Makina Blog
Ces innovations qui permettent à l'IA de sortir des laboratoires - 5/5
4ème article "le cas concret d'un réseau de neurones siamois" de la série "Ces innovations qui permettent à l'IA de sortir des laboratoires" !
Article 4 : le cas concret d'un réseau de neurones siamois
Pour conclure cette série d'articles, nous souhaitions vous présenter un cas concret inspiré de l'un des projets réalisés pour nos clients. Il s'agit d'un réseau de neurones siamois entraîné pour distinguer si un mot correspond à une variante, mal orthographiée, d'un mot correct.
Principe général de ce réseau
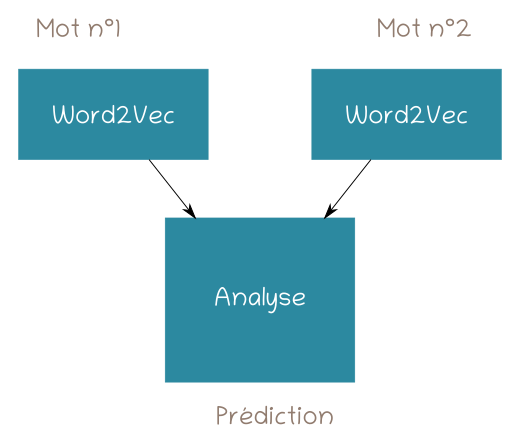
Illustration n°1 : Schéma général du réseau de neurones utilisé : chaque mot est transformé en vecteur numérique, puis les deux vecteurs numériques sont analysés avant de réaliser une prédiction
Quelques exemple : emmbbrassa -> embrassa d'ailleurê -> d ailleurs voudrass -> voudrais
Les mots ont été extraits de la nouvelle « Candide » de Voltaire. Les mots d'au moins six caractères ont été conservés ce qui donne un peu plus de 3000 mots dont nous pouvons apprendre les variantes.
Dans un premier temps, une vérité terrain à partir de 1000 mots de référence a été créée avec environ 500 modifications par mot : lettres supprimées, permutées, insérées. Un réseau avec ces données a été entraîné et ensuite analysé pour comprendre comment lui permettre de progresser.
Erreurs, apprentissage actif et capacités d'apprentissage
Si le réseau obtient un excellent score sur les données d'apprentissage (plus de 98% de réussite), il reste globalement moins bon, (avec un score proche de 97%) sur les données qui permettent de tester sa capacité à généraliser. Ces données sont généralement nommées « données de test » : chez Makina Corpus nous préférons les qualifier de « données de contrôle ».
Ce cas de figure est fréquent et normal. Cependant, nos experts se sont demandés si à partir de ces données posant problème au réseau, il était possible de faire progresser le réseau de neurones sans tomber dans l'oubli catastrophique. Effectivement, les tests ont montré qu'en poursuivant l'entraînement du réseau avec les données de contrôle sur lesquelles il a commis les erreurs les plus importantes, cela ne dégrade pas ses performances sur les données d'apprentissage.
Ce résultat indique que la capacité d'apprentissage du réseau n'est pas saturée et qu'il est capable d'intégrer les spécificités des nouvelles données.
Ajout de nouveaux mots avec leurs variantes
Ensuite, notre modèle a été entraîné avec 1000 nouveaux mots. L'entraînement du réseau a été poursuivi uniquement avec la vérité terrain pour ces mots ajoutés, sans intégrer les données liées aux 1000 mots précédents. Cette fois-ci, le réseau de neurones a commencé à souffrir d'oublis catastrophiques avec des scores qui chutent à 95% pour les données d'apprentissage et de contrôle des 1000 premiers mots, tandis que des scores proches de 98% sont obtenus avec les nouveaux mots.
Nous voulions tester une méthode d'apprentissage continue parmi celles présentées dans l'article Continual Lifelong Learning with Neural Networks: A Review rédigé par les chercheurs G. I. Parisi, R. Kemker, J. L. Part, C. Kanan et S. Wermter. Les conclusions de l'article ainsi que notre expérience, nous ont conduit à nous intéresser à la méthode présentée dans le papier Progressive Neurla Networks décrite par A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu et R. Hadsell.
Le schéma suivant donne le principe des réseaux de neurones progressifs. Les couches 1.1, 1.2 et 1.3 appartiennent à un premier réseau entraîné à résoudre un premier problème à partir d'une ou plusieurs données en entrée. Lorsqu'un autre problème se présente - qui peut être lié à de nouvelles données d'apprentissage ou au besoin d'extraire une information différente des données précédentes - un deuxième réseau est greffé sur le premier. Ici, il correspond aux couches 2.1, 2.2 et 2.3. Chaque couche de ce réseau reçoit en entrée la sortie de la couche précédente et les sorties des couches précédentes des réseaux de neurones antérieurs.
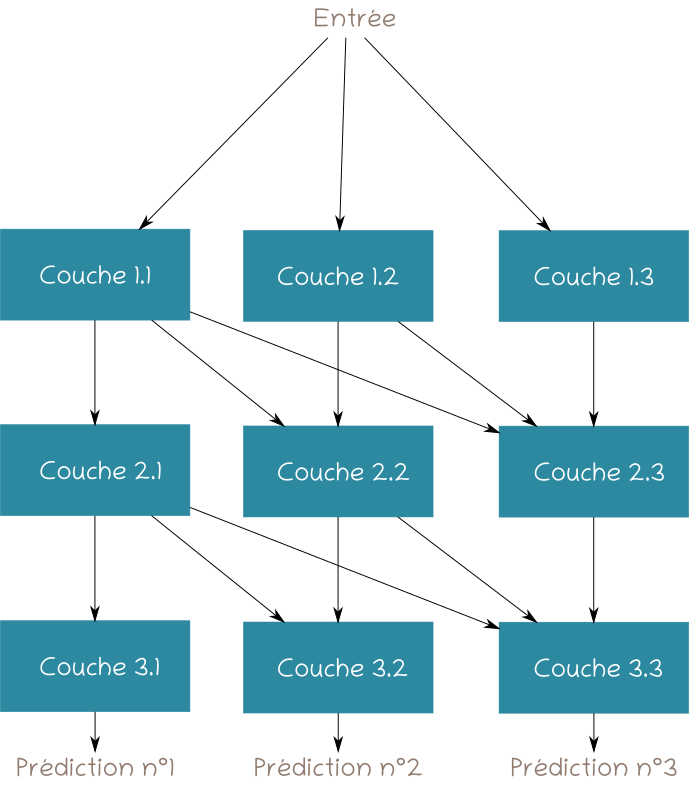
Illustration n°2 : principe des réseaux de neurones progressifs.
Les réseaux progressifs permettent de résoudre complètement le problème de l'oubli catastrophique et assure que l'architecture du réseau de neurones reste adaptée à la complexité des problèmes à résoudre. Il s'agit d'une des techniques d'apprentissage continue les plus efficaces. Elle a cependant le défaut de faire grossir rapidement la structure du réseau de neurones final.
Notre équipe n'a pas réalisé une implémentation stricte du papier de Rusu et al. : la partie analyse uniquement a été dupliquée afin de réduire les problèmes de passage à l'échelle.
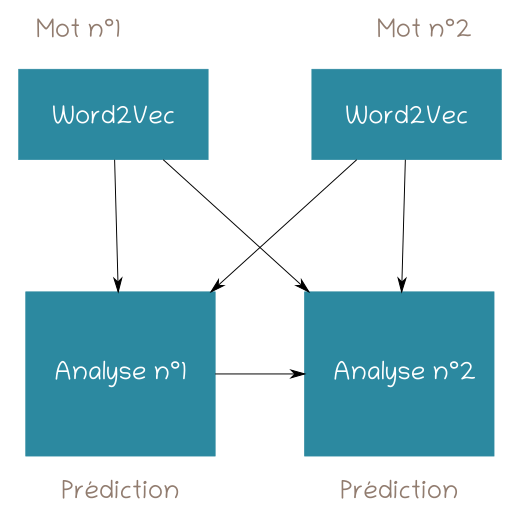
Illustration n°3 : réseau de neurones de mise en correspondance adapté pour devenir progressif.
Cette nouvelle architecture donne de très bons résultats, permettant un score de plus de 98% de réussite sur chacun des groupes de 1000 mots.
Perspectives
Le réseau de neurones progressif obtient de bons scores lorsqu'il s'agit de mettre en un mot en correspondance à un ou plusieurs mots de référence. Pourtant, Il reste beaucoup à faire avant de l'intégrer dans une véritable application. L'un des points dont Makina Corpus aura peut-être l'occasion de vous parler prochainement concerne l'analyse des prédictions fournies par le réseau de neurones progressifs. Chaque sous réseau qui s'ajoute au premier réseau de neurones fournit une nouvelle prédiction. Il convient de sélectionner celle qui correspond bien au résultat que nous cherchons à prédire. En effet, l'un des désavantages des modèles de mise en correspondance est de produire de nombreux faux positifs lorsqu'ils se retrouvent face à une chaîne de caractère qui ne correspond à aucune des données de référence connue. Afin de résoudre ce problème, nous pensons qu'une approche statistique, basée sur l'analyse et la caractérisation des probabilités obtenues pour un mot comparé à l'ensemble des données de référence, permettrait d'obtenir des résultats fiables.
Une fois cette brique entièrement fonctionnelle, nous pourront réfléchir à comment l'intégrer dans une ou plusieurs applications pouvant avoir des objectifs variés. Ce sont ces objectifs ainsi que la volonté d'offrir un confort maximal aux utilisateurs qui guideront nos choix en matière de design. Les choix qui seront réalisés en matière d'interaction homme/machine ou de développement logiciels seront tout aussi cruciaux pour garantir la viabilité de ces applications.
Conclusion
Entre la validation scientifique d'une IA dans un contexte de recherche et son utilisation concrète au sein d'un processus métier, la route reste longue. Nous avons souhaité vous présenter dans cette série d'articles les concepts de base qui guide le travail de Makina Corpus sur cette problématique.
Si vous souhaitez échanger avec nous sur le sujet nous vous recommandons l'une de nos formation en Deep Learning pour les férus de techniques ou sur la Valorisation des données dormantes pour ceux qui souhaitent une approche de plus haut niveau.
Sommaire
Formations associées
Formations IA / Data Science
Formation Initiation au Python scientifique
A distance (FOAD) Du 16 au 20 mars 2026
Voir la Formation Initiation au Python scientifiqueFormations IA / Data Science
Formation Machine Learning
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Machine LearningFormations IA / Data Science
Formation Python scientifique
Aucune session de formation n'est prévue pour le moment.
Pour plus d'informations, n'hésitez pas à nous contacter.
Voir la Formation Python scientifiqueActualités en lien
Ces innovations qui permettent à l'IA de sortir des laboratoires - 3/5
Data Science
03/03/2020
Deuxième article Permettre à une IA de s'adapter de la série Ces innovations qui permettent à l'IA de sortir des laboratoires !

Ces innovations qui permettent à l'IA de sortir des laboratoires - 2/5
Data Science
29/01/2020
Ce premier article présente la démarche mise en place par Makina Corpus lorsqu'une application métier doit intégrer un composant d'intelligence artificielle

Série d'articles : ces innovations qui permettent à l'IA de sortir des laboratoires - 1/5
Data Science
29/01/2020
Introduction qui présente une série de quatre publications sur la problématique de l'intégration d'algorithmes d'intelligence artificielle au sein d'applications métiers
