Makina Blog
Ces innovations qui permettent à l'IA de sortir des laboratoires - 2/5
Ce premier article présente la démarche mise en place par Makina Corpus lorsqu'une application métier doit intégrer un composant d'intelligence artificielle
Article 1 : Vers une intégration réaliste des IAs au sein d'applications métier
Les progrès significatifs du machine learning ont permis de pourvoir les outils numériques de nouvelles fonctionnalités. Par exemple, les avancées en synthèse vocale permettent de concevoir des systèmes d'aide performants pour les personnes souffrant de troubles de la vision. La possibilité de détecter efficacement le spam améliore au quotidien la gestion des e-mails.
Du côté des lettres écrites, les centres de distributions de courrier s'appuient également sur l'intelligence artificielle pour faciliter leur travail. L'IA s'invite jusque dans le domaine créatif avec la conception de programmes capables de créer des images fictives d'un réalisme surprenant.

Illustration 1 : Un robot d'aide à la distribution
du courrier, source
Non-déterminisme du Machine Learning
Nombreuses sont les entreprises qui se demandent si certains de leurs processus ne peuvent pas être améliorés ou accélérés grâce aux nouvelles techniques de machine learning.
Ces interrogations conduisent à s'interroger sur les capacités réelles de telles techniques. Certes des progrès spectaculaires ont été réalisés dans la compréhension du discours écrit. Pour autant, est-il raisonnable de sous-traiter à un chatbot une partie des conseils prodigués aux clients ? Si le gain dans les cas de réussite apparaît souvent comme alléchant, il est généralement tempéré rapidement par les conséquences en cas inévitable d'erreurs commises par la machine.
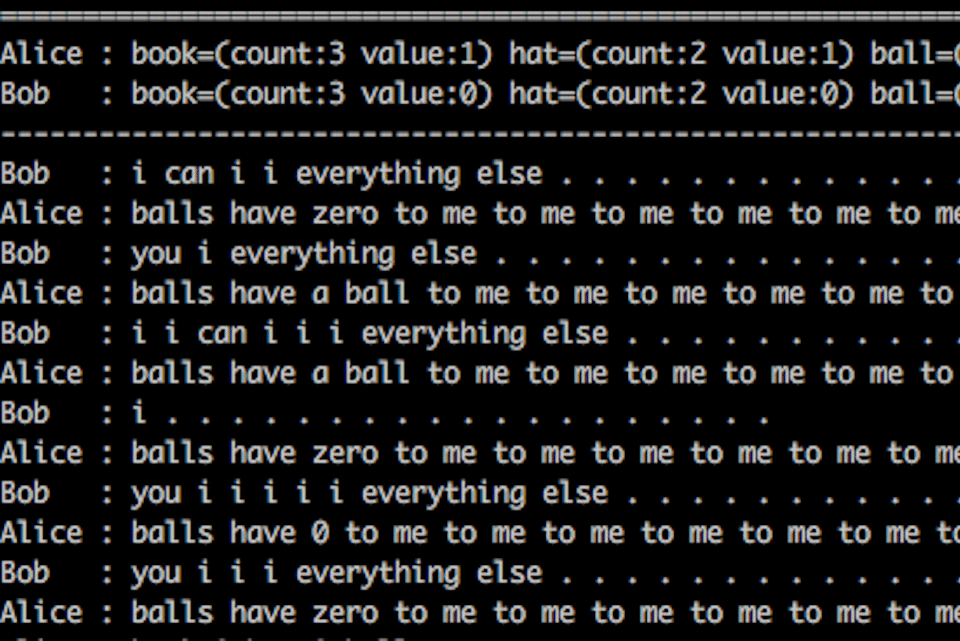
Malgré leurs réussites, les outils de machine learning souffrent d'une difficulté inhérente au concept d'apprentissage automatique. Ainsi, la capacité de généralisation de ces algorithmes, c'est-à-dire leur aptitude à s'appuyer sur un ensemble d'exemples pour apprendre à gérer des variantes inconnues d'une situation. Celle-ci s'accompagne d'une difficulté à prédire pourquoi et comment l'algorithme se trompera. Par ailleurs, les performances obtenues par les méthodes de machine learning ne sont jamais de 100%. Il existe toujours un ou plusieurs cas de figure où le programme échouera.
Illustration 2 : Des messages incohérents par deux chatbots de Facebook, l'un des grands échecs en IA pour l'année 2017 détaillées dans l'article de Synced
l'IA comme outil d'aide à la décision
Si le risque d'erreur des algorithmes de machine learning bloque leur utilisation dans un contexte complètement autonome, il n'interdit pas de repenser le problème pour intégrer la composante de machine learning au sein d'une solution visant à aider la personne en charge du traitement à effectuer.
Dans le domaine médical, s'il est actuellement exclu de déléguer le diagnostic final à une IA, des applications capables de fournir une « 2ème paire d'yeux » à un médecin peuvent être envisager. Ces applications permettront d'améliorer le suivi du patient en portant à l'attention du praticien des informations qu'il n'aurait pu détecter sans l'aide d'un confrère.
Néanmoins, en termes de conception d'application métier, il existe une différence importante entre : créer un composant qui va automatiquement traiter un nombre conséquent de données puis renvoyer le résultat de ce traitement et concevoir un outil qui va interagir avec une experte ou un expert pour lui faciliter les tâches les plus rébarbatives ou lui suggérer des pistes de réflexion qu'il pourrait ne pas envisager
Dans l'article 3 Myths About Machine Learning in Health Care D. A. HaasEric, C. Makhni Joseph, H. SchwabJohn et D. Halamka déclarent : « One of the hospitals that we work at built an application to help physicians identify who is the right specialist to whom they should refer a patient with a particular problem. No one used it. Physicians were too busy to exit the EHR, open the app, enter information into it, and then return to using the EHR. »
Ce qui peut se traduire par :
« L'un des hôpitaux où nous travaillons a construit une application pour aider les practiciens à identifier le bon spécialiste auquel ils doivent adresser le patient pour traiter un problème particulier. Personne ne l'utilise. Les médecins sont trop occupés pour quitter le dossier de santé électronique, ouvrir l'application, saisir les informations et ensuite retourner sur le dossier de santé électronique ».
L'équipe Makina Corpus a à cœur d'éviter ce triste destin aux applications que nous concevons. Le but n'est pas de montrer que l'IA peut tout résoudre, mais au contraire de bien cerner ses limites pour tirer le meilleur parti de ce qu'elle peut offrir.
Processus de conception d'un outil d'aide à la décision
L'illustration ci-dessous présente un exemple de questionnement générique autour de l'intégration d'une IA au sein d'un processus métier.
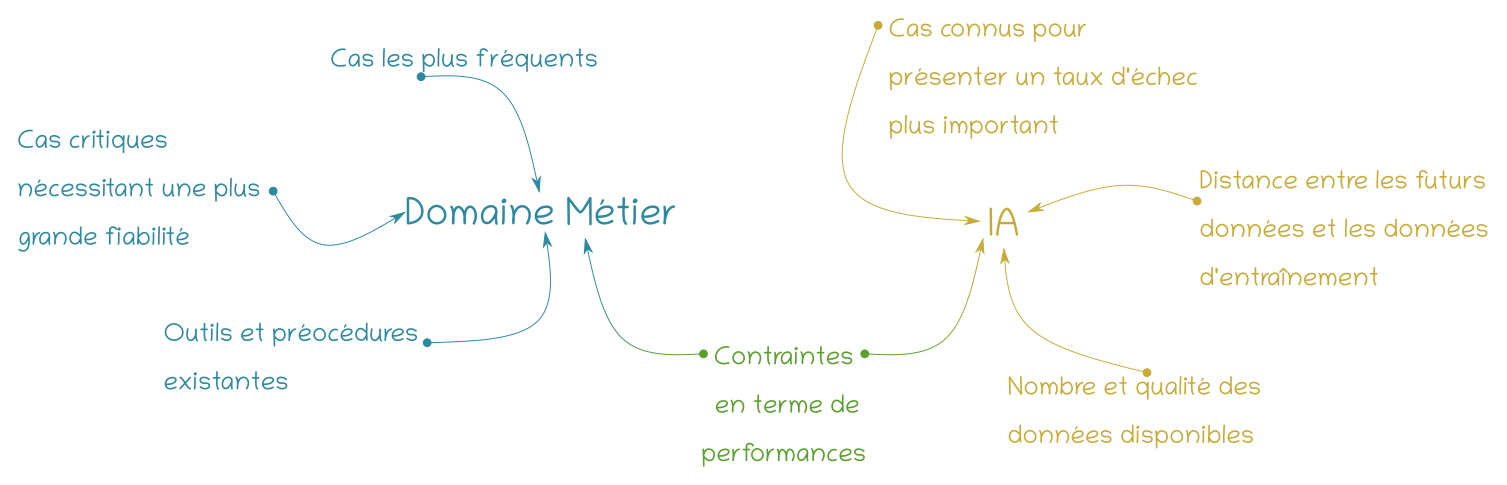
Illustration 3 : Exemple d'analyse afin de déterminer les points critiques lors de l'intégration d'une composante machine learning. Le terme « performance » est entendu au sens large : il peut s'agir d'un taux de réussite minimal requis et/ou d'un temps de calcul
Ce graphique est issu de l'expérience acquise sur nos premiers projets machine learning. Évoquer avec nos clients les différents points qu'il indique, permet dés le début du projet d'anticiper un grand nombre de difficultés et de déterminer précisément quel doit être le rôle assumé par la méthode de machine learning.
Au lancement du projet, il arrive qu'une ou plusieurs question(s) demeurent sans réponse (sur les cas de figure les plus fréquents). Souvent, la meilleure option reste de mettre en pause la réalisation de l'application et de prendre le temps de réaliser une étude afin de lever l'incertitude.
Commencer par les aspects relatifs au domaine métier est plus pertinent, les contraintes liées à ce dernier permettent de réaliser une pré-sélection dans les méthodes de machine learning utilisées par Makina Corpus pour répondre à la problématique du client. Par ailleurs, ces questions forcent une réflexion poussée sur les besoins des utilisateurs finaux. Elles peuvent permettre dans certain cas une reformulation des objectifs de manière à favoriser l'intégration de l'outil au sein des processus de travail. Enfin et surtout, elles nous amènent à anticiper sur toutes les fonctionnalités qui n'ont rien à voir avec l'IA mais qui n'en seront pas moins nécessaires pour garantir une expérience utilisateur optimale.
Comme sécuriser une IA ?
L'analyse des problématiques spécifiques à l'IA conduit à mettre en relation les besoins du domaine métier avec les capacités réelles des méthodes de machin
- Introduction : Série d'articles, article de présentation : ces innovations qui permettent à l'IA de sortir des laboratoires
- Article 1 : Vers une intégration réaliste des IAs au sein d'applications métiers
- Article 2 : Permettre à une IA de s'adapter
e learning envisageables. Leur rôle est de proposer une liste aussi exhaustive que possible des atouts et faiblesses de la méthode de machine learning. C'est cette connaissance de ce que peut - réellement - faire une IA qui conduit notre équipe data science à concevoir un système répondant aux attentes du client. Ils évitent ainsi de créer de faux espoirs rapidement suivis de déception.
L'équipe Makina Corpus parle de « sécurisation d'une IA » pour désigner cette réflexion consistant à identifier dans quelle mesure un algorithme de machine learning pourra apporter son aide à la résolution d'un problème, sans dépasser son seuil de compétence.
Les deux problèmes classiques à résoudre sont :
- les échecs de l'IA sur des problèmes simples
- la répétition des mêmes erreurs
Échecs de l'IA sur des problèmes simples

Si les méthodes de machine learning peuvent résoudre des problèmes extrêmement complexes, leur perception de la difficulté n'est malheureusement pas similaire à celle d'un être humain. Ainsi, il arrive que les méthodes de machine learning se trompent sur des cas de figure simples, générant une frustration importante du côté de l'utilisateur.
Illustration 4 : Un exemple où une IA résout un problème perçu comme difficile en trouvant une
approximation correcte du nombre de visages
présents dans la foule, source

Illustration 5 : Les mêmes IA peuvent facilement être induite en erreur par un simple maquillage, alors que nous pourrions considérer ce visage comme facile à détecter, source
Il est donc impératif de commencer par décortiquer le problème général soumis par le client en plusieurs sous-problèmes afin d'identifier les cas de figure pouvant faire l'objet de traitements déterministes rapides à mettre en œuvre.
Dans nos projets, l'utilisation de la méthode de machine learning est conservée uniquement pour les problématiques ne pouvant être résolues autrement. Aussi, la connaissance des outils existants pouvant déjà résoudre une partie de la problématique posée par le client - grâce à des approches statistiques, en appliquant un arbre de décision, etc.- semble primordiale au sein de nos projets machine learning.
Répétition des erreurs

Les expertes et experts Makina Corpus réfléchissent à un moyen pour l'algorithme - ou le réseau de neurones - pourqu'il apprenne de ses erreurs. En effet, si son rôle est d'assister un utilisateur, il est logique qu'une erreur corrigée par ce dernier ne soit pas répétée. Lorsque c'est possible le résultat est sauvegardé dans une base de connaissances qui est interrogée avant toute sollicitation de l'IA. Si la solution au problème est déjà connue, inutile de le soumettre à nouveau à la méthode de machine learning.
Les méthodes permettant à un algorithme de machine learning de poursuivre son apprentissage à partir des nouvelles données collectées sont aussi très intêréssantes. Aujourd'hui, le champs de recherche très actif est celui de l'apprentissage continu. L'article 2 de cette série traite de cette problématique scientifique.
Conclusion
Ce premier article évoque l'intégration d'une IA au sein d'une application fonctionnelle. Dans de nombreux cas, il est préférable de concevoir un système d'aide à la décision qui facilitera le travail de chacun plutôt que de chercher à automatiser entièrement une tâche. Quelques-unes des spécificités de la conception d'un tel outil ont été abordées en soulignant l'importance de la réflexion autour de l'expérience utilisateur et comment cette dernière vient guider la conception de l'IA.
Sommaire

Experte data science
Formations associées
Formations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations IA / Data Science
Formation Valoriser vos données dormantes avec le Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Valoriser vos données dormantes avec le Machine LearningActualités en lien
Ces innovations qui permettent à l'IA de sortir des laboratoires - 4/5
Data Science
07/04/2020
3ème article Alléger les besoins en données de la série 'Ces innovations qui permettent à l'IA de sortir des laboratoires' !
Ces innovations qui permettent à l'IA de sortir des laboratoires - 3/5
Data Science
03/03/2020
Deuxième article Permettre à une IA de s'adapter de la série Ces innovations qui permettent à l'IA de sortir des laboratoires !

Série d'articles : ces innovations qui permettent à l'IA de sortir des laboratoires - 1/5
Data Science
29/01/2020
Introduction qui présente une série de quatre publications sur la problématique de l'intégration d'algorithmes d'intelligence artificielle au sein d'applications métiers
