Makina Blog
Extraction d'objets pour la cartographie par deep-learning : création d'une vérité terrain
Cette série d'articles parle de cartographie par deep-learning à partir d'images aériennes ou satellitaires. Dans ce 1er article, l'étape préliminaire à toute utilisation d'un modèle d'apprentissage supervisé est abordée: la création du jeu de données d'apprentissage. Notre outil geolabel-maker est mis à votre disposition pour vous aider.
L'arrivée des algorithmes d'intelligence artificielle, couplée à la mise à disposition en open-source d'images satellites ou aériennes, sonne comme une révolution dans le domaine de la cartographie. En effet, il est désormais relativement rapide et peu coûteux de constituer des bases de données géographiques à partir de données raster.
Pour cela, l'opération à mettre en œuvre est une opération de segmentation sémantique. Ce type de traitement consiste à identifier et détourer les éléments d'une image en associant chaque pixel à une catégorie donnée en cartographie, cela peut par exemple être les catégories suivantes : bâtiments, routes, végétation, etc. Les objets ou zones d'intérêt pourront ensuite être facilement reconstruits par vectorisation du résultat. L'apprentissage supervisé, et plus particulièrement les modèles de deep-learning, nous permettent de réaliser efficacement et de manière automatique des opérations de segmentation sémantique. Ils se basent sur des réseaux de neurones convolutifs qui vont rechercher dans les images les éléments caractéristiques des catégories attendues.
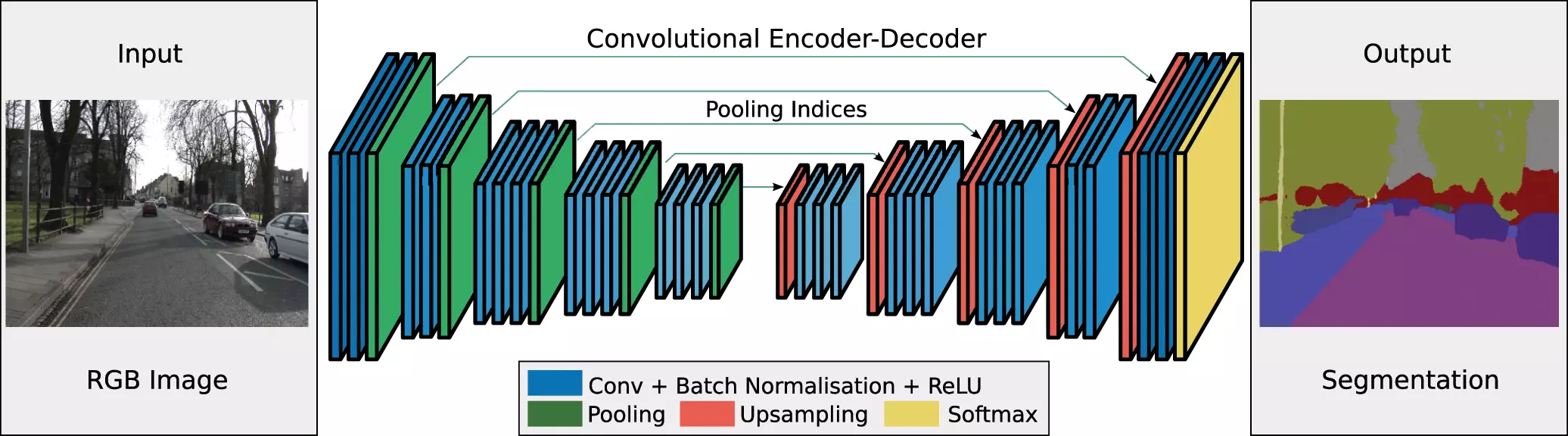
SegNet : architecture représentant les étapes de convolution et déconvolution. source: V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deepconvolutional encoder-decoder architecture for image segmentation, ”arXiv preprint arXiv:1511.00561, 2015.
Comme tous les modèles d'apprentissage supervisé, ces algorithmes de reconnaissance d'image nécessitent de nombreux exemples labellisés (ou annotés) en entrée du résultat attendu en sortie. Ainsi, le modèle s'ajuste et devient de plus en plus précis par entraînement itératif sur un nombre important d'images et labels associés. Une partie du jeu de données servira à la validation finale du modèle, nous nous en servirons alors pour comparer la prédiction du modèle au résultat attendu. Cet ensemble de couples (image, label) est appelé vérité terrain.
Plus ce jeu de données d'apprentissage est de qualité et plus la précision du modèle sera optimale. Un jeu de données qui n'est pas assez varié donnera un modèle trop spécialisé et ne sera pas performant sur de nouveaux jeux de données. De même, la qualité de la vérité terrain influencera la précision du modèle : une mauvaise labellisation du jeu d’entraînement engendrera des erreurs de détection par le modèle final.
L'article est consacré à cette étape fondamentale dans la mise en œuvre de tous les modèles supervisés de machine-learning et deep-learning pour l'extraction d'objets : la construction du jeu d’entraînement et de validation, contenant les images et leurs labels associés. Comment construire la vérité terrain nécessaire à la construction d'un modèle de détection d'objets à partir d'images aériennes ou satellitaires ?
Cet article s'appuie sur mon travail de stage portant sur l'analyse des toitures en ville. Nous nous focaliserons donc sur ce cas d'application de l'extraction de bâtiments à partir d'images aériennes ou satellitaires.
Comment se structure la vérité terrain attendue par les modèles de deep-learning d'analyse d'images ?
L'objectif des modèles d'extraction d'objets est de détecter un ou plusieurs des éléments présents dans les images. Le modèle final doit à partir d'une image donnée en entrée prédire la présence ou non des structures cibles. Pour cela, il faut en amont entraîner le modèle avec un jeu d’entraînement contenant l'entrée attendue par le modèle, c'est à dire une image, mais aussi la réponse attendue pour la prédiction, c'est à dire une image label, où les labels indiquent la présence des structures cibles.
IMAGE
Une photographie aérienne ou satellite.

LABEL
Une image mettant en évidence le ou les éléments recherchés. Dans le cadre de cette étude, une image où les bâtiments sont d'une couleur différente du reste de l'image, ce qui constitue 2 classes : "bâtiment" et "non bâtiment".

L'ensemble des couples (image, label) constituant notre vérité terrain, va permettre d’entraîner le modèle. L'image correspond à ce que le modèle prend en entrée et le label correspond à la réponse attendue. Il est découpé en deux : * le jeux d’entraînement sur lequel le modèle s'ajuste; * et le jeu de validation sur lequel le modèle est évalué. Généralement, la vérité terrain est utilisée selon ces ratios : 80 % des données servent à l’entraînement et 20% à la validation.
Jeux de données existants
Construire une vérité terrain peut être selon les cas une étape extrêmement chronophage et coûteuse. Heureusement, de plus en plus de jeux de données sont partagés en open-source par les communautés qui travaillent sur ces problématiques.
Il peut aussi être intéressant de constituer une vérité terrain avec plusieurs sources de données. Cela permet d'obtenir des images d'environnements différents, d'architectures différentes, ce qui permet de ne pas rendre le modèle trop spécialisé sur un type de paysage.
Pour toutes ces raisons, nous vous présentons ici quelques-uns de ces jeux de données existants.
Inria
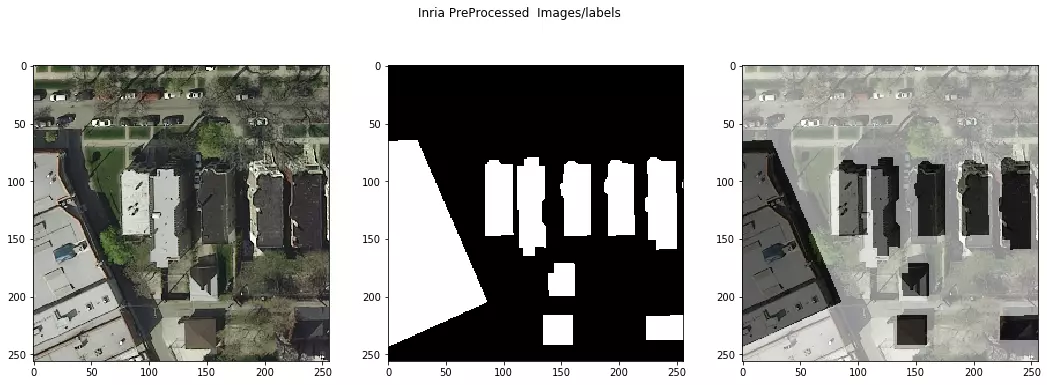
Le site du projet Aerial Image labeling contient un jeu de données de 180 images aériennes et leurs labels associés (décrivant deux classes : "building", "not building"). Différentes villes américaines - Austin, Chicago, Kitsap County, Western Tyrol et Vienna - sont disponibles dans ce jeu de données, ce qui correspond à 810 km² de couverture, sur des régions plus ou moins urbanisées.

Couple (image, label) pour une vue aérienne de Vienna
Spacenet Buildings
Spacenet est un organisme qui délivre des données géospatiales. Ils mettent à disposition des jeux de données au travers de plusieurs challenges. Ainsi pour un challenge visant l'extraction de bâtiments, des jeux de données composées de fichiers rasters et de fichiers vecteurs pour la vérité terrain sont mis à disposition. Le challenge SN6: Multi-Sensor All-Weather Mapping propose par exemple des données issues d'imagerie radar par synthèse d'ouverture (SAR) et d'imagerie optique (EO) associées à des fichiers geojson, concernant la ville de Rotterdam.
Exemple d'image Spacenet de Rotterdam
Open Cities AI Challenge
Ce challenge propose un jeu de données composées d'images aériennes prises par drone de 10 différentes villes et régions d'Afrique. Les données consistent en des couples (image, label), les images étant au format "Cloud Optimized GeoTiffs" (COG) et les labels au format Geojson. La plupart des labels sont issus de OpenStreetMap.

Aperçu des données images/labels pour la region de Kampala
Comment construire automatiquement son propre jeu de données ?
Il est parfois nécessaire de construire son propre jeu de données, que ce soit pour enrichir les jeux de données existants ou pour cibler une zone ou des éléments non représentés dans les différentes sources disponibles. L'enjeu est donc de créer automatiquement des couples (image, label) adaptés à ses besoins, à sa zone géographique et à sa problématique.
LABEL-MAKER
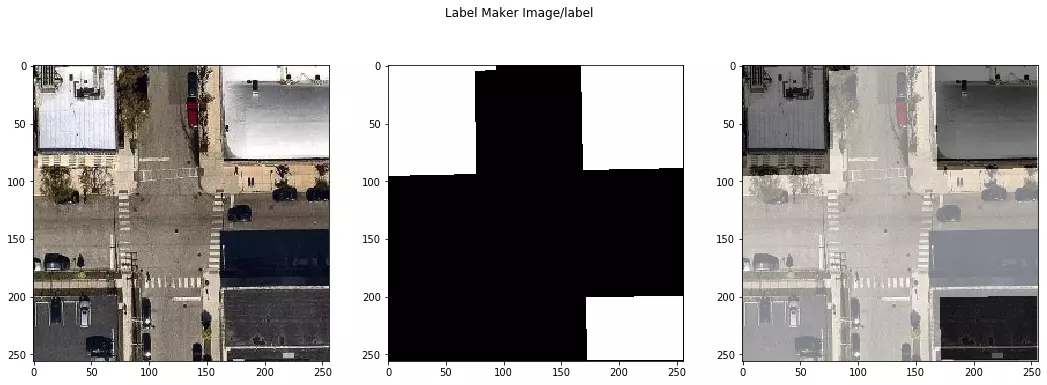
La bibliothèque Label Maker permet la création de couples (image, label). Elle combine les données OpenStreetMap (OSM) aux tuiles raster Mapbox Satellite (issues d'une combinaison de plusieurs sources d'images commerciales, de la NASA et de l'USGS). Les données OSM permettent d'obtenir l'information sur les éléments présents dans la zone d'intérêt. Dans le cadre de ce projet, il s'agit de la présence ou non de bâtiments. `Label-maker` permet d'associer ces données à des images satellites de la zone demandée sous la forme d'un ensemble de couples (label, image), prêt à être utilisé pour l’entraînement d'un modèle supervisé de reconnaissance d'images en cartographie. L'avantage de ce type d'outil est de facilement créer une vérité terrain avec les zones et les éléments cibles de son choix.
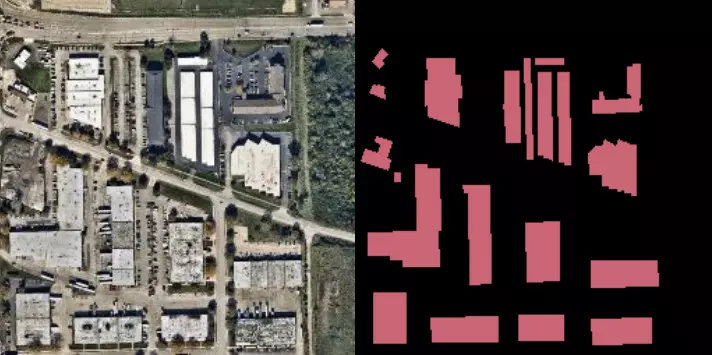
Exemple d'un couple Image/label généré par label-maker
Les instructions se font en ligne de commande :
``` $ label-maker download # téléchargement fichier .mbtiles correspondant aux tuiles d'OSM ```
``` $ label-maker labels # obtenir fichier `geojson`, fichier `labels.npz` et dossier avec les images "labels". ```
``` $ label-maker images # téléchargement images satellites correspondant à notre requête. ```
``` $ label-maker package # empaquetage dans un même fichier `data.npz` des labels et des images obtenues ```
GEOLABEL-MAKER
Afin de ne pas être contraints par les sources de données, Makina Corpus a développé la bibliothèque geolabel-maker. Elle est disponible en open-source sur Github et permet de générer les couples (image, label) à partir de données vecteurs et rasters hétéroclites. En effet, cette bibliothèque permet d'utiliser des rasters associés à un ou plusieurs fichiers vecteur de votre choix. La qualité des labels pouvant varier d'une source à l'autre, la possibilité de ne pas être limité par une source donnée permet d'optimiser la qualité de la vérité terrain. À titre d'exemple, les données de l'emprise des bâtiments sont des données généralement précises et le sont d'autant plus que leur actualisation est récente. Associées à des orthophotographies datant de la même époque, il est possible de construire des couples (image, label) avec une précision de meilleure qualité. Geolabel-maker permet de construire une vérité terrain à partir de ce type de données à une résolution spatiale choisie par l'utilisateur, disponible sous forme de tuiles raster.

Enfin, geolabel-maker a été enrichi de fonctionnalités permettant la génération d'un fichier d'annotations au format COCO pour le jeu de données créé. Ce fichier est nécessaire pour l’entraînement et l'utilisation de certains modèles de deep-learning.
Utilisation de `Geolabel-maker`
>Ce notebook explique pas à pas la procédure à suivre pour la préparation de données avec geolabel-maker. Un exemple est fourni à partir de données ouvertes disponibles sur la Métropole de Lyon : Use_geolabel_maker
A partir d'images et de fichiers vecteur, nous allons créer un ensemble de couples (image, label) ainsi que le fichier json d'annotations évoqué précédemment.
L'enjeu de ce pré-traitement des données est de créer un jeu de données :
- soit sous la forme de vignettes images et labels ;
- soit sous la forme de vignettes images et d'un fichier d'annotations décrivant les objets présentés dans les vignettes images.
La procédure proposée à travers la bibliothèque geolabel-maker comprend 4 étapes :
- la labellisation,
- le regroupement des images et labels,
- la création de tuiles,
- et enfin si besoin la création du fichier d'annotations.
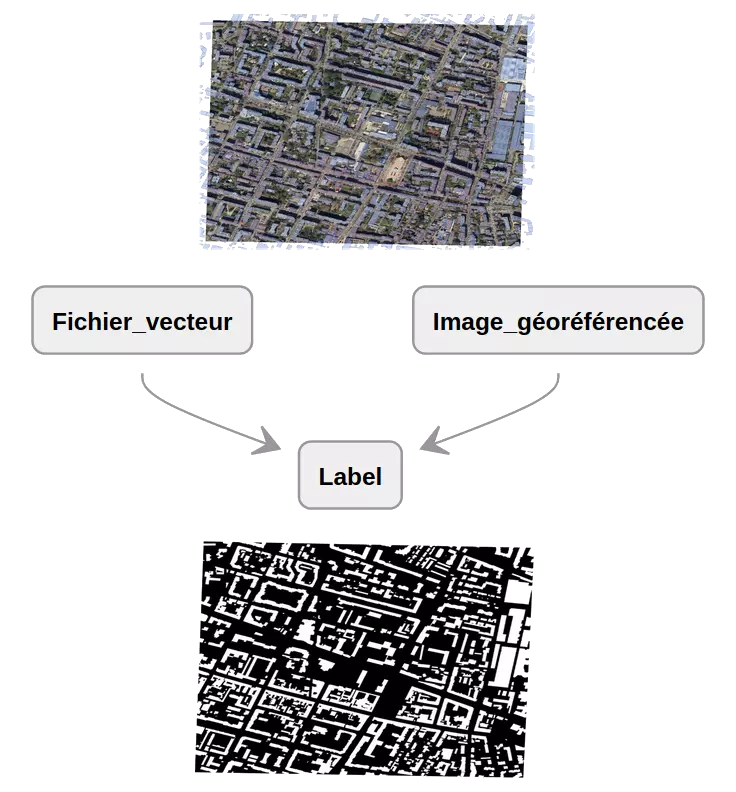
1. Labellisation
L'étape de labellisation consiste à créer à partir d'un ou plusieurs fichiers vecteur contenant les informations sur la présence de la structure cible un label correspondant à l'emprise d'une image géo-référencée. Dans le cadre de cet exemple d'extraction de bâtiments, un fichier geojson de l'emprise des bâtiments de la ville de Lyon va permettre de créer un label correspondant à une orthophotographie de la ville.
Avec la fonction `make_labels()` de `geoLabel-maker`, l'emprise de l'image géo-référencée est extraite du fichier vecteur et permet la création du label correspondant. Dans le cadre de notre étude, le label obtenu est en noir et blanc : les bâtiments sont en blanc, et le reste du paysage (background) est noir. `Geolabel-maker` permet cependant d'élargir la labellisation à plusieurs classes, ce qui permet d'obtenir des labels avec les différentes classes représentées par les couleurs de son choix.
2. Regroupement des images et labels
Suite à la labellisation, les différentesotre images et labels créés sont fusionnés en un unique couple (image, label) au format VRT avec la fonction `make_rasters()`. La création de ces fichiers VRT permet par la suite de réaliser le découpage en tuiles.
3. Création de tuiles
En effet, afin de préparer les couples (image, label) à être utilisés dans le modèle de deep-learning, il est nécessaire de découper ces derniers en vignettes d'une dimension maximale de quelques centaines de pixels qui correspondra à un format d'entrée attendu pour l’entraînement du modèle. La création de tuiles permet de découper ces images/labels en petites vignettes, de 256x256 pixels et à différents niveaux de zoom (résolution spatiale).
Avec la fonction `make_tiles()` de geolabel_maker, les images et leurs labels associés obtenus à l'issue de la labellisation sont donc découpés en vignettes.

4. Création du fichier d'annotations
Afin de finaliser la construction de la vérité terrain et de permettre son utilisation pour l’entraînement de certains modèles, une étape permettant la création d'un fichier au format json qui regroupe toutes les informations du jeu de données a été ajoutée. Ce fichier correspond au format COCO (cocodataset). La fonction `make_annotations` de `geolabel_maker` permet la création de ce fichier.
Ce fichier d'annotations se compose de quatre parties : infos, catégories, images et annotations.
``` { "info": informations générales sur le jeu données, "categories": catégories ciblées, "images": informations sur les images, "annotations": [annotation] } ```
Les sections info, categories et images sont simples à générer :
- la section info regroupe les informations sur le jeu de données : sa date de création, le niveau de zoom retenu et une description ;
- la section catégories regroupe pour chaque catégorie ciblée les informations suivantes : l'identifiant de la catégorie, le nom de la catégorie, et le nom de la super-catégorie à laquelle elle appartient ;
- la section images regroupe les informations pour chaque image du jeu de données : son identifiant unique, ses dimensions ainsi que le chemin d'accès vers l'image. La principale difficulté est de créer la section *annotations* : celle-ci contient les informations sur la présence d'objet dans l'image.
Pour chaque objet de l'image, une annotation est créée. Ainsi, si une image contient 5 bâtiments dans notre jeu de données, 5 annotations sont créées.
``` Annotations for image_id 1808 {'segmentation': [[37.0, 58.5, 75.5, 11.0, 62.0, -0.5, 13.0, -0.5, -0.5, 16.0, -0.5, 29.0, 34.0, 57.5, 37.0, 58.5]], 'iscrowd': 0, 'image_id': 1808, 'category_id': 1, 'id': 1944, 'bbox': [-0.5, -0.5, 76.0, 59.0], 'area': 2853.0} {'segmentation': [[212.0, 9.5, 219.5, 1.0, 219.0, -0.5, 201.5, 0.0, 212.0, 9.5]], 'iscrowd': 0, 'image_id': 1808, 'category_id': 1, 'id': 1945, 'bbox': [201.5, -0.5, 18.0, 10.0], 'area': 93.5} {'segmentation': [[255.0, 44.5, 255.0, 27.5, 247.5, 38.0, 255.0, 44.5]], 'iscrowd': 0, 'image_id': 1808, 'category_id': 1, 'id': 1946, 'bbox': [247.5, 27.5, 7.5, 17.0], 'area': 63.75} {'segmentation': [[255.0, 235.5, 255.0, 113.5, 196.5, 188.0, 255.0, 235.5]], 'iscrowd': 0, 'image_id': 1808, 'category_id': 1, 'id': 1947, 'bbox': [196.5, 113.5, 58.5, 122.0], 'area': 3568.5} {'segmentation': [[81.0, 255.5, 71.0, 246.5, 63.5, 255.0, 81.0, 255.5]], 'iscrowd': 0, 'image_id': 1808, 'category_id': 1, 'id': 1948, 'bbox': [63.5, 246.5, 17.5, 9.0], 'area': 76.25} ```
La clé `segmentation` correspond aux coordonnées du polygone décrivant l'emplacement de l'objet dans l'image. `category_id` est l'identifiant de la classe associée à la segmentation. Dans notre exemple, la catégorie 1 correspond à l'unique classe "buildings". La clé `bbox` correspond aux coordonnées du rectangle qui englobe l'objet. `area` correspond à la superficie de l'objet dans l'image. La clé `is_crowd` indique qu'il s'agit d'un objet unique si il est égal à zéro et d'un groupe d'objets s'il est égal à 1. Dans notre exemple, chaque bâtiment est un objet unique. Enfin, chaque annotation a un `id` unique.
> Il est possible de contrôler ce fichier d'annotations avec le deuxième notebook qui est également mis à votre disposition : Check_coco_annotations.
En résumé, `geolabel-maker` permet la construction d'une vérité terrain mono ou multi-labels à partir de sources hétéroclites, à la résolution spatiale choisie par l'utilisateur. Son utilisation est donc généralisable à d'autres problématiques que celle présentées dans cet article.
Qualité de la combinaison (image, label)
Les observations des jeux de données labellisés mis à disposition par l'Inria ou d'autres acteurs et ceux produits par `label-Maker` ou `geolabel-maker` montrent qu'il est difficile d'obtenir un jeu de données de très haute qualité. Les différents jeux de données mettent en évidence les limites de précision de la labellisation, c'est à dire la précision de la correspondance entre l'emplacement du bâtiment sur l'image et son label. En effet, il est observé un décalage entre l'image et son label pour certains couples (image, label). De même, si la labellisation des données de l'Inria semble mettre des structures ou partie de structures, celle de `label-Maker`, en revanche, parait englober des éléments qui ne devraient pas l'être. La même chose a pu être observée avec les données ouvertes de la Métropole de Lyon. Ceci peut s'expliquer par un décalage temporel entre l'édition du cadastre et la prise de l'image : il peut y avoir des problèmes de correspondance entre l'image et son label associé liés à la construction ou destruction de bâtiments par exemple.
Au delà de la précision de labellisation, la **qualité de l'image** peut varier d'un jeu de données à l'autre et peut donc aussi influencer la qualité du modèle. En effet, la résolution des images peut varier d'un jeu de données à l'autre, les images peuvent être plus ou moins nettes. Des paramètres tels que la luminosité, le contraste ou la saturation sont susceptibles aussi de dégrader la qualité du jeu de données. De même, des effets apparaissant sur l'image, tels que des effets d'ombre et de lumière peuvent diminuer la qualité de la photographie et possiblement nuire à son traitement par le modèle.
Exemples des problèmes évoqués dans la combinaison (image, label) :
- Omission d'une partie d'un bâtiment dans le label : (données `label-maker` ici)
- Prise en compte de la façade du bâtiment dans le label : (données Inria ici)
- Partie de bâtiment non référencée : (données Open Data Lyon, couple image/label généré par `geolabel-maker`)

- Point lumineux : (données Open Data Lyon, couple image/label généré par `geolabel_maker`)

Conclusion
L'acquisition et la préparation des données sont des étapes importantes et de ces étapes dépendent la qualité du modèle qui sera entraîné. Que ces données soient obtenues de vérité terrain déjà prête à l'emploi ou générées via différents outils, dont la bibliothèque geolabel_maker présentée ici, elles peuvent montrer certaines limitations dans le cadre de problématiques liées à la cartographie. Ces limitations peuvent être les suivantes : un jeu de données très spécifique quant à une région géographique ou un style architecturale ce qui rendrait le modèle de détection et/ou segmentation très spécialisé ; une imprécision de la labellisation tels que des omissions d'éléments ou des décalages ce qui entraînera le modèle sur des données fausses ; la qualité en elle-même des images qui peut nuire à la détection des éléments ciblés.
Notre vérité terrain étant désormais prête, la prochaine étape est donc le choix du modèle et son entraînement. Nous vous en parlerons dans notre prochain article sur ce sujet.
Si vous souhaitez prolonger ces travaux avec nous dans le cadre d'un stage ou apprendre à construire ce type de jeu de données, n'hésitez pas à nous contacter!

Responsable Innovation
Formations associées
Formations IA / Data Science
Formation Mise en place de projets Deep Learning avec Keras
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation Mise en place de projets Deep Learning avec KerasFormations SIG / Cartographie
Formation Leaflet
Nantes - Toulouse - Paris ou distanciel A la demande
Voir la Formation LeafletActualités en lien
Deep clustering d'images aériennes
Data Science
09/02/2021
Cet article présente Deep Cluster, une méthode reposant sur l'utilisation conjointe d'un algorithme de clustering et d'un réseau de neurones (deep learning). Nous montrons que Deep Cluster réussit à grouper en ensembles cohérents des photographies aériennes récupérées via l'API Mapbox. Grâce à l'outil MLflow nous avons tracé et analysé les résultats obtenus par la méthode Deep Cluster. Dans cette publication nous donnerons quelques précisions sur l'utilisation de cet outil.

Extraction d'objets pour la cartographie par deep-learning : évaluation du modèle
Data Science
08/06/2020
Voici le dernier article de notre série sur la cartographie par deep-learning. Après avoir expliqué comment choisir et utiliser un modèle d'extraction d'objets, nous allons maintenant en évaluer les performances. Que pouvons-nous attendre du modèle entraîné ? Quels sont ses limites et ses sensibilités ?

Extraction d'objets pour la cartographie par deep-learning : choix du modèle
SIG
02/06/2020
Deuxième article de la série sur la cartographie par deep-learning à partir d'images aériennes ou satellitaires.
