Makina Blog
Ces innovations qui permettent à l'IA de sortir des laboratoires - 4/5
3ème article Alléger les besoins en données de la série 'Ces innovations qui permettent à l'IA de sortir des laboratoires' !
Article 3 : Alléger les besoins en données
Les deux premiers articles de cette série nous ont permis de vous présenter quelques enjeux majeurs pour l'intégration du machine learning au sein d'applications industrielles. Ce nouvel article traite d'une autre problématique à laquelle nos experts Makina Corpus sont fréquemment confrontés : le volume et la qualité des données nécessaires pour entraîner une IA.
Des méthodes très gourmandes en données
Commençons par un exemple assez courant qui devrait vous parler : réseau de neurones VS enfant. Pour un réseau de neurones devant détecter un objet cible dans une image, un chat par exemple, il sera nécessaire de disposer de plusieurs centaines, voire milliers, de photographies représentant l'objet à identifier en particulier et d'autant de photographies ne contenant par cet objet cible afin qu'il apprenne à l'identifier avec un score de plus de 95% de confiance. Alors qu'un enfant, disons de moins de 4 ans, n'aura besoin que de quelques images avant d'être capable de faire la différence avec un score de confiance élevé.
Google, pour son réseau de neurones FaceNet utilise ainsi près de 260 millions d'images.
D'autres méthodes de machine learning sont heureusement bien moins gourmandes en données, comme par exemple les random forests ou les SVMs. Malheureusement, il existe de nombreux cas de figure où ces méthodes sont moins efficaces que les réseaux de neurones.
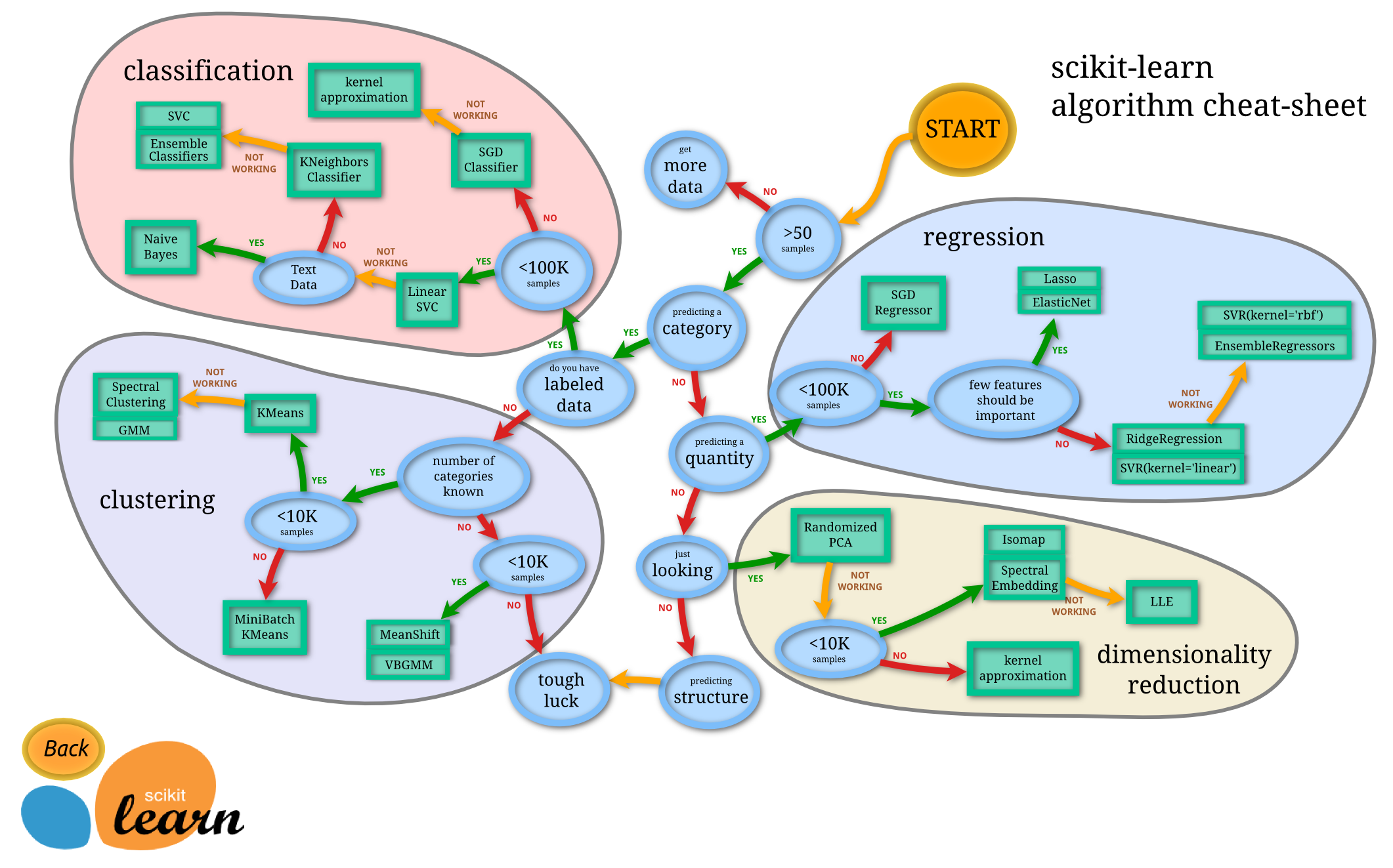
Illustration n°1 : un diagramme fourni par le projet Scikit Learn afin de guider le choix d'une méthode de machine learning. Le nombre de données disponibles tient une place prépondérante pour choisir la bonne méthode. Notons que comme Scikit Learn n'est pas un framework de deep learning, les réseaux de neurones ne sont pas représentés sur ce schéma. Source
Pour ceux qui souhaite une illustration concrète de l'impact du manque de données pour une ou plusieurs catégories prédites par un réseau de neurones, vous pouvez lire ou relire l'article de nos expert sur la détection d'émotions.
La donnée ce n'est pas tout !
La donnée ou sa traduction anglaise « data » est le maître mot dans l'immense majorité des publications traitant de l'impact de l'IA dans l'industrie. D'ailleurs, il s'agit d'un des deux termes composant ce nouveau domaine dont tout le monde parle : la « data science ».
Très souvent ce mot « data » agit comme un écran de fumée qui ne donne qu'un des aspects de la réussite d'une méthode de machine learning. Avoir de la donnée ce n'est pas tout, ce dont les algorithmes d'IA ont réellement besoin c'est d'une vérité terrain. En d'autres termes, pour chaque donnée vous devez disposer du résultat à obtenir pour que l'IA puisse comprendre ce que vous souhaitez faire avec les informations que vous lui donnez.
Ainsi, lorsque les chercheuses et chercheurs de Facebook entraînent un réseau de neurones à déterminer les relations entre les personnes sur une photographie, ils ne disposent pas seulement de milliers d'images contenant des groupes de personnes. En effet, les personnes sur ces photographies sont aussi localisées, identifiées et les relations entre chacune d'entre elles sont connues. Une fois le réseau de neurones opérationnel, il pourra réaliser le même traitement sur d'autres photographies où cette fois les relations entre les différents protagonistes sont inconnues.
Or, souvent une entreprise commence à réfléchir à l'utilisation d'une méthode de machine learning lorsqu'elle a besoin de traiter efficacement un grand nombre de données. Même si l'opération à réaliser n'est pas très longue, le volume de données rend la tâche difficilement réalisable par un être humain. Nous rentrons alors dans un problème d'apprentissage non-supervisé : les données brutes sont transmises à l'algorithme. Ce dernier, en analysant leur structure, essaie de résoudre le problème donné sans aucun exemple de solution. Actuellement, les grandes réussites de l'IA se situent dans le domaine de l'apprentissage supervisé, c'est-à-dire avec une vérité terrain. Les problèmes résolus dans le cadre d'un apprentissage non-supervisé sont eux bien plus rares.
Quels outils pour créer une vérité terrain
Si vous nous avez suivi jusque-là, vous comprenez que fréquemment l'utilisation de l'IA dans une application industrielle se heurte au problème suivant :
- Un apprentissage non-supervisé ne demandera que peu de travail sur les données mais donnera des résultats médiocres ;
- Un apprentissage supervisé nécessite la création d'une vérité terrain mais permettra d'atteindre des performances satisfaisantes.
Une approche pragmatique consiste donc à intégrer comme première étape du projet la création de la vérité terrain. Malheureusement, cette étape est généralement longue et fastidieuse. Elle peut en outre nécessiter des personnes expertes dans un domaine.
Soulignons toutefois que la question de la vérité terrain est au moins aussi vieille que les travaux sur l'apprentissage supervisé. Il y a donc de fortes chances pour qu'un ou plusieurs outils vous permettent de gagner du temps dans sa conception. Citons à titre exemples :
- le framework Snorkel, particulièrement adapté pour le pré-traitement de données textuelles : ces dernières peuvent notamment être associées à une ou plusieurs catégories en fonction de leur contenu ;
- l'outil open-source LabelImg, conçu pour la localisation et l'identification d'objets par boîtes englobantes au sein d'images ;
- Anvil un logiciel gratuit pour l'annotation de vidéos et largement utilisé dans le monde de la recherche ;
Les publications listant et comparant les différents logiciels ou frameworks disponibles ne manquent pas. L'article Top Data Labeling Tools 2019 mis en ligne il y a quelques mois par Trantor constitue un point de départ intéressant, avec une couverture complète des différents types de données et une présentation d'outils récents.
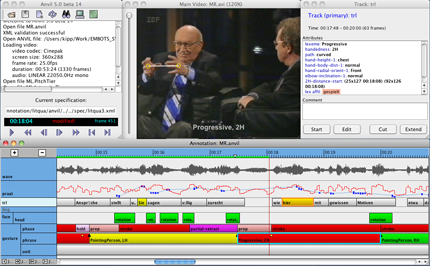
Illustration n°2 : un aperçu du logiciel Anvil, conçu pour annoter les vidéos
Tous ces outils mise sur une interface utilisateur permettant à la personne en charge de créer la vérité terrain et de gagner du temps en lui fournissant des outils adaptés, soulageant les tâches répétitives et permettant une vérification simple des résultats. Afin d'alléger l'effort de conception de la vérité terrain, il est également possible de travailler sur la méthode de machine learning dans le but de réduire son besoin en vérité terrain en ciblant les données capables de favoriser un apprentissage rapide. L'ensemble des travaux menés en ce sens appartient au domaine de l'apprentissage actif.
Qu'est ce que l'apprentissage actif ?
L'objectif de l'apprentissage actif est de permettre à une méthode de machine learning de réaliser un premier apprentissage avec un nombre minimal de données et de s'appuyer sur cet apprentissage pour indiquer : Quelles sont les données qui lui permettront de progresser ? Et quelles sont celles qui doivent être intégrées en priorité à la vérité terrain ?
L'apprentissage actif concerne principalement les cas où une IA doit être entraînée à partir de données faciles à obtenir mais pour lesquelles la création de la vérité terrain est coûteuse. C'est par exemple le cas si nous souhaitons entraîner une IA pour identifier des défauts sur des pièces usinées. Les photographies de ces pièces peuvent être disponibles en grande quantité mais un bon niveau d'expertise s'avère indispensable pour déterminer si des défauts sont présents et où ils se situent.

Illustration n°3 : principe de l'apprentissage actif
Principes généraux
De manière générale, le principe de l'apprentissage actif est le suivant :
- Une IA est entraînée à partir d'une vérité terrain minimale ;
- Cette IA est utilisée pour analyser les données restantes et identifier celles pour lesquelles une vérité terrain lui serait très bénéfique ;
- La vérité terrain est créée ;
- L'apprentissage de l'IA reprend et nous rebouclons sur l'étape 2.
Plusieurs stratégies de sélection de données peuvent être mise en place : la méthode de machine learning peut sélectionner une unique donnée ou un lot de données. Le choix d'une stratégie plutôt qu'une autre dépendra essentiellement du contexte métier au sein duquel l'IA doit être intégrée.
Déterminer le potentiel d'apprentissage d'une donnée
Actuellement, des travaux de recherche se portent sur une méthode permettant de sélectionner les données en proposant plusieurs calculs génériques. La sélection de la ou des prochaines données devant être intégrées à la vérité terrain peut être vu comme un problème d'exploration : il s'agit de parcourir le plus rapidement possible l'information contenue dans un très grand nombre de données.
Tout se passe comme si vous deviez collecter l'ensemble des spécialités culinaires sur le territoire français. L'approche la plus complète serait sans doute de parcourir un à un tous les points de restauration afin de lister les plats proposés. Cependant, parcourir l'ensemble des restaurants serait très long. Pour pouvoir compléter à temps votre liste de recettes, vous seriez sans doute amené à mettre en place une heuristique : par exemple grouper les restaurants par spécialité et visiter uniquement trois restaurants par spécialité.
Plusieurs conséquences liées à l'ajout de la données peuvent être utilisées, par exemple :
- Est-ce que la donnée modifiera significativement le modèle ?
- Est-ce que la donnée peut potentiellement réduire de manière conséquente l'erreur commise par le modèle ?
- Est-ce que la donnée est une grande source d'incertitude pour le modèle ?
- etc.
Après avoir sélectionnées les conséquences qui présentent un intérêt dans le cadre du problème que nous cherchons à résoudre, il faut se pencher sur les métriques permettant d'évaluer l'impact de la donnée au regard de ces critères.
Admettons que vous vous intéressiez aux données sources d'incertitude pour le modèle, pour un problème de classification où l'IA produit la probabilité que la donnée appartient à chacune des catégories possibles. Il est alors possible de choisir les données devant être ajoutées à la vérité terrain, c'est-à-dire celles pour lesquelles la différence entre la première et la seconde probabilité est moindre.
En effet, il paraît cohérent de considérer que si un réseau de neurones indique qu'il voit un défaut grave avec une probabilité de 0.9 et des probabilités de 0.05 pour les catégories « défauts mineurs » ou « sans défaut », cette donnée lui pose moins de difficultés que celle pour laquelle il annoncera une probabilité de 0.55 pour la catégorie "défaut grave" et de 0.4 pour "défaut mineur". En créant la vérité terrain pour la seconde donnée, nous maximisons nos chances que le réseau apprenne quelque chose qui lui permettra de mieux déterminer quand une pièce présente un "défaut grave" et quand elle n'a qu'un "défaut mineur".
Cette manière de procéder sera bien entendu dépendante du fait que la probabilité prédite par le modèle soit fiable. Lorsque c'est possible et si l'apprentissage actif repose sur un calcul réalisé par la méthode de machine learning, il est souhaitable d'entraîner différentes méthodes (variantes par architecture ou les données employées pour les entraîner) et calculer la métrique à partir du résultat de toutes les méthodes.
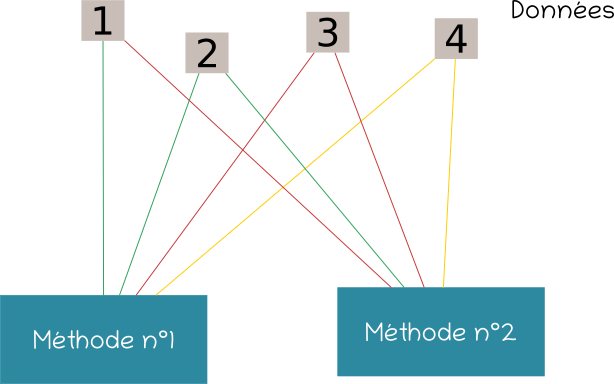
Illustration n°3 : deux méthodes de machine learning différentes sont utilisées pour sélectionner parmi les données 1, 2, 3 et 4 lesquelles doivent être intégrées à la vérité terrain. Les connexions indiquent par leur couleur si la méthode est sûre (vert) ou non (rouge) et de savoir analyser la donnée. Les données 3 puis 4 constituent de bons candidats.
Si ces règles génériques peuvent servir de base, elles ne dispensent pas d'une réflexion propre au domaine métier qui peut fournir des pistes intéressantes afin de déterminer les prochaines données à intégrer à la vérité terrain. Par exemple, les erreurs commises sur des données fréquentes peuvent en faire "des candidats" plus qu'intéressants pour une nouvelle vérité terrain.
Conclusion
Ce 3ème article traite de l'apprentissage actif, un domaine de recherche dont Makina Corpus suis les avancées de prêt. Notre politique est généralement de déconseiller l'utilisation d'une solution machine learning lorsque les données sont insuffisantes. Mais lorsque c'est la réalisation de la vérité terrain qui se révèle coûteuse, l'apprentissage actif permet de ne pas fermer immédiatement la porte à une application intégrant un composant d'intelligence artificielle.
Dans le prochain article nous vous décrirons un exemple concret faisant intervenir une technique simple d'apprentissage actif.
Sommaire
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningActualités en lien
Ces innovations qui permettent à l'IA de sortir des laboratoires - 3/5
Data Science
03/03/2020
Deuxième article Permettre à une IA de s'adapter de la série Ces innovations qui permettent à l'IA de sortir des laboratoires !

Ces innovations qui permettent à l'IA de sortir des laboratoires - 2/5
Data Science
29/01/2020
Ce premier article présente la démarche mise en place par Makina Corpus lorsqu'une application métier doit intégrer un composant d'intelligence artificielle

Série d'articles : ces innovations qui permettent à l'IA de sortir des laboratoires - 1/5
Data Science
29/01/2020
Introduction qui présente une série de quatre publications sur la problématique de l'intégration d'algorithmes d'intelligence artificielle au sein d'applications métiers
