pour lesquelles nous voudrions détecter des thématiques possibles.
Calcul d'intersection
Nous avons d'abord testé une méthode rudimentaire : pour chaque nouveau point d'observation nous récupérons les dix couples d'images qui ont le plus de thématiques en commun et nous conservons les thématiques présentent sur l'ensemble des dix images i.e l'intesection des thématiques présentent dans ces images. Cette démarche permet de sélectionner des thématiques en augmentant leur probabilité d'être correctes. Toutefois, cela implique que nous passions à côté de thématiques pertinentes mais qui ne sont pas communes aux dix images de références.
Nous constatons que dans les suggestions produites l'une des deux thématiques les plus représentées au sein des images (architecture et paysages littoraux) apparaît quasi systèmatiquement. C'est un biais prévisible de notre méthode de sélection : ces deux thématiques sont celles qui ont le plus de chance d'être présentes sur les dix images de référence. En dehors de ces anomalies, les résultats obtenus étaient encourageants, à l'instart de ce que montre la Figure-8.
 Figure-8 : exemple de thématiques suggérées pour un observatoire comprenant trois photographies.
Figure-8 : exemple de thématiques suggérées pour un observatoire comprenant trois photographies.
Scoring
Nous avons ensuite réfléchi à une méthode plus évoluée qui attribue un score à chaque thématique. Plus le score est élevé, plus la thématique à de chance d'être présente dans l'image. Ce calcul de score se base sur les 100 images ayant le plus de thématique en commun avec la nouvelle photographie. Il fait également intervenir une pondération attribuée à chaque thématique de manière à ce que plus une thématique soit présente au sein des images de référence, moins sa pondération soit élevée. Cette nouvelle présente deux avantages :
- elle fait intervenir un ensemble plus large d'image de référence (100 sur les 365 correspondant au 93 points d'observations) et nous pouvons donc estimer que ses recommandations sont plus robustes ;
- elle favorise les thématiques peu représentées et compense donc le biais lié à la présence non uniforme des thématiques au sein de nos images.
Sur nos 15 observatoires de tests :
- les suggestions sont erronées pour seulement trois d'entre eux ;
- les suggestions sont approximatives pour seulement deux d'entre eux ;
- les suggestions sont correctes pour dix d'entre eux.
Conclusion et perspective
Les données avec lesquelles nous avons travaillées sont loin d'être idéales et souffrent de deux défauts majeurs : elles sont peu nombreuses (compte tenu de ce qui est souhaitable pour une méthode de Machine Learning) et présentent un fort déséquilibre au niveau de la représentativité des différentes thématiques.
Cependant les résultats que nous avons obtenus sont loin d'être décourageants. Notre modèle arrive à prédire sans trop d'accros un nombre de thématiques communes proches de la réalité. En imaginant un algorithme de sélection des thématiques probables, plus subtile que celui que nous utilisons et en nous accordant les bénéfices d'un jeu de données d'entraînement anticipé en début de projets de manière à alléger certaines des difficultés actuelles, tout nous porte à croire que nous serons en mesure de proposer des thématiques pertinentes à l'ajout d'une nouvelle photographie.
Au delà, un tel modèle peut servir à détecter des anomalies, par exemple en constatant que les images ayant le plus de thématiques communes avec une photographie ne sont pas celles du point d'observation auquel elle est rattachée. Enfin, nous pourrions imaginer détecter qu'une image correspond à un changement significatif au sein d'une série parce que ses thématiques varient fortement par rapport à ce qui était valable jusqu'à présent pour le point d'observation.
Actuellement nous menons des travaux complémentaires concernant l'analyse du degré de similarité entre deux images sur la seule analyse de leurs caractéristiques visuelles (ce qui est indispensable pour un observatoire ne faisant pas intervenir des thématiques). Nul doute que des perspectives intéressantes surgiront du croisement de ces deux axes de recherche.
Si ces travaux préliminaires vous intéresse et correspondent à des outils que vous souhaiteriez mettre en place, n'hésitez pas : contactez-nous, ou inscrivez vous à l'une de nos sessions de formation en Deep Learning.

Experte data science
Formations associées
Formations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Initiation au Python scientifique
A distance (FOAD) Du 15 au 19 juin 2026
Voir la Formation Initiation au Python scientifiqueFormations SIG / Cartographie
Formation QGIS
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation QGISActualités en lien
Extraction d'objets pour la cartographie par deep-learning : choix du modèle
SIG
02/06/2020
Deuxième article de la série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires.

Extraction d'objets pour la cartographie par deep-learning : création d'une vérité terrain
SIG
18/05/2020
Cette série d'articles parle de cartographie par deep-learning à partir d'images aériennes ou satellitaires. Dans ce 1er article, l'étape préliminaire à toute utilisation d'un modèle d'apprentissage supervisé est abordée: la création du jeu de données d'apprentissage. Notre outil geolabel-maker est mis à votre disposition pour vous aider.

Prédiction du taux de monoxyde de carbone à Madrid - intérêt d'une approche Deep Learning
Data Science
27/11/2018
Dans cet article nous montrons comme utiliser les bibliothèques stars de l'éco-système scientifique en Python pour analyser des données publiques sur la qualité de l'air à Madrid. Nous verrons comment identifier les problèmes liés à ces données. Puis nous comparerons deux approches en Machine Learning : AutoSklearn et les réseaux de neurones de type LSTM.
