Makina Blog
Ces innovations qui permettent à l'IA de sortir des laboratoires - 3/5
Deuxième article Permettre à une IA de s'adapter de la série Ces innovations qui permettent à l'IA de sortir des laboratoires !
Article 2 : Permettre à une IA de s'adapter
L'une des principales limitations des IA actuelles - par rapport à n'importe quel être vivant - réside dans le fait qu'une fois leur apprentissage terminé, il devient difficile de les faire progresser en intégrant de nouvelles données.
L'apprentissage continu cherche à apporter des solutions à ce problème en conférant à une méthode de machine learning la capacité de s'adapter.
 .
.
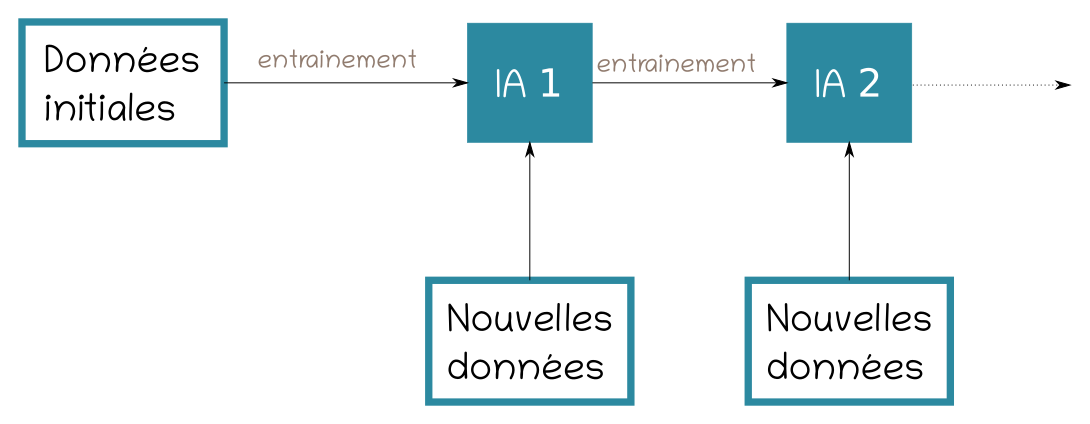
Illustration n°1 : Principe de l'apprentissage continu
Lorsqu'une méthode de machine learning doit être intégrée au sein d'un processus métier, cette faculté à se maintenir à jour en poursuivant son apprentissage est très souvent requise. Par exemple, un système de recommandation devra pouvoir intégrer de nouveaux contenus ou un outil de détection de pièces défectueuses pour être capable de suivre les évolutions de la chaîne de production.
En machine learning l'apprentissage continu se heurte à deux difficultés :
- l'oubli catastrophique de l'anglais Catastrophic Forgetting
- le lien entre l'architecture d'une méthode de machine learning et le nombre de données qu'elle peut assimiler
L'oubli catastrophique
L'oubli catastrophique, comme son nom le laisse deviner, se produit lorsqu'une méthode de machine learning s'adapte à de nouvelles données en oubliant comment traiter les cas précédents.
Ainsi, l'oubli catastrophique peut se produire lorsqu'un réseau de neurones, entraîné à identifier des catégories d'objets, doit être ré-entraîné pour inclure de nouvelles catégories. Entraîner le réseau uniquement avec les données pour les nouvelles catégories a souvent pour effet de nuire significativement à la capacité du réseau de neurones à identifier les catégories précédentes.
L'une des explications les plus probables de l'oubli catastrophique est que la méthode de machine learning se focalise sur la seule résolution des problèmes posés par les nouvelles données alors qu'il lui faut trouver un moyen de résoudre à la fois les problèmes induits par les nouvelles données et ceux liés aux anciennes données.
Spécialisation, transfert learning et oubli catastrophique
Les initiés au domaine du deep learning peuvent rester perplexes devant cette présentation de l'oubli catastrophique. En effet, l'une des méthodologies les plus fréquemment mise en avant, lorsque l'entraînement d'un réseau de neurones ne peut être réalisé qu'avec un faible nombre de données, consiste à commencer avec un réseau de neurones déjà entraîné puis à poursuivre son apprentissage uniquement avec les nouvelles données.
Deux cas sont à distinguer :
- la spécialisation, qui se produit lorsque les nouvelles données sont un cas particulier des premières données
- le transfert learning qui consiste à partir des compétences acquises sur une tâche différente pour résoudre plus facilement une nouvelle tâche
Dans la pratique, cette terminologie - spécialisation et transfert - peut s'employer dans des cas de figure assez proches et ne pas respecter strictement les définitions que nos experts en donnent. Cependant, le principe de base reste le même : un réseau, déjà entraîné, est entraîné à nouveau avec de nouvelles données. Une question vient donc naturellement : ' Pourquoi l'oubli catastrophique ne se produit-il pas dans ce cas ? '
Soulignons d'abord que l'oubli catastrophique peut se produire, alors la tentative de spécialisation ou de transfert learning échouera. Le réseau va commencer par obtenir des scores médiocres, puis stagner ou sur-apprendre. Dans les cas où la spécialisation fonctionne, ce succès peut s'expliquer car le problème à résoudre est au final un sous-problème du problème initial : il n'y a donc pas de nouvelles compétences à acquérir.
Illustration n°2 : Durant la spécialisation le second problème résolu, avec le deuxième jeu de données, est un sous-problème du premier problème résolu avec les premières données
Dans le cas du transfert learning, les pondérations issues des premières données sont uniquement utilisées en tant que point de départ, jugées meilleures que des pondérations aléatoires.
Enfin pour la spécialisation comme pour le transfert learning, la capacité du réseau à résoudre le problème précédent n'est jamais testé : seul compte la résolution du nouveau problème.
Contraindre la mise à jour du réseau de neurones
Durant les trois dernières décennies de nombreuses méthodes ont été proposées pour éviter l'oubli catastrophique, notamment dans le domaine des réseaux de neurones. L'une des méthodologies les plus populaires consiste à concevoir une fonction de modification des pondérations qui évitent les changements brutaux des poids du réseau de neurones tout en permettant d'assimiler les nouvelles informations. C'est donc la fonction d'optimisation du réseau de neurones qui est modifiée pour ne plus uniquement prendre en compte l'erreur commise par le réseau de neurones, mais également des modifications qu'une mise à jour engendrerait sur les pondérations.

Illustration n°3 : Exemple d'un oubli catastrophique
Ces fonctions ne peuvent éviter l'oubli catastrophique que sous certaines conditions. Elles requièrent en outre de nombreux calculs supplémentaires au sein d'un processus d'apprentissage long. Enfin, elles font l'hypothèse que, si l'architecture d'un réseau de neurones permet d'apprendre efficacement à partir de N données, elle permettra également d'assimiler les informations contenues dans les données suivantes.
Dans la pratique ce n'est pas aussi évident : l'architecture d'un réseau de neurones a un impact non négligeable sur la quantité de données différentes qu'il est capable d'assimiler. Si vous disposez d'un petit jeu de données, inutile de concevoir un réseau de neurones à 200 couches. En effet, celui-ci va très rapidement tomber dans un autre travers des méthodes de machine learning le sur-apprentissage. Ainsi, le sur-apprentissage le conduit à se spécialiser sur vos données d'apprentissage, au point qu'il en perd la cFormations IA & Data Scienceapacité à généraliser et donc à produire des solutions adaptées sur de nouvelles données. Inversement, une architecture trop simple ne permet pas de résoudre un problème complexe, représenté par plusieurs millions de données.
Un apprentissage continu efficace requiert donc une certaine plasticité du réseau de neurones.
Architecture dynamique et apprentissage continu
Une autre manière de permettre un apprentissage continu consiste à permettre au réseau de neurones d'évoluer en lui :
- greffant des réseaux de neurones auxiliaires
- ajoutant des couches supplémentaires
- ajoutant des neurones supplémentaires
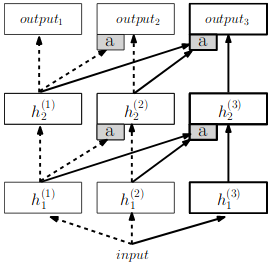
Illustration n°3 : Schéma d'un réseau progressif - ajout d'un réseau de neurones supplémentaires pour traiter une nouvelle tâche - source l'article 'Progressive Neural Network » de Rusu et al'
Les deux premières méthodes ont l'avantage d'être simples à mettre en œuvre. Les frameworks Keras et Tensorflow, utilisés par nos experts IA chez Makina Corpus, permettent aisément de concevoir un méta-réseau à partir de plusieurs réseaux de neurones et à la fois d'autoriser la modification des pondérations seulement pour certaines couches. Nous verrons dans le dernier article de cette série l'une de ces techniques reposant sur le concept de réseau de neurones progressif.
Ajouter des neurones est plus délicat. Cette méthode ne s'envisage pas pour n'importe quelle couche. Elle se prête bien à des couches où chaque neurone est une unité indépendante - comme les couches denses - mais s'avère impossible si un ensemble de neurones produit un outil d'analyse, comme pour les couches de convolution. Enfin, d'un point de vue technique, il est plus aisé de modifier les pondérations de seulement quelques neurones.
Un domaine encore jeune
Alors que de nombreux frameworks permettent de créer, d'entraîner et de spécialiser facilement un réseau de neurones, les méthodes les plus populaires dans le domaine de l'apprentissage continu sont rarement implémentées. Le plus souvent, il s'agit d'initiatives privées à des fins de recherche bien plus que dans une perspective d'industrialisation.
Les verrous scientifiques dans cette problématique demeurent également présents à bien des niveaux. Ainsi, les méthodes ne sont pas encore très performantes au moins sur l'un des aspects suivants : généricité, passage à l'échelle, temps de calcul. Nos experts estiment toutefois que les méthodes existantes, à condition de savoir réaliser un compromis, sont suffisamment avancées pour permettre l'intégration d'une composante machine learning dans de nombreux logiciels.
Conclusion
Chez Makina Corpus en est convaincue : la capacité à s'adapter est essentielle pour permettre un essor plus large des méthodes de machine learning au sein des entrepriseFormations IA & Data Sciences. Dans cet article, les experts espèrent vous avoir donné les clés nécessaires pour appréhender les enjeux de ce domaine de recherche.
Actuellement, la mise en place d'une solution d'apprentissage continu requiert encore un travail important pour trouver et implémenter la solution adaptée à une problématique client. Un dernier facteur pouvant constituer un frein important à ce type d'approche concerne les données. En effet lors du démarrage d'un projet de machine learning, celui-ci n'est pas assuré de disposer de données ordonnées de manière chronologique et suffisantes pour tester et valider un processus d'apprentissage continu. Le prochain article de la série que nos experts vous proposent traite de cette question des données, dans une perspective bien plus large que celle de l'apprentissage continu.
Notre équipe expert en intelligence artificielle se tient à votre disposition si vous souhaitez discuter de la possibilité d'intégrer l'apprentissage continu au sein de vos processus métier.
Sommaire
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningActualités en lien
Ces innovations qui permettent à l'IA de sortir des laboratoires - 4/5
Data Science
07/04/2020
3ème article Alléger les besoins en données de la série 'Ces innovations qui permettent à l'IA de sortir des laboratoires' !
Ces innovations qui permettent à l'IA de sortir des laboratoires - 2/5
Data Science
29/01/2020
Ce premier article présente la démarche mise en place par Makina Corpus lorsqu'une application métier doit intégrer un composant d'intelligence artificielle

Série d'articles : ces innovations qui permettent à l'IA de sortir des laboratoires - 1/5
Data Science
29/01/2020
Introduction qui présente une série de quatre publications sur la problématique de l'intégration d'algorithmes d'intelligence artificielle au sein d'applications métiers
