Makina Blog
Calculez sur GPU avec Python – Partie 2/3
Mise en œuvre de votre GPU avec CuPy et PyCUDA
Dans cette seconde partie, nous découvrons comment utiliser votre GPU avec la librairie CuPy, qui est l’équivalent de NumPy et vous permettra de calculer des matrices NumPy sur votre GPU sans changer plus d’une ligne à votre code !
Puis; nous rentrerons plus en profondeur dans l’écriture de code natif avec PyCUDA. Je vous rassure, dans la vraie vie on peut s’en passer. Mais pour comprendre les fondements, c’est une étape appropriée.
Un exemple avec CuPy
On ne peut pas se lancer dans le calcul sur GPU sans comprendre un minimum l’organisation logicielle/matérielle de ces systèmes. Ils ne se programment pas comme un CPU et, par exemple, avec numba, votre code Python devra être adapté en conséquence.
Mais, comme vous êtes certainement très impatients de toucher du doigt ce nouveau monde, voici un petit exemple avec CuPy qui va nous permettre de découvrir à la fois la simplicité de la librairie et la puissance de votre carte graphique.
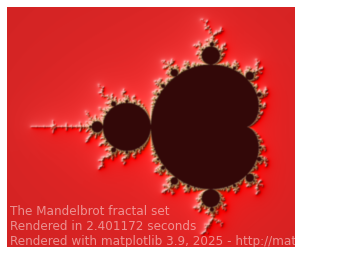
Nous vous proposons de dessiner la fractale de l’ensemble de Mandelbrot.
Pour cela nous allons repartir de l’exemple de matplotlib dont le code présente l’avantage de bien se prêter à l’exercice.
L’installation de la librairie CuPy est très simple via pip :
$ pip install cupy-<cuda version>
Dans notre exemple avec CUDA 12.6, ce sera :
$ pip install cupy-cuda12x
Si vous utilisez Miniforge/Conda/Mamba :
$ mamba install cupy
CuPy implémente globalement la même API que NumPy. On peut donc remplacer la librairie NumPy par CuPy et le tour est joué:
En remplaçant le seul import :
import numpy as np
Par ce dernier :
import cupy as np
Votre programme exécutera ses calculs sur GPU sans autre effort.
Mais cela c’est la théorie dans un monde parfait. La pratique n’est pas aussi simple si l’on veut des résultats à la hauteur des capacités de votre GPU.
Dans l’exemple proposé ci-dessous, 2 fonctions mandelbrot_set ont été définies.
mandelbrot_set_np: correspond à l’implémentation avec NumPy du calcul de la fractalemandelbrot_set_cp: correspond à l’implémentation avec CuPy du calcul de la fractale
Voici, les changements opérés entre les 2 versions de la fonction par rapport au code original de l’exemple Matplotlib :
- Dans
mandelbrot_set_cple modulenpa été remplacé parcp - Dans les 2 versions le troisième paramètre de
linspacea été converti en entier,int(xn):- Cela évite les warning NumPy
- Cela évite une erreur CuPy (
TypeError: 'float' object cannot be interpreted as an integer)
- La fonction
abs(Z)a été remplacée parcp/np.abs(Z) - La fonction CuPy doit en plus convertir son résultat en tableau NumPy pour l’affichage final.
C’est le transfert des données stockées dans la RAM du GPU vers celle du CPU, sinon matplotlib ne saura pas afficher l’image générée. - Enfin, dans la version CuPy, nous avons ajouté un bloc
withpermettant de choisir le GPU sur lequel le calcul sera exécuté lorsque vous en possédez plusieurs
La fonction compute prend quant à elle en paramètre la fonction mandelbrot_set qui sera utilisée pour le calcul de la fractale (avec en option le numéro du GPU pour la version CuPy) et exécute le calcul de la fractale puis l’affiche en indiquant le temps de calcul mesuré.
import numpy as np
import time
import matplotlib
from matplotlib import colors
import matplotlib.pyplot as plt
from timeit import default_timer as timer
import cupy as cp
def mandelbrot_set_np(xmin, xmax, ymin, ymax, xn, yn, maxiter, horizon=2.0, dummy=None):
X = np.linspace(xmin, xmax, int(xn), dtype=np.float32)
Y = np.linspace(ymin, ymax, int(yn), dtype=np.float32)
C = X + Y[:, None]*1j
N = np.zeros(C.shape, dtype=np.int64)
Z = np.zeros(C.shape, np.complex64)
for n in range(maxiter):
I = np.less(np.abs(Z), horizon)
N[I] = n
Z[I] = Z[I]**2 + C[I]
N[N == maxiter-1] = 0
return Z, N
def mandelbrot_set_cp(xmin, xmax, ymin, ymax, xn, yn, maxiter, horizon=2.0, gpu_number=0):
with cp.cuda.Device(gpu_number): # Choosing the GPU to use
# Just renaming NP with CP
X = cp.linspace(xmin, xmax, int(xn), dtype=cp.float32)
Y = cp.linspace(ymin, ymax, int(yn), dtype=cp.float32)
C = X + Y[:, None]*1j
N = cp.zeros(C.shape, dtype=cp.int64)
Z = cp.zeros(C.shape, cp.complex64)
for n in range(maxiter):
I = cp.less(cp.abs(Z), horizon)
N[I] = n
Z[I] = Z[I]**2 + C[I]
N[N == maxiter-1] = 0
return cp.asnumpy(Z), cp.asnumpy(N) # Convert CP tables (stored in GPU to NP table in CPU RAM)
def compute(compute_set, gpu=0):
xmin, xmax, xn = -2.25, +0.75, 3000/2
ymin, ymax, yn = -1.25, +1.25, 2500/2
maxiter = 400
horizon = 2.0 ** 40
log_horizon = np.log(np.log(horizon))/np.log(2)
start = timer()
Z, N = compute_set(xmin, xmax, ymin, ymax, xn, yn, maxiter, horizon, gpu)
stop = timer()
msg = "Rendered in %08.6f seconds\n" % (stop - start)
print(msg)
# Normalized recount as explained in:
# https://linas.org/art-gallery/escape/smooth.html
# https://www.ibm.com/developerworks/community/blogs/jfp/entry/My_Christmas_Gift
# This line will generate warnings for null values but it is faster to
# process them afterwards using the nan_to_num
with np.errstate(invalid='ignore'):
M = np.nan_to_num(N + 1 -
np.log(np.log(abs(Z)))/np.log(2) +
log_horizon)
dpi = 72
width = 4
height = 4*yn/xn
fig = plt.figure(figsize=(width, height), dpi=dpi)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0], frameon=False, aspect=1)
# Shaded rendering
light = colors.LightSource(azdeg=315, altdeg=10)
M = light.shade(M, cmap=plt.cm.hot, vert_exag=1.5,
norm=colors.PowerNorm(0.3), blend_mode='hsv')
plt.imshow(M, extent=[xmin, xmax, ymin, ymax], interpolation="bicubic")
ax.set_xticks([])
ax.set_yticks([])
# Some advertisement for matplotlib
year = time.strftime("%Y")
major, minor, micro = matplotlib.__version__.split('.', 2)
text = ("The Mandelbrot fractal set\n" +
msg +
"Rendered with matplotlib %s.%s, %s - http://matplotlib.org"
% (major, minor, year))
ax.text(xmin+.025, ymin+.025, text, color="white", fontsize=12, alpha=0.5)
plt.show()
compute(mandelbrot_set_np, gpu=None)
Rendered in 2.401172 seconds
Le premier appel à CuPy ne sera pas miraculeux, car il intègre le temps de compilation du code sur le GPU, cela est assez couteux…
compute(mandelbrot_set_cp, gpu=0)
Rendered in 0.647558 seconds

Si vous le relancez, le code étant déjà compilé, le temps sera meilleur.
compute(mandelbrot_set_cp, gpu=0)
Rendered in 0.374514 seconds

print("Ratio CPU/GPU:", 2.5/0.37)
Ratio CPU/GPU: 6.756756756756757
Avec très peu de modifications, nous avons exécuté le calcul sur GPU. Le véritable changement consiste à avoir renommé numpy en cupy.
C’est trop facile avec Python !
La carte graphique offre un gain d’environ x6/7 par rapport à la version NumPy sur CPU. C’est déjà bien.
Mais c’est un succès très mitigé si nous regardons le nombre total d’opérations que chaque processeur peut réaliser à la seconde.
Comparons les caractéristiques des 2 processeurs pour connaître leurs performances.
!lscpu | grep -v Drapaux | grep -v Vulnerability
Architecture : x86_64
Mode(s) opératoire(s) des processeurs : 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Boutisme : Little Endian
Processeur(s) : 12
Liste de processeur(s) en ligne : 0-11
Identifiant constructeur : GenuineIntel
Nom de modèle : Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz
Famille de processeur : 6
Modèle : 158
Thread(s) par cœur : 2
Cœur(s) par socket : 6
Socket(s) : 1
Révision : 10
CPU(s) scaling MHz: 93%
Vitesse maximale du processeur en MHz : 4600,0000
Vitesse minimale du processeur en MHz : 800,0000
BogoMIPS : 6399,96
Virtualisation : VT-x
Cache L1d : 192 KiB (6 instances)
Cache L1i : 192 KiB (6 instances)
Cache L2 : 1,5 MiB (6 instances)
Cache L3 : 12 MiB (1 instance)
Nœud(s) NUMA : 1
Nœud NUMA 0 de processeur(s) : 0-11
Le CPU utilisé est un processeur Intel i7 de huitième génération :
- Il possède une fréquence de 4,6Ghz.
- Il dispose de 6 cœurs physiques et 12 hyperthreads, soit 2 hyperthreads par cœur.
Les hyperthreads sont des cœurs virtuels/logiques. Tous les processeurs n’en possèdent pas. Quand un processeur en est doté, un seul hyperthread fonctionne sur le cœur physique à la fois, comme évoqué dans le chapitre de présentation des concepts du parallélisme.
Les hyperthreads sont utilisés uniquement quand le processeur réalise des opérations d’entrée/sortie : plutôt que de perdre de précieuses millisecondes à patienter pour attendre que le disque dur ait fini d’écrire ce qu’il a en cours et lui envoyer la suite, le processeur bascule sur le second hyperthread et peut ainsi exécuter d’autres tâches pendant cette attente.
Dans le cas d’un calcul numérique comme ici, il n’y a pas de véritable opération d’entrée/sortie, les hyperthreads ne sont pas utilisés.
La fréquence représente le nombre de cycles qu’un processeur peut réaliser en 1 seconde. Ici 4,6 milliards.
Un cycle est le temps qu’il faut au processeur pour changer l’état d’un bit. Dans un ordinateur, en général un bit est représenté par un transistor possédant une tension de 0 ou 5 volts. Si sa tension est nulle, il vaut 0, sinon, il vaut 1. Quand la valeur du bit passe de 0 à 1, sa tension croit progressivement jusqu’à 5 volts. Tant que la tension lue n’est pas égale soit à 0 soit à 5, son état est instable et sa valeur indéterminée. Il ne peut pas être utilisé pour le calcul.
La fréquence représente donc le nombre de changements de bits que le processeur peut faire à la seconde.
Certaines opérations ne demandent qu’un cycle machine, comme inverser l’état des bits d’un registre. D’autres peuvent demander plusieurs cycles. Comme charger un registre avec des données issues de la RAM.
Pour simplifier, disons qu’un cycle représente 1 instruction du processeur.
Nous avons donc un CPU pouvant exécuter : 27.6 milliards d’instructions à la seconde
nb_coeurs = 6
frequence = 4.6 # en Giga Hertz
nombre_instructions_cpu = nb_coeurs * frequence
print("Nombre d'instructions à la seconde du CPU en milliards:", nombre_instructions_cpu)
Nombre d'instructions à la seconde du CPU en milliards : 27.599999999999998
Regardons maintenant du côté de la carte graphique :
!nvidia-smi
Mon Jan 27 15:09:44 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2070 Off | 00000000:01:00.0 On | N/A |
| N/A 48C P0 31W / 115W | 1114MiB / 8192MiB | 8% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1722 G /usr/lib/xorg/Xorg 503MiB |
| 0 N/A N/A 2762 G cinnamon 41MiB |
| 0 N/A N/A 3392 G /usr/bin/nextcloud 1MiB |
| 0 N/A N/A 3903 G /usr/lib/firefox/firefox 0MiB |
| 0 N/A N/A 21959 C ...lib/libreoffice/program/soffice.bin 92MiB |
| 0 N/A N/A 32453 C ...s/miniforge3/envs/rapids/bin/python 218MiB |
+-----------------------------------------------------------------------------------------+
Il s’agit d’une RTX 2070.
Comme le montrent la commande deviceQuery exécutée plus tôt ou la documentation NVIDIA, elle dispose de 2304 cœurs et d’une fréquence maximale de 1,71Ghz.
Soit un total de 3 939.94 milliards d’instructions à la seconde.
nb_coeurs = 2304
frequence = 1.71 # en Giga Hertz
nombre_instructions_gpu = nb_coeurs * frequence
print("Nombre d'instructions à la seconde du GPU en milliards:", nombre_instructions_gpu)
Nombre d'instructions à la seconde du GPU en milliards : 3939.84
Nous aurions donc pu espérer un rapport de vitesse environ 142 fois plus rapide en faveur du GPU. Nous en sommes loin.
nombre_instructions_gpu / nombre_instructions_cpu
142.74782608695654
Remarque
Nous avons comparé le nombre de cycles des processeurs pour comparer leur puissance respective.
Dans cet exemple, les calculs sont réalisés avec des réels 32 bits.Il aurait été plus juste d’utiliser les FLOPS (Floating Point Operation Per Second) comme mesure.
Les flops représentent le nombre d’opérations sur des réels que peuvent réaliser des processeurs en 1 seconde.Dans ce dernier cas, le processeur Intel possède des instructions SIMD – Single Instruction Multiple Data, aussi appelées vectorielles, de type AVX2 qui permettent d’exécuter des opérations sur 8 réels 32 bits simultanément en 1 cycle.
bash$ lscpu | grep -i drapaux Drapaux : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb pti ssbd ibrs ibpb stibp tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp vnmi md_clear flush_l1d arch_capabilitiesIl conviendrait donc de diviser ce ratio par 8. (soit 17.75 fois plus rapide pour le GPU)
Les cartes NVIDIA possèdent aussi des instructions SIMD pour les modèles ayant les capacités de calcul 3.0 jusqu’à 5.0. Cependant, elles ont été retirées pour la plupart à partir de la capacité 5.0. Mais ceci est un autre sujet.
Nous reviendrons plus tard sur la notion de capacité de calcul de la carte qui correspond à une nomenclature interne à NVIDIA. Pour information, la carte RTX 2070 correspond à la nomemclature 7.5 comme affiché par la commande
deviceQueryprécédente ; elle ne possède que peu d’instructions SIMD (uniquement un jeu réduit pour la vidéo et les nombres entiers).
142/8 # Ratio GPU/CPU en tenant compte des instructions SIMD du processeur
17.75
Question : Pourquoi notre test CuPy n’a-t-il pas montré un tel gain ?
Il est en effet plus de 3 fois inférieur au ratio que l’on pourrait espérer ?
Nous allons tenter d’apporter des éléments de réponses avec un autre test réalisé via la librairie PyCuda.
Un autre exemple avec PyCuda
Continuons donc, pour assouvir votre soif de connaissances et d’expérimentation de votre carte graphique dernier cri, avec la librairie PyCuda.
PyCuda est un projet proche de PyOpenCL. Elle permet d’utiliser l’API CUDA (langage C) des cartes NVIDIA depuis Python.
Elle ne fonctionne qu’avec les cartes NVIDIA.
PyCuda ne s’installe pas très facilement si votre toolkit NVIDIA n’est pas bien configuré au niveau du système.
Pensez à vérifier que le compilateur nvcc est bien dans le PATH système. A défaut, ajoutez-le comme présenté dans le paragraphe sur la compilation.
N’oubliez pas de redémarrer Jupyter pour qu’il ait connaissance de ce changement.
Ensuite, l’installation avec pip sera assez facile :
$ pip install pycuda
Collecting pycuda
...
Successfully built pycuda
Installing collected packages: pycuda
Successfully installed pycuda-<version>
PyCUDA permet d’utiliser la librairie CUDA directement depuis Python, avec quelques avantages :
- Elle gère la mémoire pour vous, vous n’aurez pas à vous soucier des allocations et libérations de mémoire
- Elle offre une classe GPUArray qui facilite l’échange de données entre le CPU et le GPU
- Elle propose depuis Python un accès à l’intégralité de la librairie CUDA, mais cela imposera souvent d’écrire des bouts de codes en C qui seront tranmis à la librairie
Avant de commencer à lancer des calculs sur votre GPU, il convient de charger, puis d’initialiser le driver de la carte graphique :
import pycuda.driver as drv
drv.init()
Nous disposons alors de quelques fonctions pour identifier la configuration du matériel :
drv.Device.count() # Nombre de GPU disponibles
1
gpu0 = drv.Device(0) # Accès au premier GPU
gpu0.name() # Nom de la carte
'NVIDIA GeForce RTX 2070'
gpu0.total_memory() # mémoire disponible pour le GPU
8144093184
gpu0.pci_bus_id() # BUS PCI utilisé
'0000:01:00.0'
La méthode get_attributes fournira beaucoup d’autres informations :
attributes = gpu0.get_attributes() # Dictionary containing gpu specifications
for attr, value in attributes.items():
print(f"{attr} : {value}")
ASYNC_ENGINE_COUNT : 3
CAN_MAP_HOST_MEMORY : 1
CAN_USE_HOST_POINTER_FOR_REGISTERED_MEM : 1
CLOCK_RATE : 1440000
COMPUTE_CAPABILITY_MAJOR : 7
COMPUTE_CAPABILITY_MINOR : 5
COMPUTE_MODE : DEFAULT
COMPUTE_PREEMPTION_SUPPORTED : 1
CONCURRENT_KERNELS : 1
CONCURRENT_MANAGED_ACCESS : 1
DIRECT_MANAGED_MEM_ACCESS_FROM_HOST : 0
ECC_ENABLED : 0
GENERIC_COMPRESSION_SUPPORTED : 0
GLOBAL_L1_CACHE_SUPPORTED : 1
GLOBAL_MEMORY_BUS_WIDTH : 256
GPU_OVERLAP : 1
HANDLE_TYPE_POSIX_FILE_DESCRIPTOR_SUPPORTED : 1
HANDLE_TYPE_WIN32_HANDLE_SUPPORTED : 0
HANDLE_TYPE_WIN32_KMT_HANDLE_SUPPORTED : 0
HOST_NATIVE_ATOMIC_SUPPORTED : 0
INTEGRATED : 0
KERNEL_EXEC_TIMEOUT : 1
L2_CACHE_SIZE : 4194304
LOCAL_L1_CACHE_SUPPORTED : 1
MANAGED_MEMORY : 1
MAXIMUM_SURFACE1D_LAYERED_LAYERS : 2048
MAXIMUM_SURFACE1D_LAYERED_WIDTH : 32768
MAXIMUM_SURFACE1D_WIDTH : 32768
MAXIMUM_SURFACE2D_HEIGHT : 65536
MAXIMUM_SURFACE2D_LAYERED_HEIGHT : 32768
MAXIMUM_SURFACE2D_LAYERED_LAYERS : 2048
MAXIMUM_SURFACE2D_LAYERED_WIDTH : 32768
MAXIMUM_SURFACE2D_WIDTH : 131072
MAXIMUM_SURFACE3D_DEPTH : 16384
MAXIMUM_SURFACE3D_HEIGHT : 16384
MAXIMUM_SURFACE3D_WIDTH : 16384
MAXIMUM_SURFACECUBEMAP_LAYERED_LAYERS : 2046
MAXIMUM_SURFACECUBEMAP_LAYERED_WIDTH : 32768
MAXIMUM_SURFACECUBEMAP_WIDTH : 32768
MAXIMUM_TEXTURE1D_LAYERED_LAYERS : 2048
MAXIMUM_TEXTURE1D_LAYERED_WIDTH : 32768
MAXIMUM_TEXTURE1D_LINEAR_WIDTH : 268435456
MAXIMUM_TEXTURE1D_MIPMAPPED_WIDTH : 32768
MAXIMUM_TEXTURE1D_WIDTH : 131072
MAXIMUM_TEXTURE2D_ARRAY_HEIGHT : 32768
MAXIMUM_TEXTURE2D_ARRAY_NUMSLICES : 2048
MAXIMUM_TEXTURE2D_ARRAY_WIDTH : 32768
MAXIMUM_TEXTURE2D_GATHER_HEIGHT : 32768
MAXIMUM_TEXTURE2D_GATHER_WIDTH : 32768
MAXIMUM_TEXTURE2D_HEIGHT : 65536
MAXIMUM_TEXTURE2D_LINEAR_HEIGHT : 65000
MAXIMUM_TEXTURE2D_LINEAR_PITCH : 2097120
MAXIMUM_TEXTURE2D_LINEAR_WIDTH : 131072
MAXIMUM_TEXTURE2D_MIPMAPPED_HEIGHT : 32768
MAXIMUM_TEXTURE2D_MIPMAPPED_WIDTH : 32768
MAXIMUM_TEXTURE2D_WIDTH : 131072
MAXIMUM_TEXTURE3D_DEPTH : 16384
MAXIMUM_TEXTURE3D_DEPTH_ALTERNATE : 32768
MAXIMUM_TEXTURE3D_HEIGHT : 16384
MAXIMUM_TEXTURE3D_HEIGHT_ALTERNATE : 8192
MAXIMUM_TEXTURE3D_WIDTH : 16384
MAXIMUM_TEXTURE3D_WIDTH_ALTERNATE : 8192
MAXIMUM_TEXTURECUBEMAP_LAYERED_LAYERS : 2046
MAXIMUM_TEXTURECUBEMAP_LAYERED_WIDTH : 32768
MAXIMUM_TEXTURECUBEMAP_WIDTH : 32768
MAX_BLOCKS_PER_MULTIPROCESSOR : 16
MAX_BLOCK_DIM_X : 1024
MAX_BLOCK_DIM_Y : 1024
MAX_BLOCK_DIM_Z : 64
MAX_GRID_DIM_X : 2147483647
MAX_GRID_DIM_Y : 65535
MAX_GRID_DIM_Z : 65535
MAX_PERSISTING_L2_CACHE_SIZE : 0
MAX_PITCH : 2147483647
MAX_REGISTERS_PER_BLOCK : 65536
MAX_REGISTERS_PER_MULTIPROCESSOR : 65536
MAX_SHARED_MEMORY_PER_BLOCK : 49152
MAX_SHARED_MEMORY_PER_BLOCK_OPTIN : 65536
MAX_SHARED_MEMORY_PER_MULTIPROCESSOR : 65536
MAX_THREADS_PER_BLOCK : 1024
MAX_THREADS_PER_MULTIPROCESSOR : 1024
MEMORY_CLOCK_RATE : 7001000
MEMORY_POOLS_SUPPORTED : 1
MULTIPROCESSOR_COUNT : 36
MULTI_GPU_BOARD : 0
MULTI_GPU_BOARD_GROUP_ID : 0
PAGEABLE_MEMORY_ACCESS : 1
PAGEABLE_MEMORY_ACCESS_USES_HOST_PAGE_TABLES : 0
PCI_BUS_ID : 1
PCI_DEVICE_ID : 0
PCI_DOMAIN_ID : 0
READ_ONLY_HOST_REGISTER_SUPPORTED : 0
RESERVED_SHARED_MEMORY_PER_BLOCK : 0
SINGLE_TO_DOUBLE_PRECISION_PERF_RATIO : 32
STREAM_PRIORITIES_SUPPORTED : 1
SURFACE_ALIGNMENT : 512
TCC_DRIVER : 0
TEXTURE_ALIGNMENT : 512
TEXTURE_PITCH_ALIGNMENT : 32
TOTAL_CONSTANT_MEMORY : 65536
UNIFIED_ADDRESSING : 1
WARP_SIZE : 32
Nous avons maintenant un aperçu de comment nous pouvons interroger le matériel dont nous disposons.
Utilisons cet exemple issu de la page d’accueil du site de PyCuda afin d’éprouver une nouvelle fois la puissance de ce GPU.
Ici, le programme présenté utilise un petit bout de code C pour définir la fonction qui sera lancée sur le GPU. En effet, CUDA permet à la base d’exécuter des programmes écrits en langage C. Aussi, il est souvent nécessaire de devoir écrire quelques fonctions en C avec PyCuda.
Le bout de code ci-après est une petite astuce dans votre notebook pour vous assurer que Python trouvera bien votre compilateur nvcc requis pour la suite du TP.
import os
print(os.environ['PATH'])
os.environ['PATH'] += ':/usr/local/cuda/bin'
/usr/local/cuda/bin:/home/aliquis/miniforge3/envs/JBook/bin:/home/aliquis/miniforge3/condabin:/home/aliquis/.local/bin:/home/aliquis/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
Dans ce programme la fonction multiply_them multiplie 2 tableaux de réels, a et b pour stocker le résultat dans un tableau dest
import pycuda.autoinit # Another way to initialize the GPU driver
import pycuda.driver as drv # Here it is loaded
from pycuda.compiler import SourceModule # Use to compile C functions for Cuda using nvcc
import numpy as np
# Mod will compile the C function
mod = SourceModule("""
__global__ void multiply_them(float *dest, float *a, float *b)
{
const int i = threadIdx.x;
dest[i] = a[i] * b[i];
}
""")
# Then the C function is retrieved this way so it can be called directly from Python
multiply_them = mod.get_function("multiply_them")
Quelques explications :
- La fonction C, qui est créée, est celle qui sera exécutée sur le GPU.
On l’appelle fonction device.
Elle prend 3 tableaux de réels 32 bits en entrée (pointeurs float)
Le premier contiendra le résultat, les 2 autres sont les vecteurs que l’on souhaite multiplier. - Remarquez qu’aucune boucle n’est réalisée pour multiplier tous les éléments des tableaux
Au lieu de cela, la fonction récupère l’indice de l’élément qu’elle doit calculer viaThreadIdx.x - La fonction C qui aura été compilée dans la foulée par
SourceModuleest rendue accessible en Python via la méthodeget_function
Comment la fonction itère-t-elle sur tous les éléments du tableau ?
En effet, elle ne manipule qu’un élément à l’indice
threadIdx.x. Il n’y a pas de boucle.Le concept est le suivant: quand le GPU va lancer le calcul il va lancer cette fonction sur> différents cœurs/threads en parallèle. Chaque cœur/thread possède un indice – ici
threadIdx.x– et s’occupera de la case située à cet indice.Il n’y a donc pas besoin d’une boucle. Mais il faudra indiquer au GPU combien de fois la fonction devra être lancée : autant qu’il y a d’éléments dans le tableau !
Réalisons le même travail avec NumPy :
a = np.random.randn(400).astype(np.float32) # We create 2 tables of numpy numbers having 400 items
b = np.random.randn(400).astype(np.float32) # single precision is used as GPU are computing
# most of the time with float having 32 bits
dest = np.zeros_like(a) # dest is a table full of zeros and having same size as a !
print(a[:5])
print(b[:5])
print(dest[:5])
[-0.00555495 0.25411418 -0.49110463 0.31549597 -0.17547004]
[0.42375204 0.90399384 0.1391739 0.44877696 1.2170142 ]
[0. 0. 0. 0. 0.]
Mesurons le temps d’exécution de a * b avec NumPy sur CPU :
%timeit dest = a * b
422 ns ± 5.96 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
r = a * b
print(r[:5])
[-0.00235392 0.22971766 -0.06834894 0.14158732 -0.21354952]
Là aussi, il n’y a pas de boucle dans notre code. Mais elle existe bien dans la réalité : c’est l’opérateur * implémenté dans la classe NDArray de NumPy qui la réalise pour nous. Numpy ne travaille que sur 1 seul cœur. La librairie n’est pas parallélisée sur tous les cœurs de la machine.
Dans cet exemple, le résultat devrait être environ, en termes de nombre de cycles, (142 * 6) fois plus rapide en faveur de CuPy…
Excepté que nous n’utilisons que 400 cœurs du GPU.
Le ration devrait donc être :
nb_coeurs = 400
frequence = 1.71 # en Giga Hertz
nombre_instructions_gpu_400 = nb_coeurs * frequence
nb_coeurs = 1
frequence = 4.6 # en Giga Hertz
nombre_instructions_cpu_1 = nb_coeurs * frequence
nombre_instructions_gpu_400 / nombre_instructions_cpu_1 # 148 fois plus rapide en théorie...
148.69565217391306
Vérifions cela :
import cupy as cp
ac = cp.random.randn(400).astype(cp.float32)
bc = cp.random.randn(400).astype(cp.float32)
destc = cp.zeros_like(ac) # dest is a table full of zeros and having same size as a !
print(ac[:5])
print(bc[:5])
print(destc[:5])
[-1.6642687 0.7745935 1.227624 0.5488435 -0.55261844]
[-1.9712749 -0.49186102 -0.06115467 0.69422895 0.68600804]
[0. 0. 0. 0. 0.]
%timeit destc = ac * bc
10.6 μs ± 46.9 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
10.6 / 0.422 # 10us pour cupy contre 422ns soit 0.422us pour numpy...
25.118483412322274
Mais nous sommes 25 fois plus lent que le CPU ! Cela peut sembler n’avoir aucun sens !
Sur 1 seul cœur, le CPU est 25 fois plus rapide que le GPU qui utilise normalement 400 cœurs dans cet exemple !
Misère ! Remboursez-nous cette carte graphique, elle ne semble pas fonctionner correctement !
Vérifions la mesure avec la fonction multiply_them.
Nous allons pouvoir lancer le même calcul sur le GPU avec la fonction précédemment créée.
- Il convient pour cela de transmettre les tableaux Numpy à la carte graphique, car, rappelez-vous, le GPU travaille dans sa propre mémoire.
Ceci est réalisé via les fonctions
drv.Inci-après. - Pour récupérer le résultat, la fonction
drv.Outest utilisée afin de transmettre les données de la RAM du GPU vers le CPU - Les paramètres block et grid définissent la « matrice » des cœurs de calculs qui seront utilisés.
Ces notions seront détaillées dans la section suivante.
Ici nous réservons une grille de 400 cœurs/threads. - Nous avons un tableau de 400 éléments, les 400 multiplications seront réalisées en parallèle.
Sous réserve que la carte dispose de suffisamment de cœurs (elle en a plus de 2000)
import numpy as np
a = np.random.randn(400).astype(np.float32) # We create 2 tables of numpy numbers having 400 items
b = np.random.randn(400).astype(np.float32) # single precision is used as GPU are computing
# most of the time with float having 32 bits
dest = np.zeros_like(a)
print(dest[:5])
multiply_them( drv.Out(dest)
, drv.In(a)
, drv.In(b)
, block=(400, 1, 1)
, grid=(1, 1) )
print(a[:5])
print(b[:5])
print(dest[:5])
[0. 0. 0. 0. 0.]
[-0.08468395 0.18728326 1.7134982 -1.051074 -0.35594532]
[-0.8216796 -0.07424407 0.8293001 -0.8038413 -1.1592786 ]
[ 0.06958307 -0.01390467 1.4210043 0.84489673 0.4126398 ]
print( sum(a*b - dest) ) # checking that result is good
0.0
Maintenant que nous avons vérifié que le programme fonctionnait correctement, nous pouvons calculer son temps d’exécution :
%timeit multiply_them( drv.Out(dest), drv.In(a), drv.In(b), block=(400, 1, 1), grid=(1, 1) )
164 μs ± 2.29 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
164/0.422 # 388 times slower for the GPU :(
388.6255924170616
Misère !
Mais c’est encore pire ! Avec une fonction écrite en langage C – et il est difficile de faire plus concis, le GPU est cette fois plus de 388 fois plus lent que le CPU.
Mais que se passe-t-il avec cette carte ?
Afin d’obtenir de véritables performances en faveur du GPU, il convient de comprendre un peu plus l’architecture d’un GPU.
Nous vous proposons de plonger plus en profondeur dans l’architecture matérielle de votre carte avec la troisième partie de cette série d’articles.
En savoir plus
Formations associées
Formations IA / Data Science
Formation Python Calcul Scientifique
Toulouse Du 22 au 24 septembre 2026
Voir la Formation Python Calcul ScientifiqueAteliers Data Science
Parcours complet Data Science
Nantes - Toulouse - Paris ou distanciel Nous contacter
Voir la Parcours complet Data ScienceFormations IA / Data Science
Formation Python scientifique
Toulouse Du 21 au 25 septembre 2025
Voir la Formation Python scientifiqueActualités en lien
Calculez sur GPU avec Python – Partie 3/3
Data Science
20/02/2025

Calculez sur GPU avec Python – Partie 1/3
Data Science
04/02/2025

Notre expertise en Data science
Data Science
27/03/2019
L'IA est un domaine vaste et nos différents projets nous ont permis de monter en compétences sur plusieurs sujets. Cet article vous présente les thématiques pour lesquelles nous pouvons vous offrir notre expertise.