Makina Blog
Recherche et développement d’indicateurs pour l’aménagement d’un territoire
Nous explorons l’intérêt de calculer automatiquement des indicateurs d’aménagement du territoire en croisant des données OpenStreetMap et des analyses d’images satellitaires.
J'ai participé durant mon stage à des travaux sur la création et la représentation d’indicateurs d’aménagement du territoire à partir de données open source. L’objectif de ces travaux a été de comparer les résultats obtenus à partir de l’analyse des données OpenStreetMap avec ceux obtenus à partir d’images satellitaires ou aériennes.
Les données d’OpenStreetMap (OSM)
La première étape a été de récupérer les données d'OSM, accessibles via l’API Overpass. Cette API permet d’obtenir une sélection des données extraites de la base de données OSM grâce à des requêtes. Pour cela, il suffit de spécifier la zone d’intérêt, le type d’objets recherchés et le format de réception des données. La zone d’intérêt peut être choisie par son nom (par exemple le nom d’une commune) ou par son emprise géographique. Le type d’objets recherchés est transmis sous la forme d’une liste de tags OSM. Le wiki d'OSM et le site tag-info en fournissent la liste et leur descriptif.
Exemple de requête :
``` [out:json]; (way(poly:"48 -1.6 49 -1.6 49 -1.5 48 -1.5")\[building];); out geom ```
Dans cet exemple, les données sont réceptionnées au format GEOJSON. Il s’agit des bâtiments (tags OSM : building) situés dans la zone géographique spécifiée.
Quelques limitations à prendre en compte :
- le nombre de requêtes est limité à 10 000 requêtes par jour,
- le volume de données téléchargé est limité à 5 Go par jour,
- les requêtes supérieures à 1Go sont rejetées.
L’état de l’API Overpass peut être suivi sur http://www.overpass-api.de/api/status (notamment pour vérifier que le service Overpass est disponible ou connaître le temps de récupération).
Pour avoir plus d’informations sur l’API Overpass :
Les données d’imagerie (satellitaire ou aérienne) et le projet Robosat
Les images satellitaires utilisées proviennent des tuiles Mapbox. Pour analyser ces images, la cherche d'un algorithme capable d’identifier leurs contenus a été nécessaire.
La plupart des modèles d'apprentissage profond (deep learning) sont basés sur l’utilisation de réseaux de neurones artificiels. Ces modèles s’inspirent du réseau neuronal humain où les unités de calcul de base sont appelées neurones et traitent les données d’entrée avec un poids associé pour donner une prédiction.
Dans les applications de segmentation sémantique, le réseau de neurones a autant d’entrées qu’il y a de pixels dans l'image. Tout d’abord, l’image passe à travers plusieurs filtres de convolution, ce qui fournit une abstraction des éléments contenus. Ensuite, l’algorithme attribue à chaque pixel la probabilité qu'il appartienne à l’objet recherché. La sortie du réseau est une prédiction sur la nature de l'objet le plus probable dont le pixel fait partie. Le schéma ci-dessous montre le fonctionnement général d’un réseau de neurones utilisé pour de la segmentation sémantique, où l’image d'entrée passe par plusieurs couches de convolution et la reconstruction de l'image est faite en fonction de la prédiction.
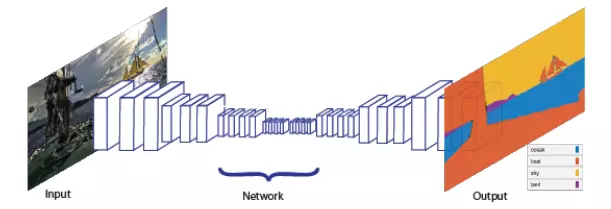
Figure 1 - Schéma d'un réseau neuronal réalisant la segmentation sémantique d'une image
L’algorithme choisi (pour des critères de simplicité et de rapidité de mise en place) est celui du projet Robosat. Ce dernier est un projet de l’équipe de recherche et développement de Mapbox décrit comme « un pipeline pour l'extraction de caractéristiques à partir d'images aériennes et satellitaires ». C’est un projet open-source développé en Python. Il donne accès à un ensemble d’outils permettant in fine l’identification d’objets (bâtiments, parkings, espaces verts, etc) dans des images satellites ou aériennes. Ces outils couvrent toutes les étapes du processus d’apprentissage automatique :
- la préparation des données : création d'un jeu de données pour la formation de modèles d'extraction d'entités ;
- la formation et la modélisation : modèles de segmentation pour l'extraction de caractéristiques dans des images ;
- le post-traitement : les résultats produits par le modèle sont nettoyés et peuvent être transformés en géométries simples.

Figure 2 - Prédiction des bâtiments obtenue par un modèle Robosat (source)
Ce projet a été utilisé pour détecter les bâtiments et les espaces verts contenus dans les images Mapbox.
Résultats obtenus à partir des données d’OpenStreetMap (OSM)
A partir des données OSM reçues via l'API Overpass, je calcule différents indicateurs en utilisant la bibliothèque Python Geopandas. Les indicateurs sont calculés à l'échelle de l'IRIS. L'IRIS est un découpage du territoire utilisé par l'INSEE (voir sa définition, ou leurs contours).
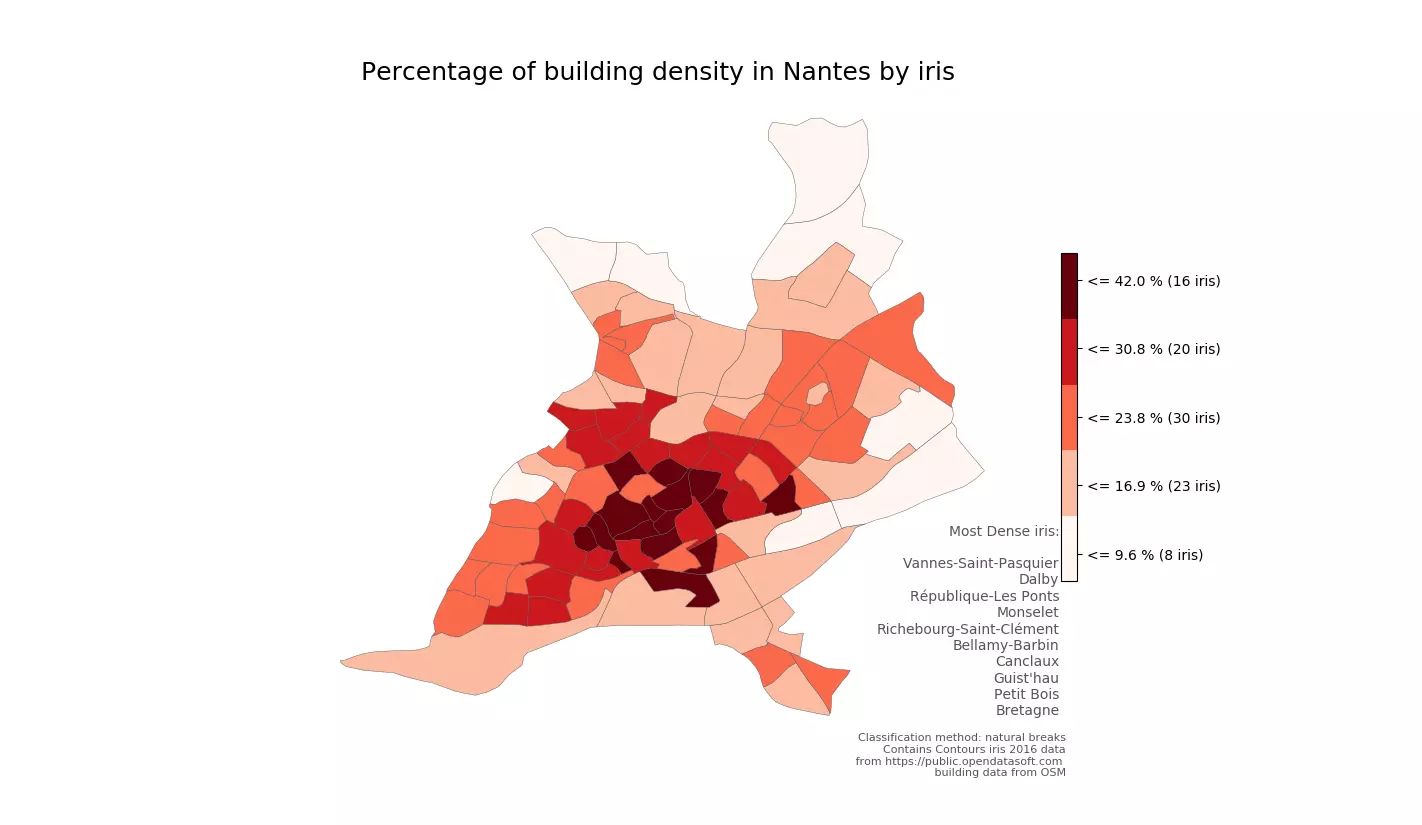
Figure 3 - Densité de bâtiments à Nantes calculée à partir des données OSM
Cette figure montre une forte densité de bâtiments au centre-ville, atteignant jusqu’à 42% de la surface disponible.
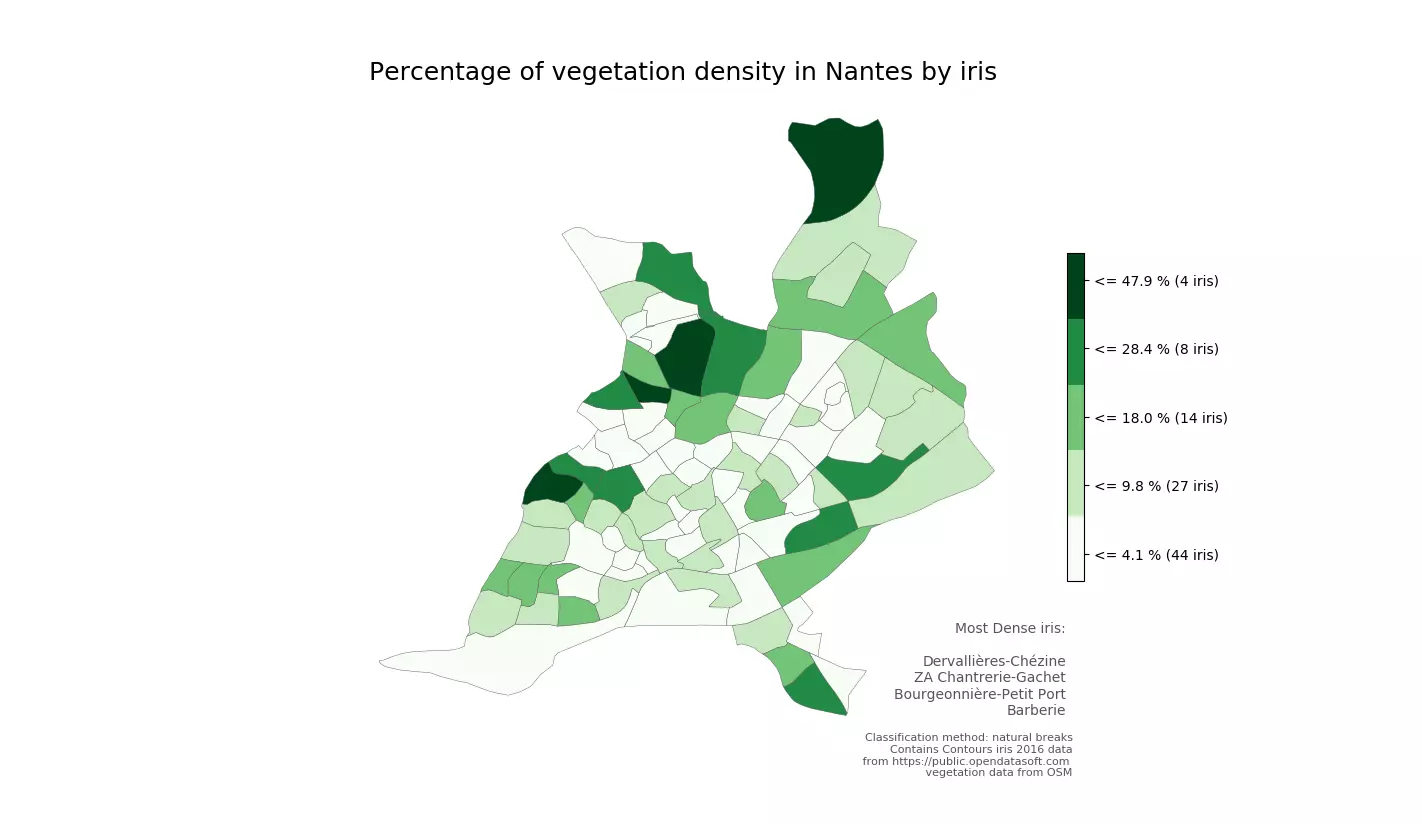
Figure 4 - Densité d’espaces verts à Nantes calculée à partir des données OSM
Presque la moitié des IRIS ont une densité d’espaces végétalisés inférieurs à 4%. Ce chiffre est particulièrement bas, notamment en centre-ville.
Résultats obtenus à partir d’images satellites et/ou aériennes
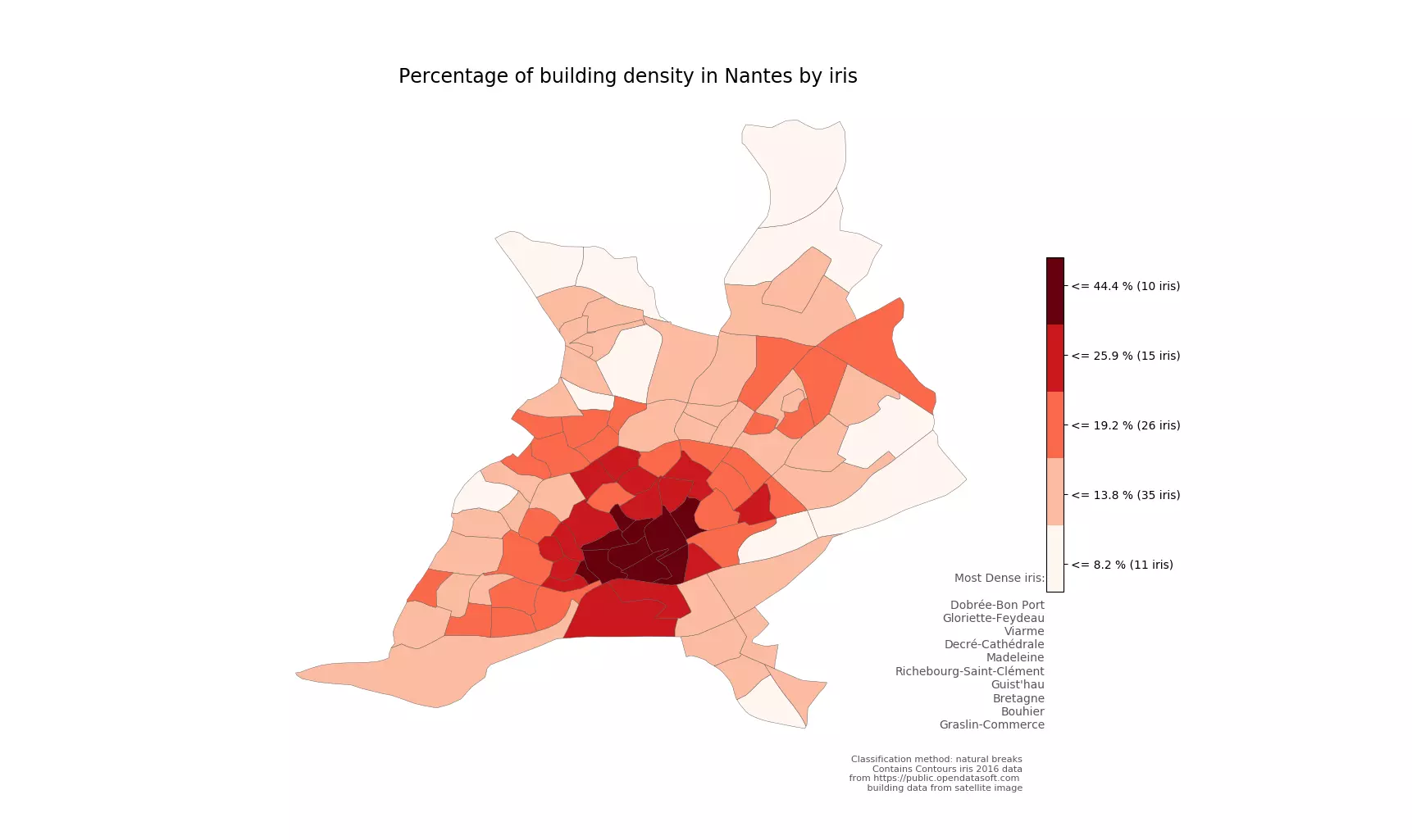
Figure 5 - Densité de bâtiments à Nantes calculée par deep learning
Pour obtenir la carte de la figure ci-dessus, un jeu de données d’entraînement a été utilisé qui compte 14000 images dont 4000 images ne présentent aucun bâtiment.
Cette carte est similaire à la celle de la figure 3 présentée précédemment, plus on se rapproche du centre, plus la densité est élevée.
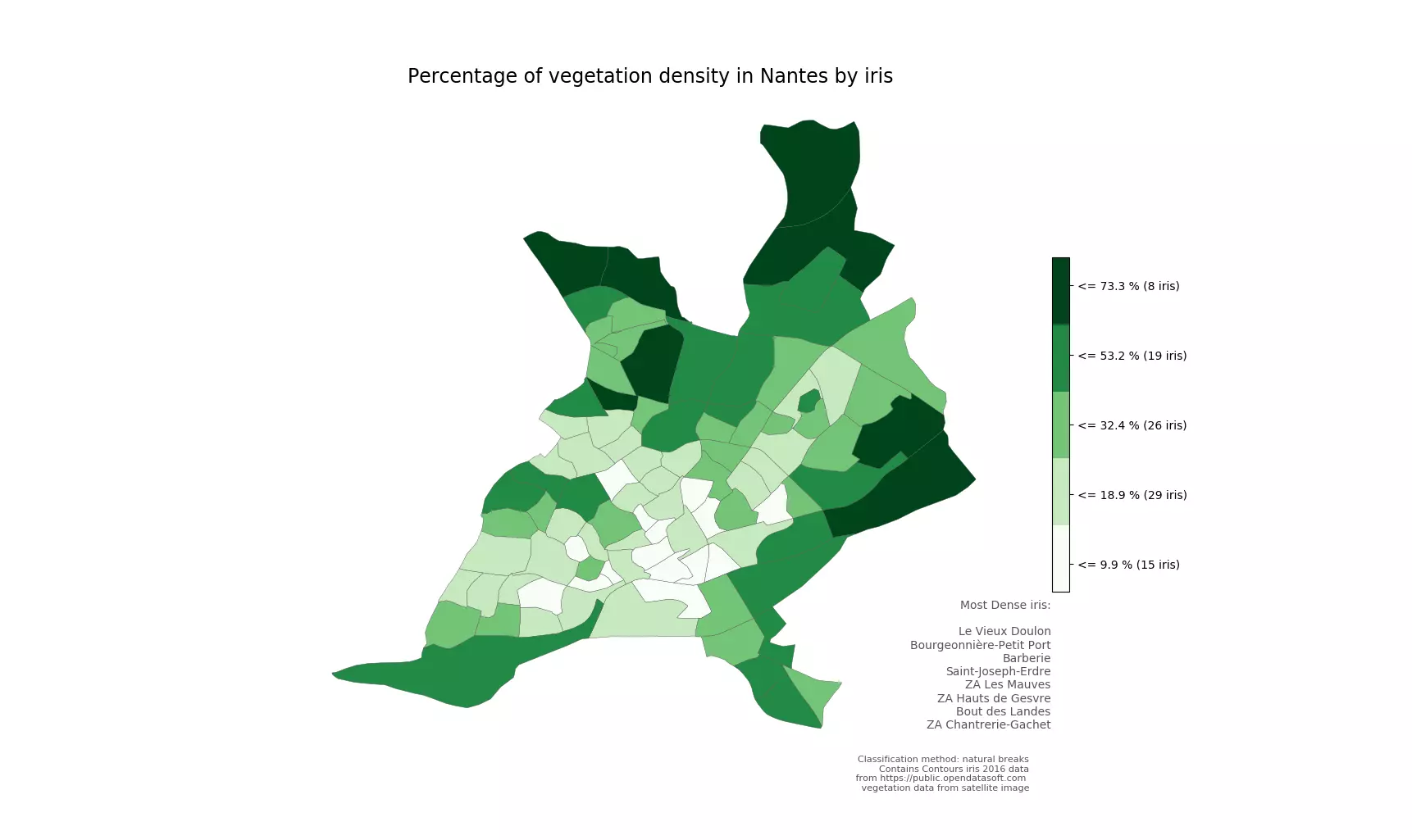
Figure 6 - Densité d’espaces verts à Nantes calculée par deep learning
Pour obtenir la carte de la figure 6, j’ai utilisé un jeu de données d’entraînement qui compte 16000 images. Cette carte est similaire à celle de la figure 4 présentée précédemment. Elle met en évidence la faible densité d’espaces verts en centre-ville. Plus l’on s’éloigne du centre-ville, plus la densité de surfaces végétalisées augmente, atteignant environ 20% en zones résidentielles.
Comparaison des densités de bâtiments obtenues par OSM ou analyse d'images.
Les résultats précédents sont comparés en calculant la différence entre le nombre de bâtiments détectés à partir d'OSM et celui à partir d'images et en la divisant par la surface de l'IRIS considérée.
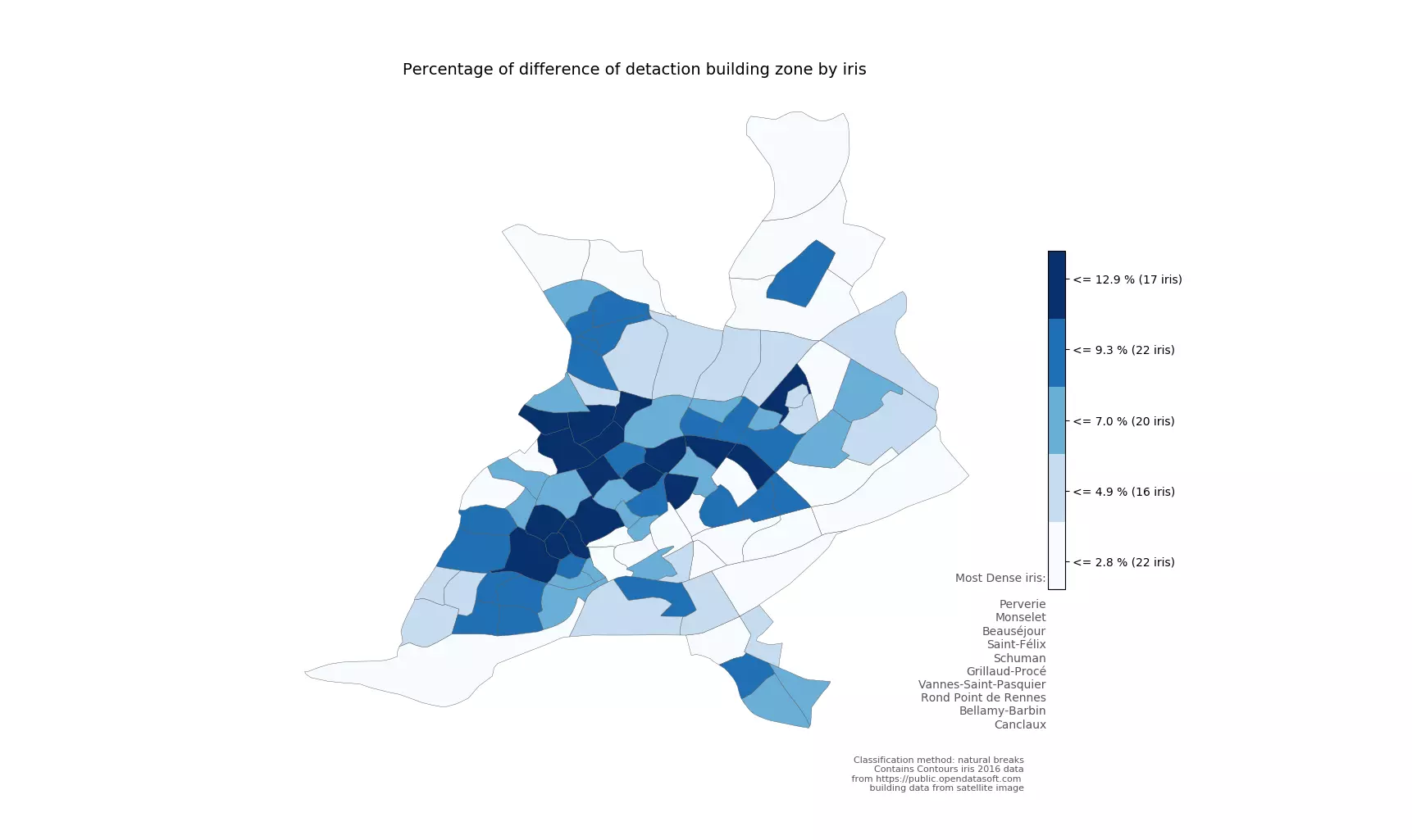
Figure 7 - La différence de la détection de bâtiments
Dans le plupart des IRIS de Nantes, les données d’OSM montrent davantage de bâtiments que l’analyse d’images. Globalement, il n’y pas beaucoup de différences entre les deux sources de données, le plus grand écart est de 12%.
Pour analyser les différences observées entre les deux méthodes, j’ai choisi 4 images, sur lesquelles sont superposées les bâtiments de la base OSM et la prédiction réalisée par notre modèle entraîné à détecter des bâtiments.

Figure 8 - Les masques oranges correspondent à l'emprise des bâtiments de la base OSM. Les masques bleus sont obtenus par la prédiction par deep learning.
On peut voir sur les images 8a, 8b et 8c que la prédiction des bâtiments faite par notre modèle entraîné n’est pas complète, il manque quelques parties. La différence des résultats peut en partie s’expliquer par le manque d’entraînement du modèle utilisé. On remarque aussi que les masques construits avec les données d’OSM sont un peu décalés par rapport aux images, ce qui peut avoir un impact sur l’apprentissage du modèle. Sur l’image 8d, notre modèle détecte un bâtiment même s’il n’y a pas de bâtiment. Nous sommes ici dans une zone industrielle où la surface est artificielle (peut-être du béton). Le modèle a identifié cette zone comme étant un bâtiment. Pour améliorer notre modèle, il faudrait aussi ajouter des images de surfaces artificielles dans le jeu de données d’entraînement.
Comparaison des densités d’espaces végétalisés obtenues par OSM ou analyse d'images
Les différences entre les résultats de densités d'espaces végétalisés sont obtenus de façon analogue aux différences entre les densités de bâtiments précédemment décrites.
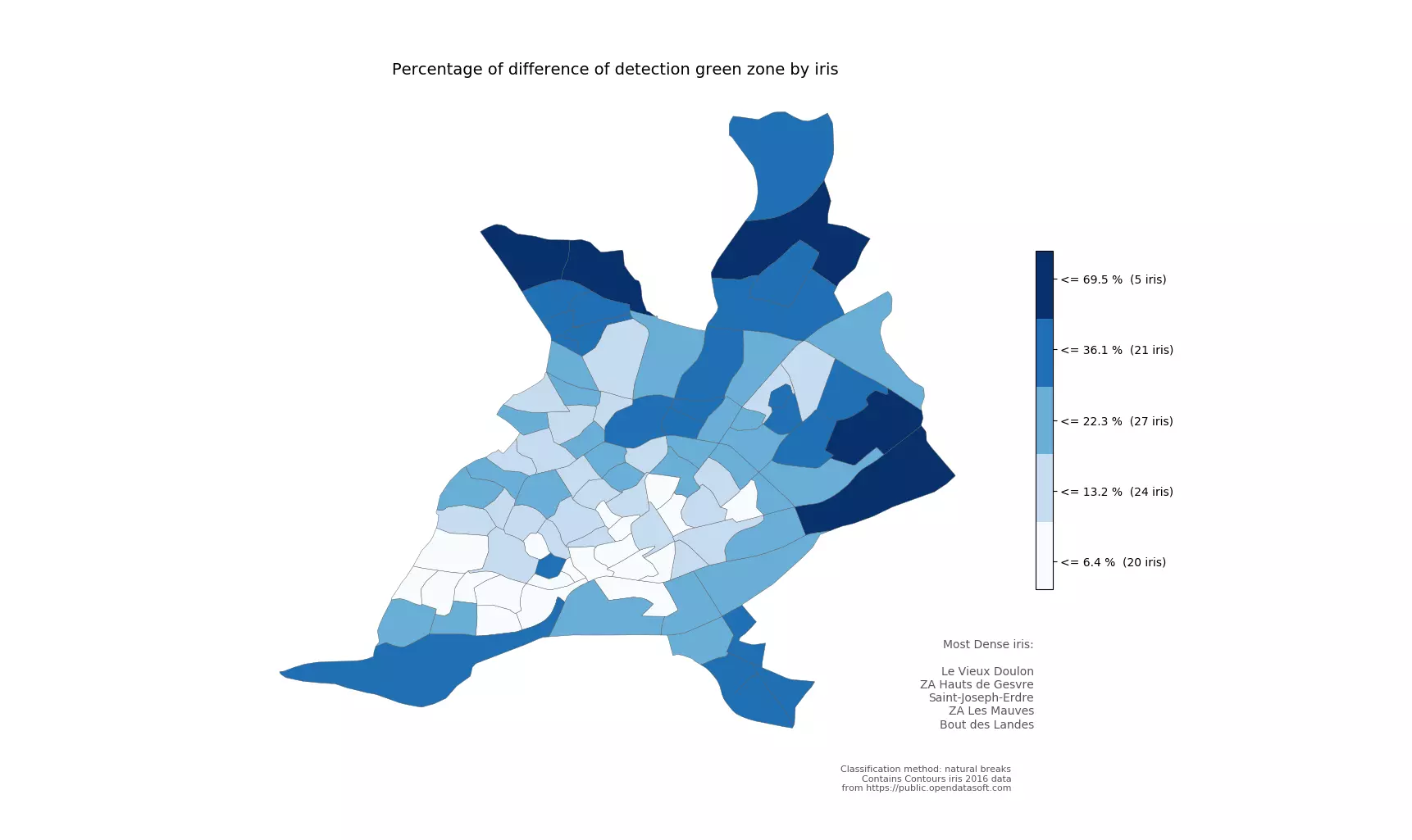
Figure 9 - La différence de la détection d'espaces végétalisés
Le calcul de densités d'espaces végétalisés par analyse d'images produit des résultats plus complets que le calcul réalisé sur les données de la base OSM. Ceci est bien visible dans les IRIS périphériques. En centre-ville, les différences sont faibles, dû à la faible présence d'espaces verts dans cet espace.
Pour examiner les différences observées par les deux méthodes, j’ai à nouveau choisi 4 images, sur lesquelles sont superposés les espaces verts recensés dans la base OSM et la prédiction réalisée par notre modèle entraîné à détecter des espaces végétalisés.

Figure 10 - Les masques orange correspondent à l'emprise des espaces verts de la base OSM.
Les masques bleus sont obtenus par la prédiction par deep learning. Le base OSM ne recensent pas les arbres, ni les espaces verts des propriétés privées. Les données présentes sont essentiellement celles des espaces publics comme les jardins, parcs ou forêts. Les images ont ici un réel intérêt, elles permettent d'analyser tous les types d'espaces verts.
Néanmoins, notre modèle mériterait d'être d'avantage entraîné car il crée des faux-positifs en détectant par exemple la rivière comme étant de la végétation (figure 10d, partie en bas à droite de l'image).
Conclusion
- Les modèles produits avec Robosat ne sont pas suffisamment entraînés, mais ils permettent déjà de montrer les possibilités offertes par ce projet.
- En fonction de l’indicateur recherché, les données OSM peuvent se montrer très partielles, comme c’est le cas pour l’étude des espaces végétalisés. Il est alors plus intéressant d'utiliser les données d'imagerie.
- En effet, images aériennes et satellitaires permettent d’analyser finement les informations de surface d’un territoire. Aussi, elles pourront être couplées aux données OSM pour la détermination d'indicateurs en lien avec les usages des territoires.
Si vous souhaitez prolonger ces travaux avec nous dans le cadre d'un stage ou apprendre à manipuler ces données, n'hésitez pas à nous contacter !

Responsable Innovation
Formations associées
Formations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations SIG / Cartographie
Formation Leaflet
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation LeafletActualités en lien
Deep clustering d'images aériennes
Data Science
09/02/2021
Cet article présente Deep Cluster, une méthode reposant sur l'utilisation conjointe d'un algorithme de clustering et d'un réseau de neurones (deep learning). Nous montrons que Deep Cluster réussit à grouper en ensembles cohérents des photographies aériennes récupérées via l'API Mapbox. Grâce à l'outil MLflow nous avons tracé et analysé les résultats obtenus par la méthode Deep Cluster. Dans cette publication nous donnerons quelques précisions sur l'utilisation de cet outil.

Extraction d'objets pour la cartographie par deep-learning : choix du modèle
SIG
02/06/2020
Deuxième article de la série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires.

Extraction d'objets pour la cartographie par deep-learning : création d'une vérité terrain
SIG
18/05/2020
Cette série d'articles parle de cartographie par deep-learning à partir d'images aériennes ou satellitaires. Dans ce 1er article, l'étape préliminaire à toute utilisation d'un modèle d'apprentissage supervisé est abordée: la création du jeu de données d'apprentissage. Notre outil geolabel-maker est mis à votre disposition pour vous aider.
