Makina Blog
Calculez sur GPU avec Python – Partie 1/3
Comprendre le calcul sur GPU
Par Gaël Pegliasco
Dans cette première partie vous apprendrez les différences entre un CPU et un GPU et les clés qui vous permettront de choisir votre carte graphique pour travailler avec Python.

Source Pixabay par LauraTara
Les GPU (Graphics Processing Unit) sont les processeurs de vos cartes graphiques. Typiquement, il s’agit des cartes graphiques comme NVIDIA/AMD.
Les CPU(Central Processing Unit) sont les processeurs de vos PC et smartphones qui font fonctionner vos systèmes d’exploitation. Typiquement il s’agit des processeurs comme les Intel Core (i7/i9), AMD Ryzen ou ARM qui font fonctionner vos PC Linux/Mac/Windows ou Smartphones Android.
Comme nous l’avons vu dans le chapitre Les concepts du parallélisme les GPU se différencient des CPU par le fait qu’ils possèdent des milliers d’unités de calcul (cœurs) contre seulement quelques dizaines – au mieux – pour les CPU.
Les cœurs de vos processeurs ont la charge d’exécuter vos programmes. Si vous disposez de 10 cœurs dans un processeur vous pouvez faire fonctionner jusqu’à 10 programmes en parallèle.
Une carte graphique comme la carte NVIDIA RTX 5090 possède 21 760 cœurs contre 192 pour le meilleur CPU du moment (janvier 2025) : l’AMD Epyc 9965
Question : Pourquoi alors les GPU n’ont pas déjà remplacé les CPU dans les système d’exploitation ?
Si je dispose d’une carte graphique avec des milliers de cœurs, j’en dédie une centaine pour l’OS – ce sera déjà bien mieux que ce que propose la plupart des CPU ayant moins de 10 cœurs – et je garde les autres pour la vidéo et le machine learning ?
Ce sera à peine plus lent pour la vidéo et mons OS ira bien plus vite…
Ainsi j’économise le prix du CPU dans mon prochain PC de {del}
gamerdata-scientist !Effectivement, pourquoi ?
À la différence des CPU où chaque unité de calcul peut réaliser ses propres instructions indépendamment des autres unités, toutes les unités de calcul d’un GPU réalisent la même instruction en même temps.
Ainsi, un cœur d’un CPU pourra surfer sur internet pendant qu’un second cœur fera de la bureautique et qu’un troisième jouera de la musique. Dans un GPU tous les cœurs feront la même opération en même temps.
Un CPU est donc très bien taillé pour faire tourner un système d’exploitation (OS) car dans un OS de nombreux programmes différents s’exécutent en parallèle. C’est le 4×4 qui passe partout.
Quant au GPU il est particulièrement adapté au calcul massivement parallèle sur de grandes quantités de données.
Imaginons ce cas de figure : vous disposez d’une carte graphique possédant 10 000 cœurs et vous souhaitez incrémenter de 1 toutes les cases d’un tableau de 10 000 éléments.
- Avec votre GPU chaque cœur se verra confier le calcul sur l’un des éléments du tableau : vous allez mettre à jour toutes les cases du tableau en 1 seule instruction qui sera exécutée sur chacun des cœurs en parallèle.
- Avec un CPU vous allez devoir utiliser un cœur qui va itérer sur chaque case du tableau avec une boucle et répéter l’opération 10 000 fois, ce sera indéniablement plus long. Bien sûr, vous pourriez utiliser tous vos cœurs, mais comme vous en avez bien moins, vous n’échapperez pas à de bien plus longues boucles.
C’est l’idée globale, même si dans la pratique les choses sont un peu plus fines que cela, et que, par exemple, les CPU peuvent aller plus vite grâce aux instructions SIMD…
C’est donc pour ces raisons que les CPU font toujours tourner nos OS et que les GPU sont recommandés pour le calcul numérique et le machine learning.
Question : mais alors pourquoi les CPU n’ont-ils pas plus de cœurs ?
Ce serait quand même bien pratique, ils font pâle figure en regard des cartes graphiques.
Effectivement. En fait, pour que les cœurs d’un CPU soient indépendants les uns des autres, ceux-ci disposent d’un composant appelé ordonnanceur dont le rôle est de répartir les instructions sur ces derniers, et, malheureusement, sa complexité augmente proportionnellement au carré du nombre de cœurs.
Ceci rend donc très difficile la conception de CPU massivement parallèles.
Aujourd’hui trois constructeurs dominent le marché des cartes graphiques : NVIDIA, AMD(anciennement ATI) et Intel.
Les cartes graphiques des deux premiers sont aujourd’hui intégrées à votre ordinateur via des bus de données PCI Express. Elles sont de plus en plus volumineuses et consommatrices d’énergie.
Par exemple le presque déjà ancien modèle NVIDIA RTX 2080 Super mesure 11×26 cm et utilise le volume de 2 slots PCIE ! Une alimentation de 650 Watts est recommandée !
Les cartes AMD/NVIDIA sont particulièrement adaptées pour le jeu vidéo et le machine learning. Elles disposent de milliers de cœurs.
Les processeurs graphiques Intel sont généralement intégrés aux CPU et disposent de peu de cœurs.
Par exemple le processeur i9–14900KS intègre un processeur graphique Intel® UHD Graphics 770.
Ce dernier permet de faire tourner sans problème des applications bureautiques et de regarder des vidéos mais n’est pas aussi performant que les 2 autres concurrents pour les jeux vidéo modernes ou le calcul scientifique. Comme il est intégré avec le CPU il est nettement moins encombrant et consommateur d’énergie. C’est pour cela qu’il est bien souvent utilisé comme unique carte graphique sur les ordinateurs portables de type bureautique.
Les processeurs AMD comme le Ryzen 9 9950X disposent aussi de mini cartes graphiques intégrées.
Cela semble moins connu, mais Intel propose aussi des cartes graphiques externes/PCI Express via la gamme ARC ; cependant elles disposent seulement d’une vingtaine de cœurs.
Quand nous parlons de calcul sur GPU, nous parlons de calcul sur des processeurs graphiques dédiés et non sur ceux intégrés à vos CPU qui offrent beaucoup moins de puissance.
Pourquoi est-il utile de disposer d’un petit GPU ?
Il est aujourd’hui très fréquent de disposer de plusieurs GPU sur sa machine. Parfois même sans le savoir.
Imaginons que vous ayez installé dans votre PC votre carte graphique dernier cri disposant de milliers de cœurs, mais vous avez aussi un processeur Intel/AMD équipé d’un petit GPU.
Vous disposez donc de 2 GPU qui peuvent l’un comme l’autre gérer votre vidéo et c’est une très bonne chose – même si le second n’est pas assez puissant pour jouer à vos jeux favoris !
Dans cette configuration, généralement, votre système d’exploitation vous permet de choisir quelle carte graphique utiliser pour la vidéo voire même selon l’application exécutée.
Sous Windows vous pouvez identifier si vous disposez de plusieurs GPU dans le gestionnaire de périphériques.
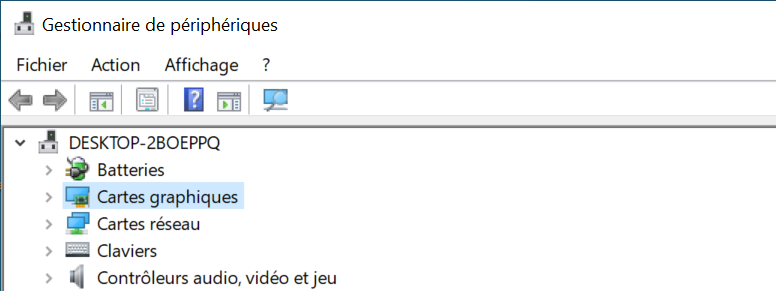
Sous Linux il existe de nombreuses manières de lister les GPUs/cartes graphiques disponibles.
La commandelscpiest peut-être le moyen le plus simple.
bash$ lspci | grep -i VGA # à saisir dans un terminal
01:00.0 VGA compatible controller: NVIDIA Corporation TU106BM [GeForce RTX 2070 Mobile] (rev a1)
08:00.0 VGA compatible controller: NVIDIA Corporation TU104 [GeForce RTX 2080 Rev. A] (rev a1)
Ce fil de discussion propose beaucoup d’autres commandes pour lister la configuration de votre carte graphique avec linux.
Parmi celles-ci, la commande inxi offre de nombreuses informations sur votre matériel :
$ inxi -Fzxd
System:
Host: <ComputerHostNameHere> Kernel: 5.3.0-53-generic x86_64 bits: 64 compiler: gcc
...
Machine:
...
Battery:
...
CPU:
Topology: 6-Core model: Intel Core i7-8700 bits: 64 type: MT MCP
arch: Kaby Lake rev: A L2 cache: 12.0 MiB
flags: lm nx pae sse sse2 sse3 sse4_1 sse4_2 ssse3 vmx bogomips: 76799
Speed: 1100 MHz min/max: 800/4600 MHz Core speeds (MHz): 1: 1100 2: 1101
3: 1100 4: 1100 5: 1100 6: 1100 7: 1100 8: 1100 9: 1100 10: 1100 11: 1100
12: 1100
Graphics:
Device-1: NVIDIA TU106BM [GeForce RTX 2070 Mobile] vendor: CLEVO/KAPOK
driver: NVIDIA v: 440.64.00 bus ID: 01:00.0
Display: x11 server: X.Org 1.19.6 driver: NVIDIA
resolution: 1680x1050~60Hz, 2560x1440~120Hz
OpenGL: renderer: GeForce RTX 2070/PCIe/SSE2 v: 4.6.0 NVIDIA 440.64.00
direct render: Yes
Audio:
...
Network:
...
Drives:
...
Message: No Optical or Floppy data was found.
Partition:
...
Sensors:
System Temperatures: cpu: 46.0 C mobo: N/A gpu: NVIDIA temp: 41 C
Fan Speeds (RPM): N/A
Info:
...
Si l’on reprend la configuration affichée par la commande lspci proposant 2 cartes NVIDIA RTX 2070 et 2080 il s’agit d’une machine ou la première carte est intégrée au PC portable ; la seconde est une carte connectée via un boîtier externe sur port Thunderbolt 3. Cela ne se devine pas avec la commande.
En fait ce listing est incomplet.
Il en manque même une troisième, celle du processeur Intel i7 – 8700 qui équipe le PC et qui dispose d’une puce Intel® UHD Graphics 630. Mais elle est inutilisable en raison d’une connectique un peu particulière du portable utilisé.
Vous allez penser ironiquement « Oh la malheureuse personne ! » : ce n’est pas bien grave, les 2 premières suffisent largement et le processeur UHD Graphics 630 ne nous intéresse pas.
Et bien, si, cela peut être vraiment pénalisant de ne pas avoir cet autre processeur de disponible, aussi petit soit-il.
Nous allons expliquer pourquoi dans un instant.
Revenons à des sorties plus fréquentes. En général vous voyez plutôt quelque chose comme ceci avec la commande lspci:
$ lspci | grep -i VGA
00:02.0 VGA compatible controller: Intel/AMD Corporation Device XXX
01:00.0 3D controller: NVIDIA/AMD Corporation YYY
Dans cette configuration vous disposez d’une carte vidéo 3D hautes performances et d’une carte plus modeste intégrée au processeur.
Quand vous calculez avec le GPU de votre PC portable/desktop, il est très utile de disposer des deux.
Comme votre système d’exploitation vous permet de choisir la carte graphique à utiliser pour l’affichage vidéo vous pouvez indifféremment basculer sur l’une ou l’autre.
Et cela est vraiment très pratique :
- Sur batterie vous utilisez la carte la moins consommatrice, celle du processeur, et vous pouvez terminer de saisir votre rapport dans le train avant de vider la batterie de votre portable.
- Sur courant, vous basculez sur la carte hautes performances pour vos applications les plus exigeantes.
Linux possède des commandes pour basculer l’affichage graphique d’un GPU à l’autre : Une recherche Internet vous retournera de nombreuses réponses comme ce tutorial Howto switch Intel and NVIDIA
Pour les cartes NVIDIA la commande est prime-select
Lister les cartes disponibles :
$ sudo prime-select query
NVIDIA
intel
Sélectionner une carte:
$ sudo prime-select intel
Mais pourquoi sélectionner la carte la moins performante ! Nous voulons utiliser toute la puissance de ce PC !
Justement : nous allons lancer des calculs sur GPU. Nous allons les exécuter sur la carte la plus puissante, donc NVIDIA dans cet exemple.
Si vous lancez les calculs sur le GPU utilisé pour l’affichage graphique, ce qui est tout à fait possible, vous risquez de ralentir considérablement le rafraichissement de l’écran quand la carte tournera à plein régime pour vos calculs.
C’est ce qui se passe sur mon PC quand je fais du machine learning et que je n’ai pas connecté le boîtier externe : je ne peux même plus surfer sur internet pendant que le GPU calcule car le processeur graphique n’a pas le temps de rafraîchir l’écran, il calcule des descentes de gradients à tours de bras…
Et franchement c’est pénible. Ne vous plaignez plus d’avoir un chipset graphique moins performant que vous n’utilisiez pas. Aujourd’hui il va vous permettre de poursuivre la lecture de ce tutoriel pendant vos calculs !
C’est même une condition d’achat du CPU si vous souhaitez calculer sur votre machine personnelle : le CPU doit disposer d’un petit GPU interne pour décharger le GPU qui calculera.
Un mot sur les boîtiers externes – eGPU
En termes de calcul sur GPU, il devient de plus en plus fréquent d’utiliser des cartes graphiques placées dans des boîtiers externes (eGPU – external GPU), ce qui offre de nombreux avantages comme de pouvoir changer la carte plus facilement ou ne pas la brancher si vous n’en avez pas l’usage, ou de doper un laptop qui ne serait pas évolutif, ou encore de la prêter à votre collègue, car il faut le dire, vous n’utilisez pas tout le temps votre GPU à 100% de ses capacités.
Dans ce cas vous devez utiliser une connexion entre le boitier et le PC qui puisse offrir un débit suffisant pour les échanges de données avec le CPU.
À défaut, les performances ne seront pas au rendez-vous.
Aujourd’hui, les ports Thunderbolt 3 et 4 offrant un débit de 40Gbit/sec sont adaptés à ce type de transfert.
Les versions précédentes de la norme, comme Thunderbolt 2 avec 20Gbit/sec de débit ne sont pas suffisantes. Si vous utilisez ce type de configuration, tout le temps de calcul gagné en utilisant la carte graphique externe sera reperdu par les échanges entre le CPU et le GPU en raison de leur trop grande lenteur.
Il convient donc d’être vigilant sur le choix de la connectique.
Le câble doit aussi être adapté au type de la connexion.
Pour creuser le sujet, voici deux articles qui vous donneront quelques pistes pour transformer votre laptop en une machine de guerre utilisant un GPU externe : * 9 Things You Need to Know About External GPUs * How to use an external GPU on a Laptop?
Le site eGPU.io propose un intéressant listing pour vous aider à choisir votre GPU externe ou construire le vôtre.
Un mot sur la mémoire de votre carte graphique
Vous avez investi. Vous avez un ordinateur portable avec un maximum de RAM, disons 64Go, et une carte graphique aux performances fabuleuses équipée de seulement 4Go de RAM.
Ce n’est pas grave pensez-vous, 4Go c’est suffisant pour l’écran et pour les data il y a 64Go du CPU, le GPU n’aura qu’à y piocher ce qu’il veut, de toute façon j’utilise rarement tout.
Ce n’est pas une solution.
Les calculs sur GPU se font dans la mémoire de la carte graphique. Et les échanges avec la mémoire du PC sont un véritable goulot d’étranglement. Il est donc important de disposer d’une carte graphique possédant beaucoup de mémoire si vous envisagez de lui confier des données volumineuses à traiter.
Sinon, vous découvrirez rapidement les drames du Memory Overflow.
Calculer sur GPU – GPGPU
General Purpose computing on GPU est le terme désignant le calcul sur GPU pour des problématiques habituellement confiées à des CPU.
Le calcul sur GPU a commencé à devenir populaire vers 2001 lorsque les processeurs graphiques ont intégré des unités de calcul en virgule flottante. Puis des opérations d’algèbre linéraire comme le calcul vectoriel et matriciel.
En 2005, la décomposition LU fut un des premiers programmes ayant réussi à fonctionner plus rapidement sur GPU que sur CPU.
Mais la programmation pour GPU était alors très différente de la programmation pour CPU, plus laborieuse et compliquée, bas niveau. Les GPU ont des instructions moins riches que les CPU et des concepts bien différents.
L’arrivée de librairies comme CUDA et OpenCL a permis d’écrire des programmes pour GPU en s’affranchissant de nombreux concepts bas niveau spécifiques à chaque modèle de carte graphique. Ceci a boosté le développement du calcul sur GPU qui est alors devenu beaucoup plus accessible.
Enfin, l’arrivée du BigData et du Machine Learning manipulant des données très volumineuses (généralement de grands vecteurs) ont trouvé dans les opérations matricielles offertes par les GPU modernes le moyen de mettre en œuvre tout leur potentiel. Offrant ainsi à ces disciplines leurs lettres de noblesse.
Les librairies Python pour calculer sur GPU
Python possède plusieurs librairies permettant d’exécuter des calculs sur GPU:
- PyOpenCL, comme son nom l’indique, implémente l’API OpenCL en Python. Cette API offre l’avantage de supporter tout type de matériel, CPU, GPU, FPGA, DSP, …
C’est une des rares librairies qui permet d’écrire un code compatible avec les 2 modèles de cartes AMD et NVIDIA (et bien d’autres). - PyCuda est un projet proche de PyOpenCL qui permet d’utiliser à l’API Cuda des cartes NVIDIA.
Mais cette librairie ne fonctionne qu’avec les cartes NVIDIA. - pygpu implémente des tableaux à N dimensions pour GPU.
La librairie se veut simple, cross architecture OpenCL/Cuda et riche en fonctionnalités – mais n’est plus maintenue depuis quelques années déjà.
Elle reste intéressante pour comprendre la difficulté de mise en œuvre de la discipline. - Scikit-cuda fournit une interface Python pour de nombreuses fonctions des API CUDA, CUBLAS, CUFFT, et CUSOLVER de NVIDIA et réimplémente ainsi tout une partie de la librairie Scipy sur GPU.
- Numba est une librairie de compilation Just In Time/A la volée permettant notamment la compilation pour CPU et GPU.
Elle supportait anciennement les architectures NVIDIA – CUDA et AMD – ROCm (avec certaines restrictions). Cependant ROCm n’est plus géré aujourd’hui.
Elle reste un choix très intéressant pour certains codes de calculs mais demande un refactoring non trivial. - Cupy est une librairie d’algèbre linéaire optimisée avec NVIDIA CUDA. Elle propose aussi un support expérimental pour AMD Rocm (4 & 5).
Elle utilise aussi les autres librairies NVIDIA comme cuBLAS, cuDNN, cuRand, cuSolver, cuSPARSE, cuFFT et NCCL ce qui permet d’utiliser tout le potentiel de votre GPU.
Son API est calquée sur celle de Numpy ; elle peut très souvent remplacer sans effort cette dernière. - Le projet RAPIDS AI soutenu par NVIDIA propose de multiples librairies de datascience ré-écrites pour fonctionner sur GPU NVIDIA via CUDA.
Le projet permet réimplémente des clones de plusieurs librairies Python phares pour leur permettre de fonctionner sur GPU:- cuDF propose des DataFrames à la pandas fonctionnant sur GPU
- cuML ré-implémente les algorithmes classiques de machine learning (arbres de décision, svm…) avec une API calquée sur scikit-learn mais sur GPU
- cuGraph propose des algorithmes de gestion de graphes avec une API inspirée de NetworkX
- D’autres librairies sont aussi disponibles
Enfin, le projet propose une page pour vous aider à configurer votre environnement virtuel conda/pip ou docker: https://docs.rapids.ai/install/#selector
- Depuis décembre 2023 la librairie de calcul distribué dask permet d’utiliser des GPU NVIDIA via Cupy et cuDF au lieu de tableaux numpy/pandas
- Depuis septembre 2024 la librairie polars offre un support expérimental sur GPU
- Enfin, xarray dispose aussi d’un support expérimental sur GPU
Pour les réseaux de neurones, les principales librairies : PyTorch, Tensorflow, Mxnet sont compatibles avec les GPU AMD/NVIDIA depuis leur création. Toutefois pour calculer sur plusieurs GPU sur plusieurs machines, la librairie Horovod est une solution qui peut grandement vous simplifier la tâche.
Quel GPU utiliser avec Python ?
Si vous faîtes du machine learning, peu importe, pour les réseaux de neurones, les 2 librairies phares du marché Tensorflow et PyTorch fonctionnent indifféremment sur GPU NVIDIA/AMD.
Si vous utilisez pandas, NumPy, polars, scikit-learn, NetworkX, Dask ou xarray, pas d’hésitation, leurs équivalents respectifs pour GPU, à savoir cuDF, CuPy, polars(GPU), cuML, cuGraph et Xarray(GPU) ne fonctionnent que sur des cartes graphiques de la marque NVIDIA.
Si vous souhaitez compiler du code python sur GPU avec Numba, là encore NVIDIA reste le choix favoris, l’architecture ROCm n’est plus testée/gérée par Numba depuis sa version 0.6
NVIDIA semble avoir bien compris que la data science fait vendre des GPU et que Python est le langage de prédilection de la data science. Aussi NVIDIA se donne beaucoup de moyens pour que ses cartes graphiques soient parfaitement gérées par Python. NVIDIA est d’ailleurs à l’origine du projet Rapids AI.
AMD ne semble pas concerné par la question. Toutefois cela ne l’empêche pas de percer dans le milieu avec ses cartes accélérateurs AMD Instinct MI puisque les 2 plus performants supercalculateurs au monde en sont équipés en novembre 2024
Mais si vous ne faîtes pas de machine learning, il faut actuellement oublier AMD avec Python et utiliser des cartes NVIDIA.
Toutefois CuPy propose un support AMD-ROCm expérimental ce qui devrait permettre aussi à Dask.array et xarray de fonctionner avec les cartes de cette marque.
Il existe une version numba-hip dédiée à l’architecture ROCm pour les cartes AMD MI uniquement.
Installation des librairies liées à votre matériel
Pour calculer sur GPU vous devez disposer des librairies/drivers correspondant à votre matériel avant d’installer les librairies Python présentées précédemment.
Nous nous focaliserons donc sur NVIDIA puisqu’AMD n’est pour le moment pas un choix à retenir pour Python.
NVIDIA
Concernant les drivers graphiques propriétaires NVIDIA, ceux fournis par votre distribution Linux font normalement l’affaire. Sinon, quel que soit votre système, vous pouvez suivre les instructions de la page de téléchargement des pilotes NVIDIA.
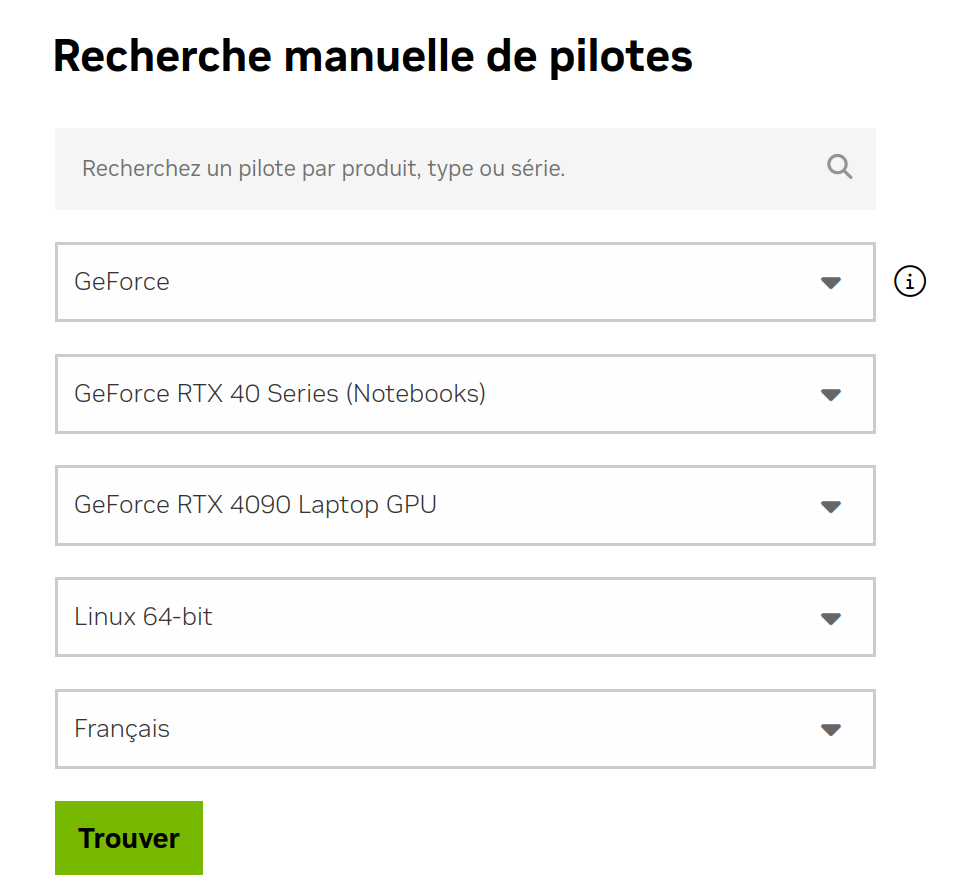
Puis, il convient d’installer la librairie CUDA.
NVIDIA propose un formulaire de configuration pour sélectionner la version de la librairie à installer.
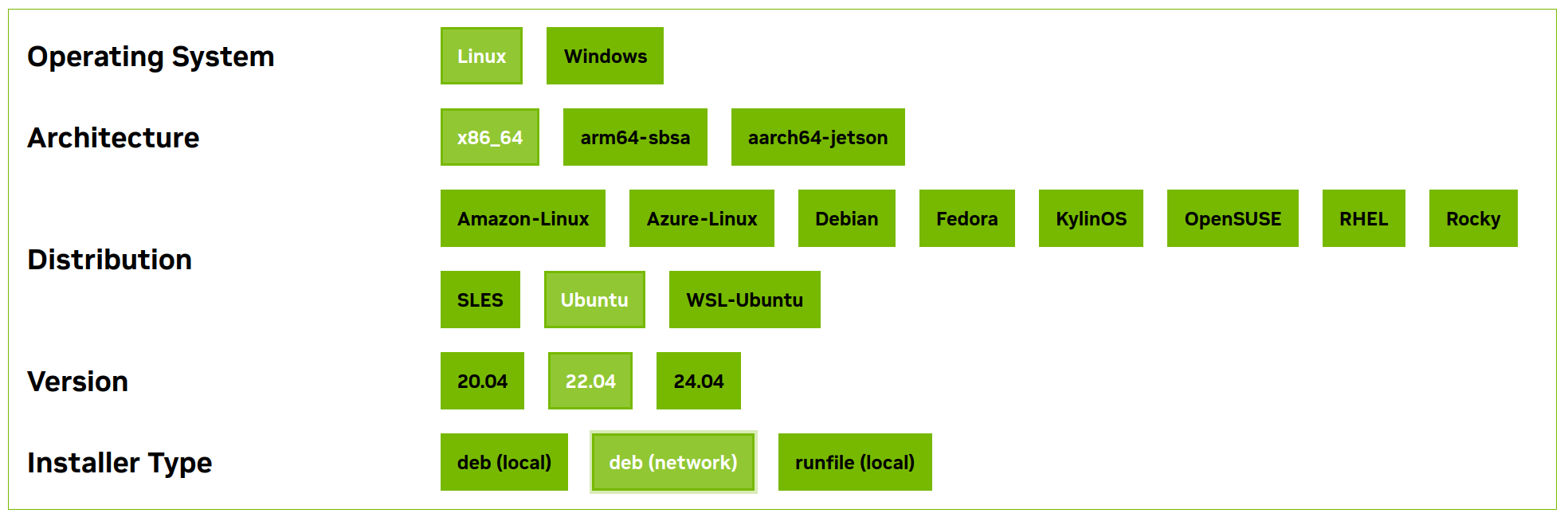
Ensuite, les commandes devant être exécutées sont présentées.
Exemple pour CUDA 12.6 sur Linux Ubuntu 22.04 :
bash$ wget https://developer.download.NVIDIA.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
bash$ sudo dpkg -i cuda-keyring_1.1-1_all.deb
bash$ sudo apt-get update
bash$ sudo apt-get -y install cuda-toolkit-12-6
N’oubliez pas les drivers CUDA :
bash$ sudo apt-get -y install cuda-drivers
Ensuite, les commandes devant être exécutées sont présentée.
Exemple pour CUDA 12.6 sur Linux Ubuntu 22.04 :
bash$ wget https://developer.download.NVIDIA.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
bash$ sudo dpkg -i cuda-keyring_1.1-1_all.deb
bash$ sudo apt-get update
bash$ sudo apt-get -y install cuda-toolkit-12-6
N’oubliez pas les drivers CUDA :
bash$ sudo apt-get -y install cuda-drivers
Vous pouvez vérifier la bonne configuration de votre installation avec les commandes suivantes :
$ nvidia-smi
Wed Jan 15 00:04:22 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 555.42.06 Driver Version: 555.42.06 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2070 Off | 00000000:01:00.0 On | N/A |
| N/A 53C P0 32W / 115W | 1734MiB / 8192MiB | 2% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
Le toolkit CUDA fournit aussi quelques programmes d’exemples comme deviceQuery si vous installez la suite de démonstration :
bash$ sudo apt install cuda-demo-suite-12-6
$ locate deviceQuery
/usr/local/cuda-12.6/extras/demo_suite/deviceQuery
/usr/local/cuda-12.6/samples/1_Utilities/deviceQuery
/usr/local/cuda-12.6/samples/1_Utilities/deviceQueryDrv
/usr/local/cuda-12.6/samples/1_Utilities/deviceQuery/Makefile
/usr/local/cuda-12.6/samples/1_Utilities/deviceQuery/NsightEclipse.xml
/usr/local/cuda-12.6/samples/1_Utilities/deviceQuery/deviceQuery.cpp
/usr/local/cuda-12.6/samples/1_Utilities/deviceQuery/readme.txt
/usr/local/cuda-12.6/samples/1_Utilities/deviceQueryDrv/Makefile
/usr/local/cuda-12.6/samples/1_Utilities/deviceQueryDrv/NsightEclipse.xml
/usr/local/cuda-12.6/samples/1_Utilities/deviceQueryDrv/deviceQueryDrv.cpp
/usr/local/cuda-12.6/samples/1_Utilities/deviceQueryDrv/readme.txt
$ /usr/local/cuda/extras/demo_suite/deviceQuery
Device 0: "GeForce RTX 2080"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 7952 MBytes (8338604032 bytes)
(46) Multiprocessors, ( 64) CUDA Cores/MP: 2944 CUDA Cores
GPU Max Clock rate: 1815 MHz (1.81 GHz)
Memory Clock rate: 7000 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
...
Device PCI Domain ID / Bus ID / location ID: 0 / 8 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 1: "GeForce RTX 2070"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 7930 MBytes (8315076608 bytes)
(36) Multiprocessors, ( 64) CUDA Cores/MP: 2304 CUDA Cores
GPU Max Clock rate: 1440 MHz (1.44 GHz)
Memory Clock rate: 7001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
...
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from GeForce RTX 2080 (GPU0) -> GeForce RTX 2070 (GPU1) : No
> Peer access from GeForce RTX 2070 (GPU1) -> GeForce RTX 2080 (GPU0) : No
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 2, Device0 = GeForce RTX 2080, Device1 = GeForce RTX 2070
Result = PASS
Si vous souhaitez utiliser d’anciennes versions de CUDA reportez-vous à ce formulaire d’archives NVIDIA : https://developer.NVIDIA.com/cuda-toolkit-archive
Enfin, nous pouvons vérifier que le compilateur NVIDIA nvcc est disponible.
Sous Linux
$ wich nvcc
Sous Windows
$ where nvcc
Si la commande précédente n’affiche rien, il convient de l’ajouter au PATH système.
Le compilateur se trouve normalement dans le dossier /usr/local/cuda-<version>/bin qui doit pouvoir être accessible via le lien symbolique /usr/local/cuda/bin
$ export PATH=/usr/local/cuda/bin:$PATH # sous Linux/Unix
C:> set PATH=%PATH%;"C:\Dossier\Contenant\Le\Compilateur" # sous Windows
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:07:16_PDT_2019
Cuda compilation tools, release 10.1, V10.1.243
L’ajout du compilateur au PATH système sera nécessaire notamment pour la compilation de la librairie PyCuda.
Vous voilà prêt à travailler sur GPU et prendre en main votre carte graphique avec Python !
En savoir plus
Formations associées
Formations IA / Data Science
Formation Python Calcul Scientifique
A distance (FOAD) Du 15 au 19 juin 2026
Voir la Formation Python Calcul ScientifiqueFormations IA / Data Science
Formation Python scientifique
A distance (FOAD) Du 15 au 19 juin 2026
Voir la Formation Python scientifiqueFormations IA / Data Science
Formation Passer de Matlab à Python
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Passer de Matlab à PythonActualités en lien
Calculez sur GPU avec Python – Partie 3/3
Data Science
20/02/2025

Calculez sur GPU avec Python – Partie 2/3
Data Science
11/02/2025

Nouvelle formation Python Calcul Scientifique
Formation
22/05/2024
